 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Automatic Online Hate Speech Detection in Low-Resource Languages
Nov 28, 2024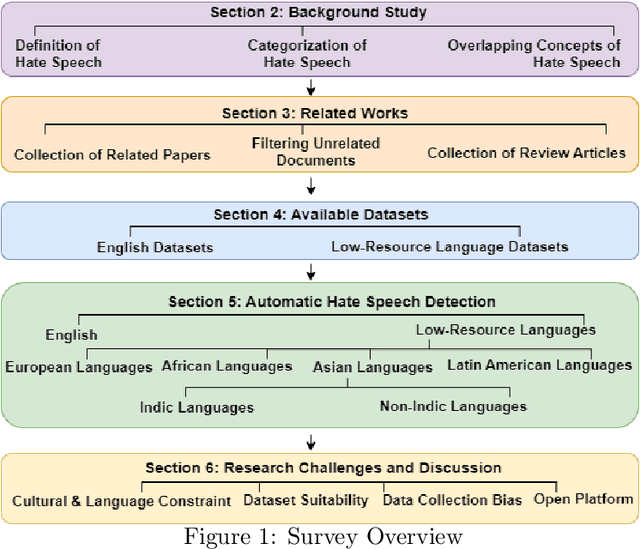
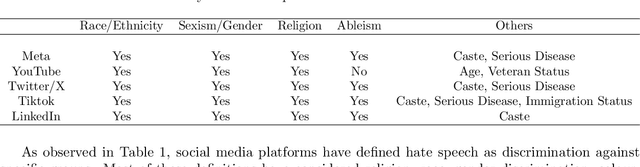
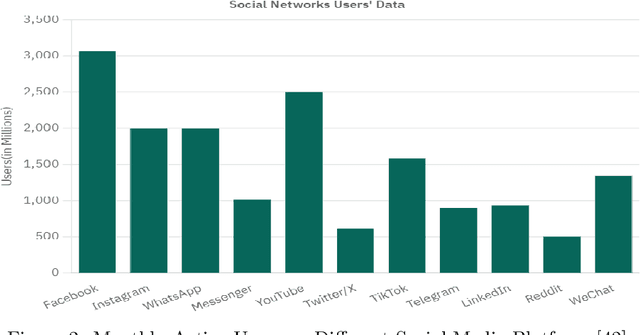
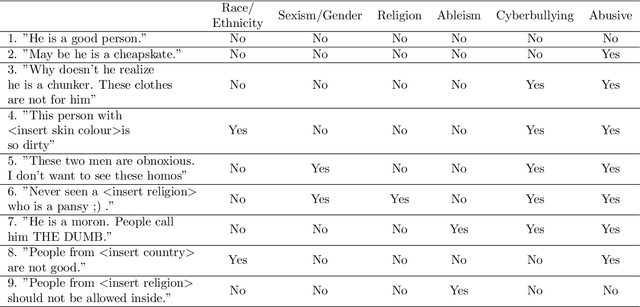
The expanding influence of social media platforms over the past decade has impacted the way people communicate. The level of obscurity provided by social media and easy accessibility of the internet has facilitated the spread of hate speech. The terms and expressions related to hate speech gets updated with changing times which poses an obstacle to policy-makers and researchers in case of hate speech identification. With growing number of individuals using their native languages to communicate with each other, hate speech in these low-resource languages are also growing. Although, there is awareness about the English-related approaches, much attention have not been provided to these low-resource languages due to lack of datasets and online available data. This article provides a detailed survey of hate speech detection in low-resource languages around the world with details of available datasets, features utilized and techniques used. This survey further discusses the prevailing surveys, overlapping concepts related to hate speech, research challenges and opportunities.
PathologyBERT -- Pre-trained Vs. A New Transformer Language Model for Pathology Domain
May 13, 2022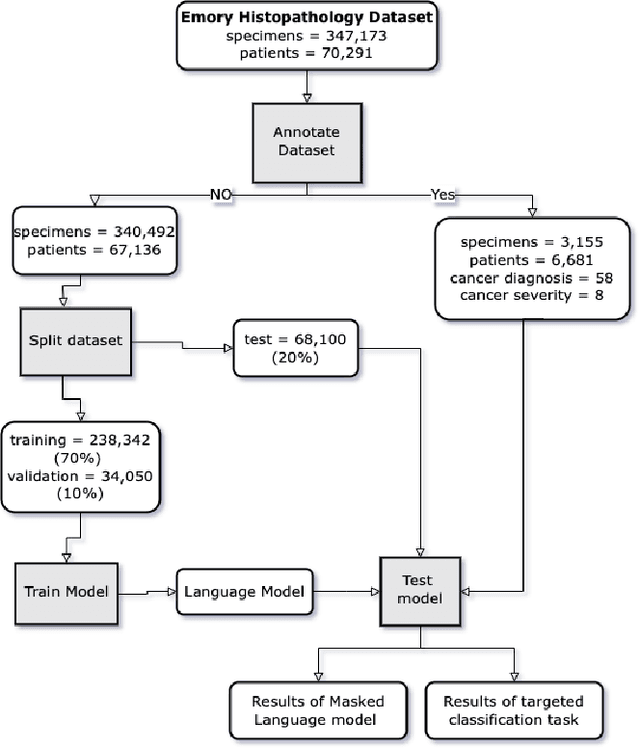

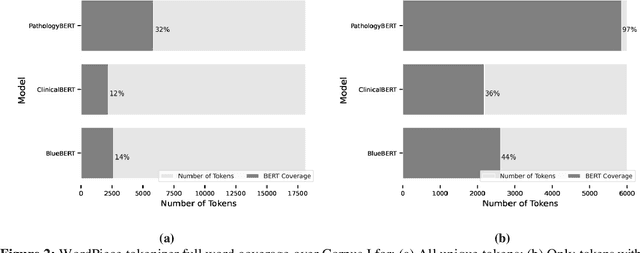
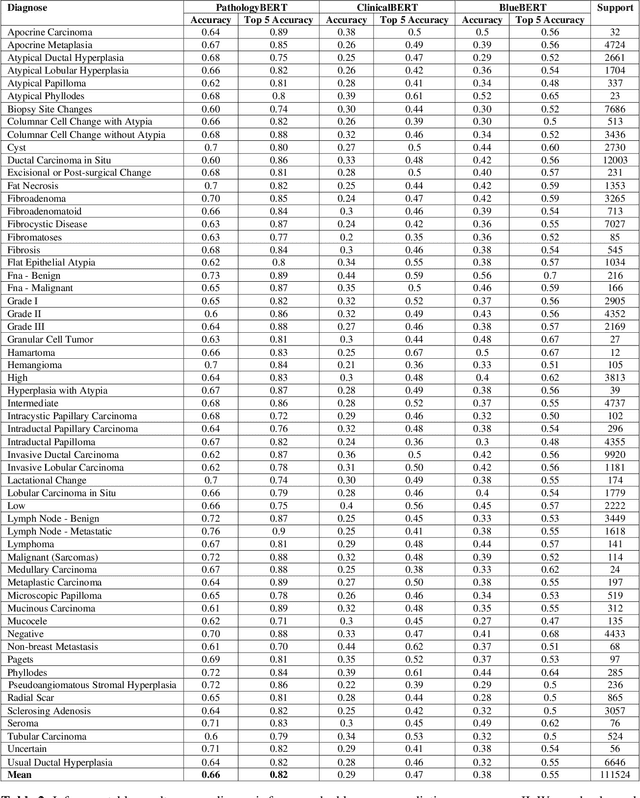
Pathology text mining is a challenging task given the reporting variability and constant new findings in cancer sub-type definitions. However, successful text mining of a large pathology database can play a critical role to advance 'big data' cancer research like similarity-based treatment selection, case identification, prognostication, surveillance, clinical trial screening, risk stratification, and many others. While there is a growing interest in developing language models for more specific clinical domains, no pathology-specific language space exist to support the rapid data-mining development in pathology space. In literature, a few approaches fine-tuned general transformer models on specialized corpora while maintaining the original tokenizer, but in fields requiring specialized terminology, these models often fail to perform adequately. We propose PathologyBERT - a pre-trained masked language model which was trained on 347,173 histopathology specimen reports and publicly released in the Huggingface repository. Our comprehensive experiments demonstrate that pre-training of transformer model on pathology corpora yields performance improvements on Natural Language Understanding (NLU) and Breast Cancer Diagnose Classification when compared to nonspecific language models.