 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion is not one-size-fits-all: Cross-Modal Representation Alignment for Time-to-Event Modeling
Jun 13, 2026Accurate time-to-event (TTE) prediction from multimodal clinical data remains challenging due to modality imbalance and distribution shift. We introduce a foundation model-driven framework for cross-modal representation alignment between CT imaging and longitudinal EHR data, designed to generalize across tasks and institutions. CT and EHR modalities are encoded independently using domain-specific foundation models and aligned in a shared latent space through four principled fusion strategies: late fusion, contrastive alignment, cross-attention, and co-attention. We evaluate two clinically distinct TTE tasks: pulmonary embolism (PE) mortality and cardiovascular disease (CVD) outcomes, on large-scale multi-institutional cohorts (PE: N=3,099 train; 1,098 internal; 435 external; CVD: N=2,951 train; 837 internal; 682 external). Fusion consistently improves concordance index by 1.5-5.4% over unimodal baselines when modalities contribute comparably. Overall, contrastive multimodal fusion, particularly with CLMBR representations, provided the most consistent and statistically robust improvements, especially for PE mortality prediction. For MACE, cross-attention (one-hot) achieved the highest internal performance and image-guided co-attention achieved the best external performance. We therefore introduce a generalizable foundation model-based cross-modal alignment framework and provide the first systematic analysis of fusion behavior under modality imbalance in TTE prediction. Our results establish task-aware multimodal alignment as a necessary design principle for robust generalization and scalable clinical deployment.
Model-based Bootstrap of Controlled Markov Chains
May 12, 2026We propose and analyze a model-based bootstrap for transition kernels in finite controlled Markov chains (CMCs) with possibly nonstationary or history-dependent control policies, a setting that arises naturally in offline reinforcement learning (RL) when the behavior policy generating the data is unknown. We establish distributional consistency of the bootstrap transition estimator in both a single long-chain regime and the episodic offline RL regime. The key technical tools are a novel bootstrap law of large numbers (LLN) for the visitation counts and a novel use of the martingale central limit theorem (CLT) for the bootstrap transition increments. We extend bootstrap distributional consistency to the downstream targets of offline policy evaluation (OPE) and optimal policy recovery (OPR) via the delta method by verifying Hadamard differentiability of the Bellman operators, yielding asymptotically valid confidence intervals for value and $Q$-functions. Experiments on the RiverSwim problem show that the proposed bootstrap confidence intervals (CIs), especially the percentile CIs, outperform the episodic bootstrap and plug-in CLT CIs, and are often close to nominal ($50\%$, $90\%$, $95\%$) coverage, while the baselines are poorly calibrated at small sample sizes and short episode lengths.
Adaptive Estimation and Optimal Control in Offline Contextual MDPs without Stationarity
May 05, 2026Contextual MDPs are powerful tools with wide applicability in areas from biostatistics to machine learning. However, specializing them to offline datasets has been challenging due to a lack of robust, theoretically backed methods. Our work tackles this problem by introducing a new approach towards adaptive estimation and cost optimization of contextual MDPs. This estimator, to the best of our knowledge, is the first of its kind, and is endowed with strong optimality guarantees. We achieve this by overcoming the key technical challenges evolving from the endogenous properties of contextual MDPs; such as non-stationarity, or model irregularity. Our guarantees are established under complete generality by utilizing the relatively recent and powerful statistical technique of $T$-estimation (Baraud, 2011). We first provide a procedure for selecting an estimator given a sample from a contextual MDP and use it to derive oracle risk bounds under two distinct, but nevertheless meaningful, loss functions. We then consider the problem of determining the optimal control with the aid of the aforementioned density estimate and provide finite sample guarantees for the cost function.
Feature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025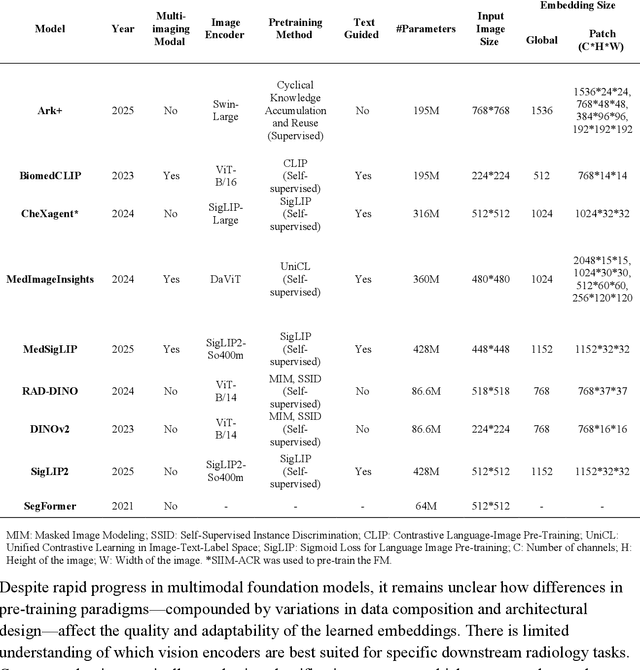
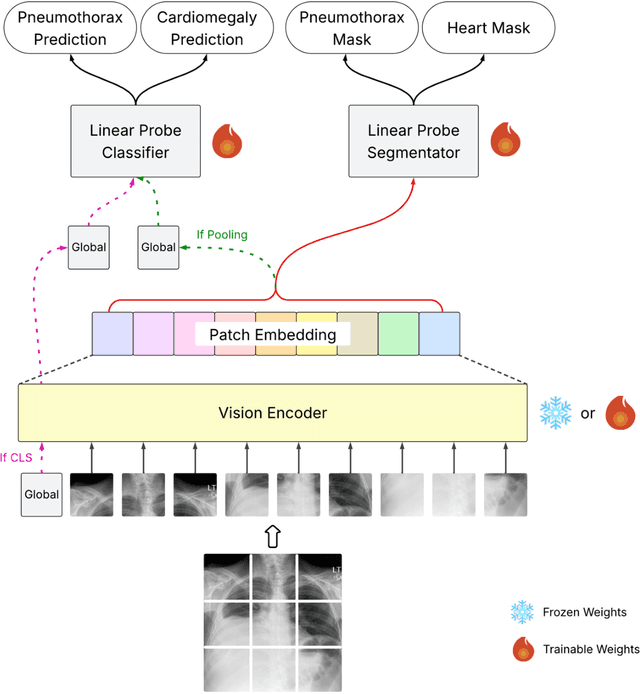
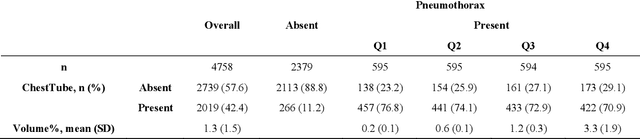
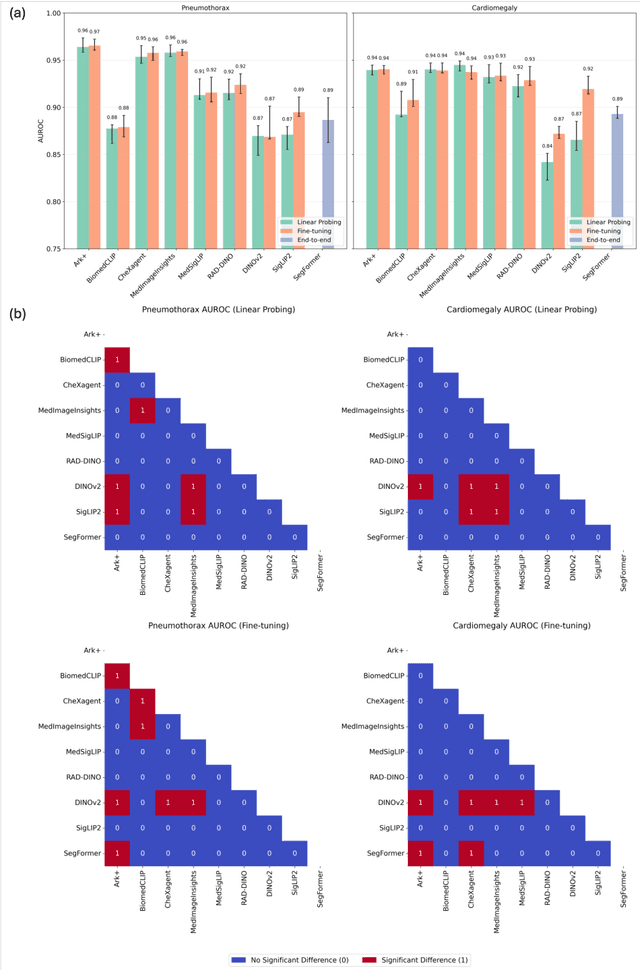
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
MOSCARD -- Causal Reasoning and De-confounding for Multimodal Opportunistic Screening of Cardiovascular Adverse Events
Jun 23, 2025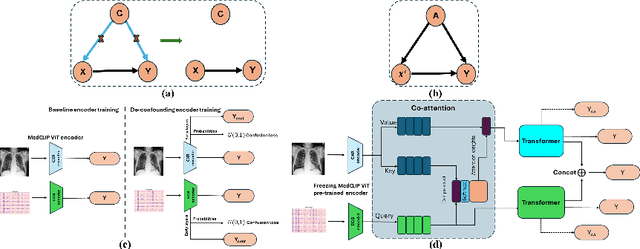
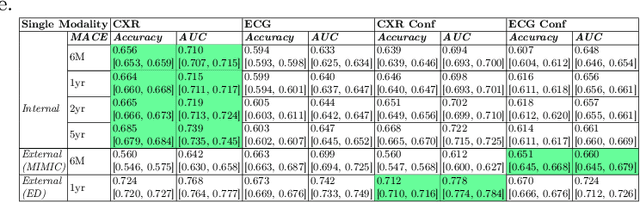


Major Adverse Cardiovascular Events (MACE) remain the leading cause of mortality globally, as reported in the Global Disease Burden Study 2021. Opportunistic screening leverages data collected from routine health check-ups and multimodal data can play a key role to identify at-risk individuals. Chest X-rays (CXR) provide insights into chronic conditions contributing to major adverse cardiovascular events (MACE), while 12-lead electrocardiogram (ECG) directly assesses cardiac electrical activity and structural abnormalities. Integrating CXR and ECG could offer a more comprehensive risk assessment than conventional models, which rely on clinical scores, computed tomography (CT) measurements, or biomarkers, which may be limited by sampling bias and single modality constraints. We propose a novel predictive modeling framework - MOSCARD, multimodal causal reasoning with co-attention to align two distinct modalities and simultaneously mitigate bias and confounders in opportunistic risk estimation. Primary technical contributions are - (i) multimodal alignment of CXR with ECG guidance; (ii) integration of causal reasoning; (iii) dual back-propagation graph for de-confounding. Evaluated on internal, shift data from emergency department (ED) and external MIMIC datasets, our model outperformed single modality and state-of-the-art foundational models - AUC: 0.75, 0.83, 0.71 respectively. Proposed cost-effective opportunistic screening enables early intervention, improving patient outcomes and reducing disparities.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
CLT and Edgeworth Expansion for m-out-of-n Bootstrap Estimators of The Studentized Median
May 16, 2025The m-out-of-n bootstrap, originally proposed by Bickel, Gotze, and Zwet (1992), approximates the distribution of a statistic by repeatedly drawing m subsamples (with m much smaller than n) without replacement from an original sample of size n. It is now routinely used for robust inference with heavy-tailed data, bandwidth selection, and other large-sample applications. Despite its broad applicability across econometrics, biostatistics, and machine learning, rigorous parameter-free guarantees for the soundness of the m-out-of-n bootstrap when estimating sample quantiles have remained elusive. This paper establishes such guarantees by analyzing the estimator of sample quantiles obtained from m-out-of-n resampling of a dataset of size n. We first prove a central limit theorem for a fully data-driven version of the estimator that holds under a mild moment condition and involves no unknown nuisance parameters. We then show that the moment assumption is essentially tight by constructing a counter-example in which the CLT fails. Strengthening the assumptions slightly, we derive an Edgeworth expansion that provides exact convergence rates and, as a corollary, a Berry Esseen bound on the bootstrap approximation error. Finally, we illustrate the scope of our results by deriving parameter-free asymptotic distributions for practical statistics, including the quantiles for random walk Metropolis-Hastings and the rewards of ergodic Markov decision processes, thereby demonstrating the usefulness of our theory in modern estimation and learning tasks.
Position: Restructuring of Categories and Implementation of Guidelines Essential for VLM Adoption in Healthcare
May 12, 2025The intricate and multifaceted nature of vision language model (VLM) development, adaptation, and application necessitates the establishment of clear and standardized reporting protocols, particularly within the high-stakes context of healthcare. Defining these reporting standards is inherently challenging due to the diverse nature of studies involving VLMs, which vary significantly from the development of all new VLMs or finetuning for domain alignment to off-the-shelf use of VLM for targeted diagnosis and prediction tasks. In this position paper, we argue that traditional machine learning reporting standards and evaluation guidelines must be restructured to accommodate multiphase VLM studies; it also has to be organized for intuitive understanding of developers while maintaining rigorous standards for reproducibility. To facilitate community adoption, we propose a categorization framework for VLM studies and outline corresponding reporting standards that comprehensively address performance evaluation, data reporting protocols, and recommendations for manuscript composition. These guidelines are organized according to the proposed categorization scheme. Lastly, we present a checklist that consolidates reporting standards, offering a standardized tool to ensure consistency and quality in the publication of VLM-related research.
Opportunistic Screening for Pancreatic Cancer using Computed Tomography Imaging and Radiology Reports
Mar 31, 2025Pancreatic ductal adenocarcinoma (PDAC) is a highly aggressive cancer, with most cases diagnosed at stage IV and a five-year overall survival rate below 5%. Early detection and prognosis modeling are crucial for improving patient outcomes and guiding early intervention strategies. In this study, we developed and evaluated a deep learning fusion model that integrates radiology reports and CT imaging to predict PDAC risk. The model achieved a concordance index (C-index) of 0.6750 (95% CI: 0.6429, 0.7121) and 0.6435 (95% CI: 0.6055, 0.6789) on the internal and external dataset, respectively, for 5-year survival risk estimation. Kaplan-Meier analysis demonstrated significant separation (p<0.0001) between the low and high risk groups predicted by the fusion model. These findings highlight the potential of deep learning-based survival models in leveraging clinical and imaging data for pancreatic cancer.
Novel AI-Based Quantification of Breast Arterial Calcification to Predict Cardiovascular Risk
Mar 17, 2025



Women are underdiagnosed and undertreated for cardiovascular disease. Automatic quantification of breast arterial calcification on screening mammography can identify women at risk for cardiovascular disease and enable earlier treatment and management of disease. In this retrospective study of 116,135 women from two healthcare systems, a transformer-based neural network quantified BAC severity (no BAC, mild, moderate, and severe) on screening mammograms. Outcomes included major adverse cardiovascular events (MACE) and all-cause mortality. BAC severity was independently associated with MACE after adjusting for cardiovascular risk factors, with increasing hazard ratios from mild (HR 1.18-1.22), moderate (HR 1.38-1.47), to severe BAC (HR 2.03-2.22) across datasets (all p<0.001). This association remained significant across all age groups, with even mild BAC indicating increased risk in women under 50. BAC remained an independent predictor when analyzed alongside ASCVD risk scores, showing significant associations with myocardial infarction, stroke, heart failure, and mortality (all p<0.005). Automated BAC quantification enables opportunistic cardiovascular risk assessment during routine mammography without additional radiation or cost. This approach provides value beyond traditional risk factors, particularly in younger women, offering potential for early CVD risk stratification in the millions of women undergoing annual mammography.