 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Ultrasound Foundation Models for Fetal Plane Classification
May 27, 2026Ultrasound is widely used in obstetric care due to its safety, accessibility, and real-time imaging. However, interpretation remains operator-dependent and susceptible to noise and artifacts. Deep learning models have shown strong performance to solve these problem, but they typically require large annotated datasets that are difficult to obtain in clinical ultrasound. Foundation models (FMs) offer an alternative, using a large number of ultrasound images to learn transferable representations that can generalize with limited labeled data. This work presents a comprehensive benchmark of ultrasound-specific FMs for fetal plane classification. We evaluated four ultrasound FMs (USFM, MOFO, UltraSAM, FetalCLIP) against two CNN baselines (ResNet50, EfficientNet-V2) and a ViT (DINOv3) pretrained on natural images. We trained all models under two complementary settings: full fine-tuning and linear probing with a frozen encoder. All models were trained using 5-fold patient-level cross-validation on a Spanish fetal ultrasound dataset and tested on both in-domain data and an external African cohort to assess cross-population generalization. We found that FetalCLIP achieved the best results in the linear probing setting (F1 = 0.9261 for in-domain, F1 = 0.9731 for out-of-domain), while USFM performed best in the full fine-tuning setting (F1 = 0.9476 for in-domain, F1 = 0.9515 for out-of-domain). MOFO and UltraSAM degraded most in both settings, underperforming natural image pretrained models in some cases. These findings highlight how the choice of pretrained model strongly affects fetal plane classification performance, since different pretraining objectives lead to different levels of transferability.
BioFact-MoE: Biologically Factorized Mixture of Experts for Vision-Language Prognostic Modeling in Hepatocellular Carcinoma
May 25, 2026Hepatocellular carcinoma (HCC) is biologically heterogeneous, shaped by the interplay between hepatic functional reserve and tumor-related oncologic factors; thus, similar survival outcomes may reflect fundamentally different underlying biological processes. Prognostic modeling in HCC is informed by rich multimodal information from multiparametric MRI and radiology reports from routine clinical practice. Existing prognostic vision-language models (VLMs) learn a single entangled latent representation that blends hepatic and tumor-related factors, limiting both accuracy and biological interpretability. We present BioFact-MoE, a biologically factorized Mixture of Experts (MoE) framework that explicitly decomposes liver and tumor factors via biologically supervised experts within a residual MoE survival architecture. On a HCC cohort of N=588 patients (pretrained on 4,582 3D MRI image-report pairs), BioFact-MoE consistently improves survival prediction over all baselines across time horizons, achieving 12-, 18-, and 24-month AUCs of 75.33%, 75.85%, and 73.96%. Beyond scalar risk prediction, gated expert weights enable phenotype-aware risk stratification. Pathway-informed gating uncovers clinically meaningful treatment-associated survival heterogeneity. In held-out validation, hepatic and tumor embeddings show selective associations with liver function and tumor burden markers, respectively (p<0.05), without supervision. The code is available at https://github.com/jy-639/BioFact-MoE.
DECADE: A Temporally-Consistent Unsupervised Diffusion Model for Enhanced Rb-82 Dynamic Cardiac PET Image Denoising
Mar 08, 2026Rb-82 dynamic cardiac PET imaging is widely used for the clinical diagnosis of coronary artery disease (CAD), but its short half-life results in high noise levels that degrade dynamic frame quality and parametric imaging. The lack of paired clean-noisy training data, rapid tracer kinetics, and frame-dependent noise variations further limit the effectiveness of existing deep learning denoising methods. We propose DECADE (A Temporally-Consistent Unsupervised Diffusion model for Enhanced Rb-82 CArdiac PET DEnoising), an unsupervised diffusion framework that generalizes across early- to late-phase dynamic frames. DECADE incorporates temporal consistency during both training and iterative sampling, using noisy frames as guidance to preserve quantitative accuracy. The method was trained and evaluated on datasets acquired from Siemens Vision 450 and Siemens Biograph Vision Quadra scanners. On the Vision 450 dataset, DECADE consistently produced high-quality dynamic and parametric images with reduced noise while preserving myocardial blood flow (MBF) and myocardial flow reserve (MFR). On the Quadra dataset, using 15%-count images as input and full-count images as reference, DECADE outperformed UNet-based and other diffusion models in image quality and K1/MBF quantification. The proposed framework enables effective unsupervised denoising of Rb-82 dynamic cardiac PET without paired training data, supporting clearer visualization while maintaining quantitative integrity.
CARE: Towards Clinical Accountability in Multi-Modal Medical Reasoning with an Evidence-Grounded Agentic Framework
Mar 02, 2026Large visual language models (VLMs) have shown strong multi-modal medical reasoning ability, but most operate as end-to-end black boxes, diverging from clinicians' evidence-based, staged workflows and hindering clinical accountability. Complementarily, expert visual grounding models can accurately localize regions of interest (ROIs), providing explicit, reliable evidence that improves both reasoning accuracy and trust. In this paper, we introduce CARE, advancing Clinical Accountability in multi-modal medical Reasoning with an Evidence-grounded agentic framework. Unlike existing approaches that couple grounding and reasoning within a single generalist model, CARE decomposes the task into coordinated sub-modules to reduce shortcut learning and hallucination: a compact VLM proposes relevant medical entities; an expert entity-referring segmentation model produces pixel-level ROI evidence; and a grounded VLM reasons over the full image augmented by ROI hints. The VLMs are optimized with reinforcement learning with verifiable rewards to align answers with supporting evidence. Furthermore, a VLM coordinator plans tool invocation and reviews evidence-answer consistency, providing agentic control and final verification. Evaluated on standard medical VQA benchmarks, our CARE-Flow (coordinator-free) improves average accuracy by 10.9% over the same size (10B) state-of-the-art (SOTA). With dynamic planning and answer review, our CARE-Coord yields a further gain, outperforming the heavily pre-trained SOTA by 5.2%. Our experiments demonstrate that an agentic framework that emulates clinical workflows, incorporating decoupled specialized models and explicit evidence, yields more accurate and accountable medical AI.
Equi-ViT: Rotational Equivariant Vision Transformer for Robust Histopathology Analysis
Jan 14, 2026Vision Transformers (ViTs) have gained rapid adoption in computational pathology for their ability to model long-range dependencies through self-attention, addressing the limitations of convolutional neural networks that excel at local pattern capture but struggle with global contextual reasoning. Recent pathology-specific foundation models have further advanced performance by leveraging large-scale pretraining. However, standard ViTs remain inherently non-equivariant to transformations such as rotations and reflections, which are ubiquitous variations in histopathology imaging. To address this limitation, we propose Equi-ViT, which integrates an equivariant convolution kernel into the patch embedding stage of a ViT architecture, imparting built-in rotational equivariance to learned representations. Equi-ViT achieves superior rotation-consistent patch embeddings and stable classification performance across image orientations. Our results on a public colorectal cancer dataset demonstrate that incorporating equivariant patch embedding enhances data efficiency and robustness, suggesting that equivariant transformers could potentially serve as more generalizable backbones for the application of ViT in histopathology, such as digital pathology foundation models.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Equivariant Imaging Biomarkers for Robust Unsupervised Segmentation of Histopathology
May 08, 2025Histopathology evaluation of tissue specimens through microscopic examination is essential for accurate disease diagnosis and prognosis. However, traditional manual analysis by specially trained pathologists is time-consuming, labor-intensive, cost-inefficient, and prone to inter-rater variability, potentially affecting diagnostic consistency and accuracy. As digital pathology images continue to proliferate, there is a pressing need for automated analysis to address these challenges. Recent advancements in artificial intelligence-based tools such as machine learning (ML) models, have significantly enhanced the precision and efficiency of analyzing histopathological slides. However, despite their impressive performance, ML models are invariant only to translation, lacking invariance to rotation and reflection. This limitation restricts their ability to generalize effectively, particularly in histopathology, where images intrinsically lack meaningful orientation. In this study, we develop robust, equivariant histopathological biomarkers through a novel symmetric convolutional kernel via unsupervised segmentation. The approach is validated using prostate tissue micro-array (TMA) images from 50 patients in the Gleason 2019 Challenge public dataset. The biomarkers extracted through this approach demonstrate enhanced robustness and generalizability against rotation compared to models using standard convolution kernels, holding promise for enhancing the accuracy, consistency, and robustness of ML models in digital pathology. Ultimately, this work aims to improve diagnostic and prognostic capabilities of histopathology beyond prostate cancer through equivariant imaging.
GMR-Conv: An Efficient Rotation and Reflection Equivariant Convolution Kernel Using Gaussian Mixture Rings
Apr 03, 2025Symmetry, where certain features remain invariant under geometric transformations, can often serve as a powerful prior in designing convolutional neural networks (CNNs). While conventional CNNs inherently support translational equivariance, extending this property to rotation and reflection has proven challenging, often forcing a compromise between equivariance, efficiency, and information loss. In this work, we introduce Gaussian Mixture Ring Convolution (GMR-Conv), an efficient convolution kernel that smooths radial symmetry using a mixture of Gaussian-weighted rings. This design mitigates discretization errors of circular kernels, thereby preserving robust rotation and reflection equivariance without incurring computational overhead. We further optimize both the space and speed efficiency of GMR-Conv via a novel parameterization and computation strategy, allowing larger kernels at an acceptable cost. Extensive experiments on eight classification and one segmentation datasets demonstrate that GMR-Conv not only matches conventional CNNs' performance but can also surpass it in applications with orientation-less data. GMR-Conv is also proven to be more robust and efficient than the state-of-the-art equivariant learning methods. Our work provides inspiring empirical evidence that carefully applied radial symmetry can alleviate the challenges of information loss, marking a promising advance in equivariant network architectures. The code is available at https://github.com/XYPB/GMR-Conv.
Improved Vessel Segmentation with Symmetric Rotation-Equivariant U-Net
Jan 24, 2025Automated segmentation plays a pivotal role in medical image analysis and computer-assisted interventions. Despite the promising performance of existing methods based on convolutional neural networks (CNNs), they neglect useful equivariant properties for images, such as rotational and reflection equivariance. This limitation can decrease performance and lead to inconsistent predictions, especially in applications like vessel segmentation where explicit orientation is absent. While existing equivariant learning approaches attempt to mitigate these issues, they substantially increase learning cost, model size, or both. To overcome these challenges, we propose a novel application of an efficient symmetric rotation-equivariant (SRE) convolutional (SRE-Conv) kernel implementation to the U-Net architecture, to learn rotation and reflection-equivariant features, while also reducing the model size dramatically. We validate the effectiveness of our method through improved segmentation performance on retina vessel fundus imaging. Our proposed SRE U-Net not only significantly surpasses standard U-Net in handling rotated images, but also outperforms existing equivariant learning methods and does so with a reduced number of trainable parameters and smaller memory cost. The code is available at https://github.com/OnofreyLab/sre_conv_segm_isbi2025.
SRE-Conv: Symmetric Rotation Equivariant Convolution for Biomedical Image Classification
Jan 16, 2025
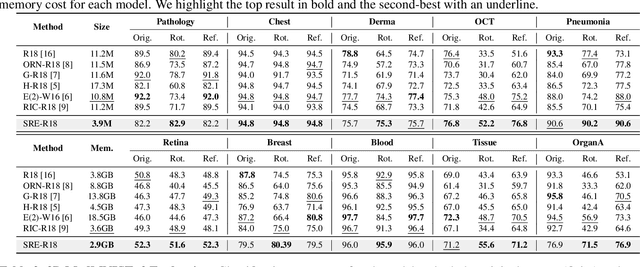

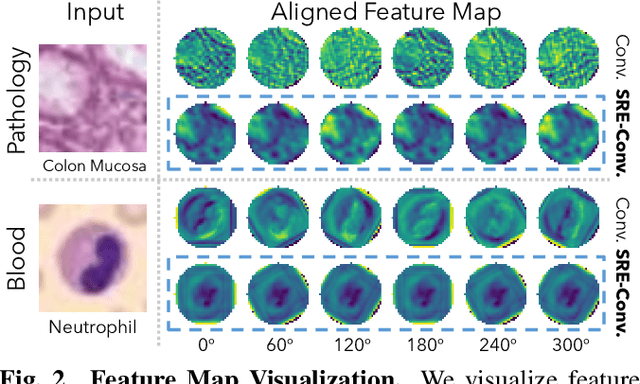
Convolutional neural networks (CNNs) are essential tools for computer vision tasks, but they lack traditionally desired properties of extracted features that could further improve model performance, e.g., rotational equivariance. Such properties are ubiquitous in biomedical images, which often lack explicit orientation. While current work largely relies on data augmentation or explicit modules to capture orientation information, this comes at the expense of increased training costs or ineffective approximations of the desired equivariance. To overcome these challenges, we propose a novel and efficient implementation of the Symmetric Rotation-Equivariant (SRE) Convolution (SRE-Conv) kernel, designed to learn rotation-invariant features while simultaneously compressing the model size. The SRE-Conv kernel can easily be incorporated into any CNN backbone. We validate the ability of a deep SRE-CNN to capture equivariance to rotation using the public MedMNISTv2 dataset (16 total tasks). SRE-Conv-CNN demonstrated improved rotated image classification performance accuracy on all 16 test datasets in both 2D and 3D images, all while increasing efficiency with fewer parameters and reduced memory footprint. The code is available at https://github.com/XYPB/SRE-Conv.