 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEFT: Language-Image Contrastive Learning with Efficient Large Language Model and Prompt Fine-Tuning
Jul 30, 2024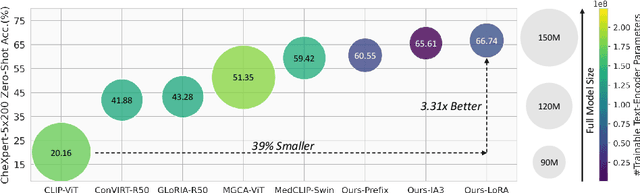
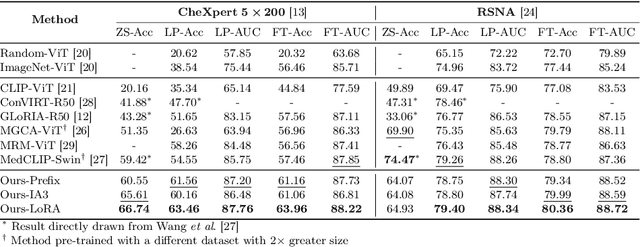
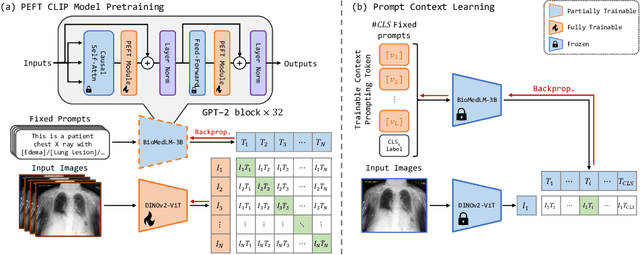
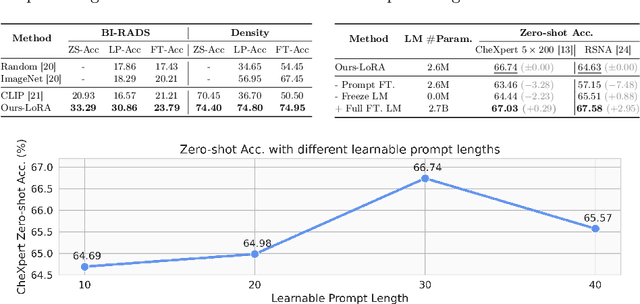
Recent advancements in Contrastive Language-Image Pre-training (CLIP) have demonstrated notable success in self-supervised representation learning across various tasks. However, the existing CLIP-like approaches often demand extensive GPU resources and prolonged training times due to the considerable size of the model and dataset, making them poor for medical applications, in which large datasets are not always common. Meanwhile, the language model prompts are mainly manually derived from labels tied to images, potentially overlooking the richness of information within training samples. We introduce a novel language-image Contrastive Learning method with an Efficient large language model and prompt Fine-Tuning (CLEFT) that harnesses the strengths of the extensive pre-trained language and visual models. Furthermore, we present an efficient strategy for learning context-based prompts that mitigates the gap between informative clinical diagnostic data and simple class labels. Our method demonstrates state-of-the-art performance on multiple chest X-ray and mammography datasets compared with various baselines. The proposed parameter efficient framework can reduce the total trainable model size by 39% and reduce the trainable language model to only 4% compared with the current BERT encoder.