 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMedVision: Multi-Modal Medical Vision Framework
May 09, 2026Multi-modal medical imaging enables comprehensive diagnostics, yet current foundation models process 2D (e.g. X-ray) and 3D (e.g. CT) data with separate, dimensionality-specific architectures. We present MultiMedVision, a unified framework for joint 2D/3D representation learning built on a Sparse Vision Transformer. Our model uses 3D Rotary Positional Embeddings and variable-length sequence packing to process mixed-modality batches natively within a shared latent space, without modality-specific adapters or treating 3D volumes as 2D slice sequences. Trained with a self-supervised objective on chest X-rays (MIMIC-CXR) and CT scans (CT-RATE), and using a single shared encoder with 5x less data, MultiMedVision achieves competitive performance on both 2D benchmarks (Macro AUROC 0.82 on MIMIC, 0.84 on CheXpert) and 3D tasks (0.85 on CT-RATE). Analysis of the learned representations reveals coexisting modality-specific and shared feature subspaces, demonstrating that unified cross-dimensional representation learning is feasible without sacrificing modality-specific performance.
DMind-3: A Sovereign Edge--Local--Cloud AI System with Controlled Deliberation and Correction-Based Tuning for Safe, Low-Latency Transaction Execution
Feb 12, 2026This paper introduces DMind-3, a sovereign Edge-Local-Cloud intelligence stack designed to secure irreversible financial execution in Web3 environments against adversarial risks and strict latency constraints. While existing cloud-centric assistants compromise privacy and fail under network congestion, and purely local solutions lack global ecosystem context, DMind-3 resolves these tensions by decomposing capability into three cooperating layers: a deterministic signing-time intent firewall at the edge, a private high-fidelity reasoning engine on user hardware, and a policy-governed global context synthesizer in the cloud. We propose policy-driven selective offloading to route computation based on privacy sensitivity and uncertainty, supported by two novel training objectives: Hierarchical Predictive Synthesis (HPS) for fusing time-varying macro signals, and Contrastive Chain-of-Correction Supervised Fine-Tuning (C$^3$-SFT) to enhance local verification reliability. Extensive evaluations demonstrate that DMind-3 achieves a 93.7% multi-turn success rate in protocol-constrained tasks and superior domain reasoning compared to general-purpose baselines, providing a scalable framework where safety is bound to the edge execution primitive while maintaining sovereignty over sensitive user intent.
Feature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025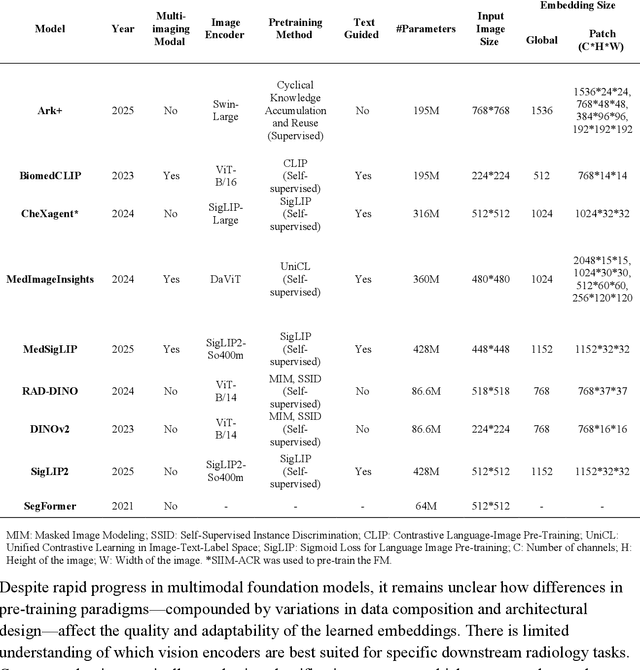
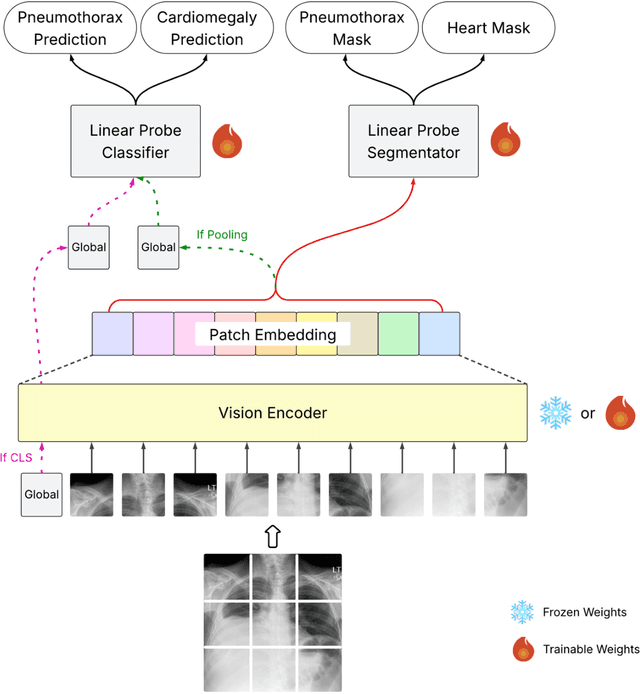
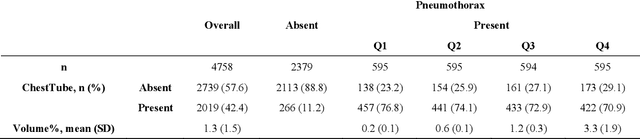
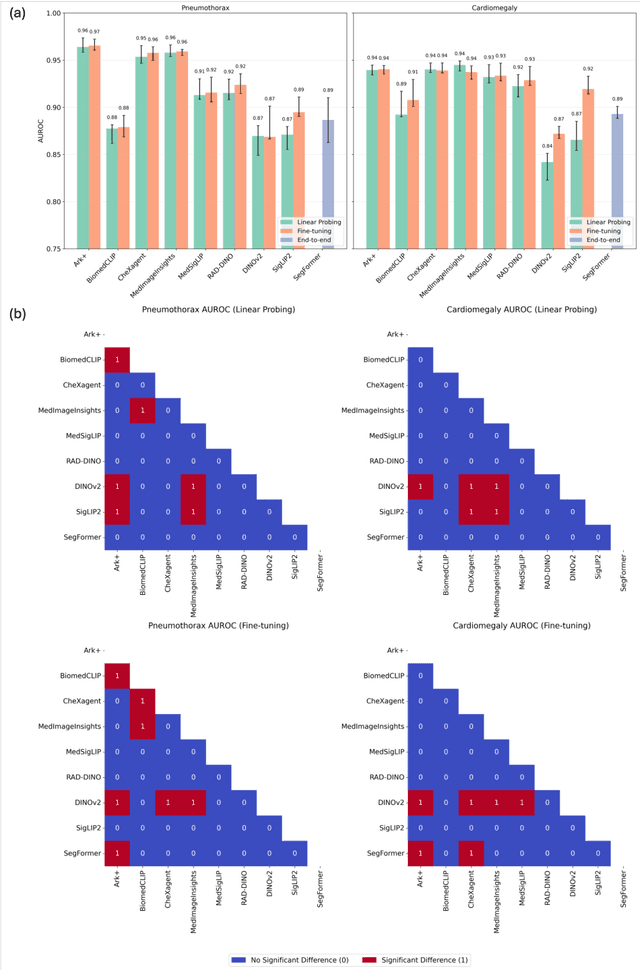
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
Evaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025



Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.
DMind Benchmark: The First Comprehensive Benchmark for LLM Evaluation in the Web3 Domain
Apr 18, 2025
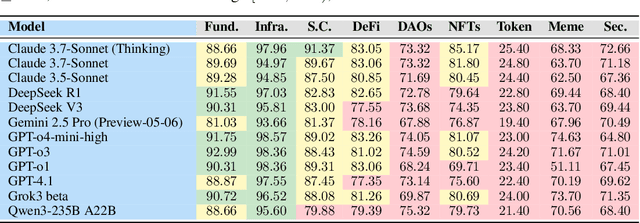
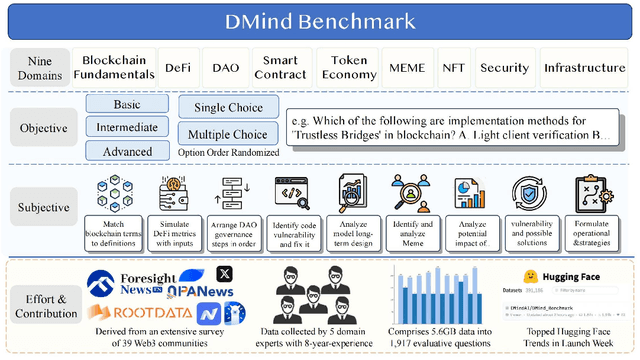
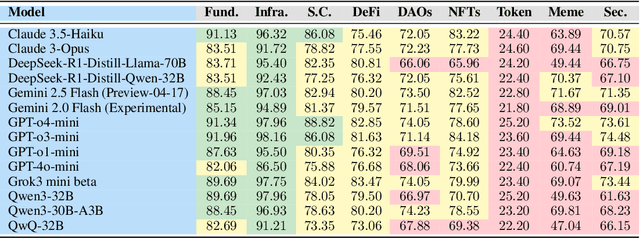
Recent advances in Large Language Models (LLMs) have led to significant progress on a wide range of natural language processing tasks. However, their effectiveness in specialized and rapidly evolving domains such as Web3 remains underexplored. In this paper, we introduce DMind Benchmark, a novel framework that systematically tests LLMs across nine key categories encompassing blockchain fundamentals, infrastructure, smart contract analysis, decentralized finance (DeFi), decentralized autonomous organizations (DAOs), non-fungible tokens (NFTs), token economics, meme concepts, and security vulnerabilities. DMind Benchmark goes beyond conventional multiple-choice questions by incorporating domain-specific subjective tasks (e.g., smart contract code auditing and repair, numeric reasoning on on-chain data, and fill-in assessments), thereby capturing real-world complexities and stress-testing model adaptability. We evaluate fifteen popular LLMs (from ChatGPT, DeepSeek, Claude, and Gemini series) on DMind Benchmark, uncovering performance gaps in Web3-specific reasoning and application, particularly in emerging areas like token economics and meme concepts. Even the strongest models face significant challenges in identifying subtle security vulnerabilities and analyzing complex DeFi mechanisms. To foster progress in this area, we publicly release our benchmark dataset, evaluation pipeline, and annotated results at http://www.dmind.ai, offering a valuable resource for advancing specialized domain adaptation and the development of more robust Web3-enabled LLMs.
Subgroup Performance of a Commercial Digital Breast Tomosynthesis Model for Breast Cancer Detection
Mar 17, 2025While research has established the potential of AI models for mammography to improve breast cancer screening outcomes, there have not been any detailed subgroup evaluations performed to assess the strengths and weaknesses of commercial models for digital breast tomosynthesis (DBT) imaging. This study presents a granular evaluation of the Lunit INSIGHT DBT model on a large retrospective cohort of 163,449 screening mammography exams from the Emory Breast Imaging Dataset (EMBED). Model performance was evaluated in a binary context with various negative exam types (162,081 exams) compared against screen detected cancers (1,368 exams) as the positive class. The analysis was stratified across demographic, imaging, and pathologic subgroups to identify potential disparities. The model achieved an overall AUC of 0.91 (95% CI: 0.90-0.92) with a precision of 0.08 (95% CI: 0.08-0.08), and a recall of 0.73 (95% CI: 0.71-0.76). Performance was found to be robust across demographics, but cases with non-invasive cancers (AUC: 0.85, 95% CI: 0.83-0.87), calcifications (AUC: 0.80, 95% CI: 0.78-0.82), and dense breast tissue (AUC: 0.90, 95% CI: 0.88-0.91) were associated with significantly lower performance compared to other groups. These results highlight the need for detailed evaluation of model characteristics and vigilance in considering adoption of new tools for clinical deployment.
Novel AI-Based Quantification of Breast Arterial Calcification to Predict Cardiovascular Risk
Mar 17, 2025



Women are underdiagnosed and undertreated for cardiovascular disease. Automatic quantification of breast arterial calcification on screening mammography can identify women at risk for cardiovascular disease and enable earlier treatment and management of disease. In this retrospective study of 116,135 women from two healthcare systems, a transformer-based neural network quantified BAC severity (no BAC, mild, moderate, and severe) on screening mammograms. Outcomes included major adverse cardiovascular events (MACE) and all-cause mortality. BAC severity was independently associated with MACE after adjusting for cardiovascular risk factors, with increasing hazard ratios from mild (HR 1.18-1.22), moderate (HR 1.38-1.47), to severe BAC (HR 2.03-2.22) across datasets (all p<0.001). This association remained significant across all age groups, with even mild BAC indicating increased risk in women under 50. BAC remained an independent predictor when analyzed alongside ASCVD risk scores, showing significant associations with myocardial infarction, stroke, heart failure, and mortality (all p<0.005). Automated BAC quantification enables opportunistic cardiovascular risk assessment during routine mammography without additional radiation or cost. This approach provides value beyond traditional risk factors, particularly in younger women, offering potential for early CVD risk stratification in the millions of women undergoing annual mammography.
Identifying Multiple Personalities in Large Language Models with External Evaluation
Feb 22, 2024



As Large Language Models (LLMs) are integrated with human daily applications rapidly, many societal and ethical concerns are raised regarding the behavior of LLMs. One of the ways to comprehend LLMs' behavior is to analyze their personalities. Many recent studies quantify LLMs' personalities using self-assessment tests that are created for humans. Yet many critiques question the applicability and reliability of these self-assessment tests when applied to LLMs. In this paper, we investigate LLM personalities using an alternate personality measurement method, which we refer to as the external evaluation method, where instead of prompting LLMs with multiple-choice questions in the Likert scale, we evaluate LLMs' personalities by analyzing their responses toward open-ended situational questions using an external machine learning model. We first fine-tuned a Llama2-7B model as the MBTI personality predictor that outperforms the state-of-the-art models as the tool to analyze LLMs' responses. Then, we prompt the LLMs with situational questions and ask them to generate Twitter posts and comments, respectively, in order to assess their personalities when playing two different roles. Using the external personality evaluation method, we identify that the obtained personality types for LLMs are significantly different when generating posts versus comments, whereas humans show a consistent personality profile in these two different situations. This shows that LLMs can exhibit different personalities based on different scenarios, thus highlighting a fundamental difference between personality in LLMs and humans. With our work, we call for a re-evaluation of personality definition and measurement in LLMs.
Web Neural Network with Complete DiGraphs
Jan 07, 2024This paper introduces a new neural network model that aims to mimic the biological brain more closely by structuring the network as a complete directed graph that processes continuous data for each timestep. Current neural networks have structures that vaguely mimic the brain structure, such as neurons, convolutions, and recurrence. The model proposed in this paper adds additional structural properties by introducing cycles into the neuron connections and removing the sequential nature commonly seen in other network layers. Furthermore, the model has continuous input and output, inspired by spiking neural networks, which allows the network to learn a process of classification, rather than simply returning the final result.
Synthetically Enhanced: Unveiling Synthetic Data's Potential in Medical Imaging Research
Nov 15, 2023



Chest X-rays (CXR) are the most common medical imaging study and are used to diagnose multiple medical conditions. This study examines the impact of synthetic data supplementation, using diffusion models, on the performance of deep learning (DL) classifiers for CXR analysis. We employed three datasets: CheXpert, MIMIC-CXR, and Emory Chest X-ray, training conditional denoising diffusion probabilistic models (DDPMs) to generate synthetic frontal radiographs. Our approach ensured that synthetic images mirrored the demographic and pathological traits of the original data. Evaluating the classifiers' performance on internal and external datasets revealed that synthetic data supplementation enhances model accuracy, particularly in detecting less prevalent pathologies. Furthermore, models trained on synthetic data alone approached the performance of those trained on real data. This suggests that synthetic data can potentially compensate for real data shortages in training robust DL models. However, despite promising outcomes, the superiority of real data persists.