 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Quality and Adaptability of Medical Foundation Models: A Comparative Evaluation for Radiographic Classification and Segmentation
Nov 12, 2025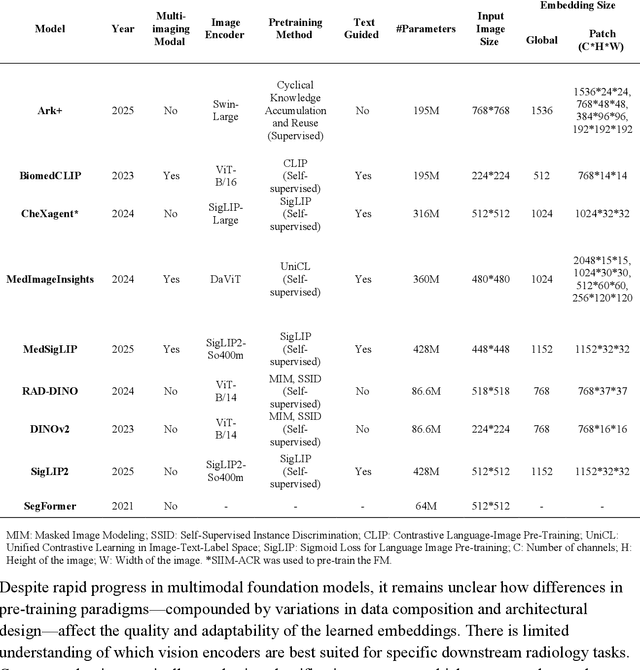
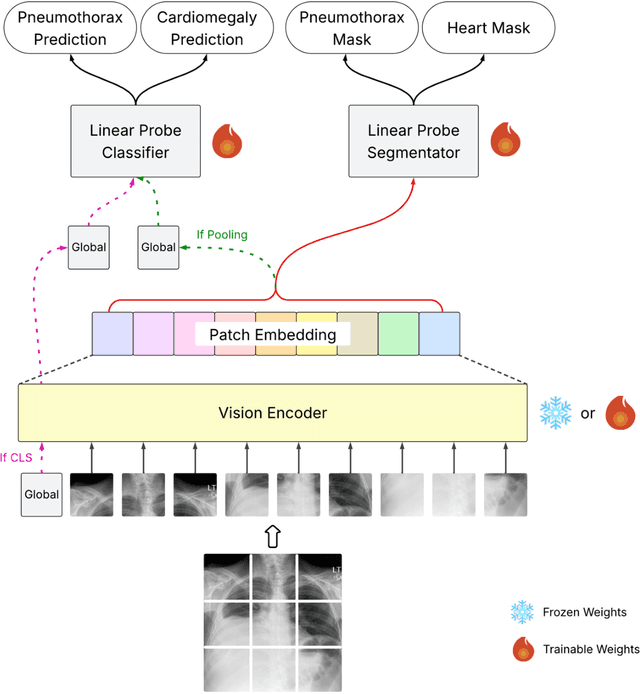
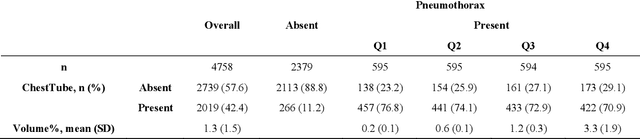
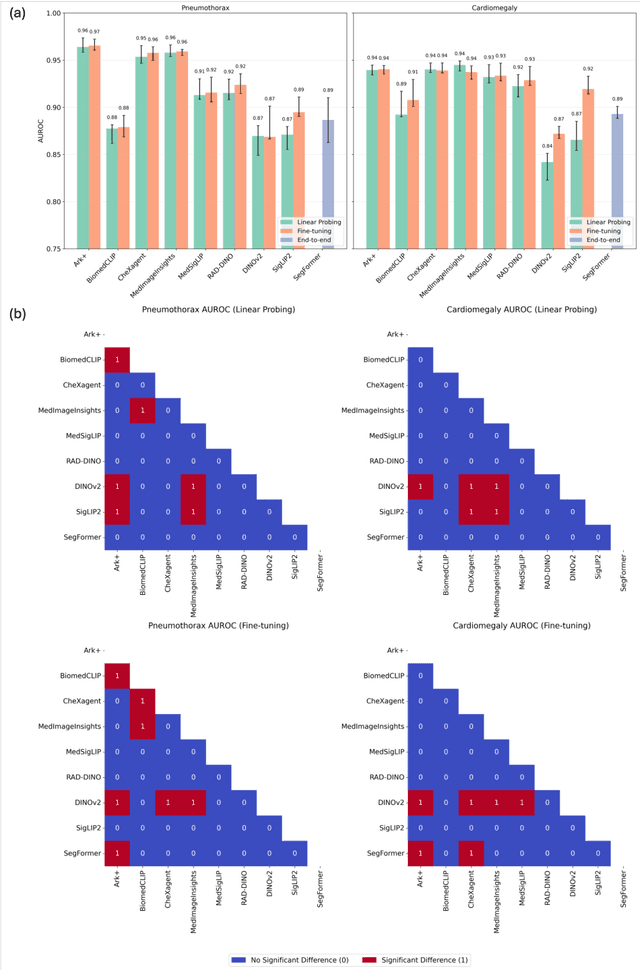
Foundation models (FMs) promise to generalize medical imaging, but their effectiveness varies. It remains unclear how pre-training domain (medical vs. general), paradigm (e.g., text-guided), and architecture influence embedding quality, hindering the selection of optimal encoders for specific radiology tasks. To address this, we evaluate vision encoders from eight medical and general-domain FMs for chest X-ray analysis. We benchmark classification (pneumothorax, cardiomegaly) and segmentation (pneumothorax, cardiac boundary) using linear probing and fine-tuning. Our results show that domain-specific pre-training provides a significant advantage; medical FMs consistently outperformed general-domain models in linear probing, establishing superior initial feature quality. However, feature utility is highly task-dependent. Pre-trained embeddings were strong for global classification and segmenting salient anatomy (e.g., heart). In contrast, for segmenting complex, subtle pathologies (e.g., pneumothorax), all FMs performed poorly without significant fine-tuning, revealing a critical gap in localizing subtle disease. Subgroup analysis showed FMs use confounding shortcuts (e.g., chest tubes for pneumothorax) for classification, a strategy that fails for precise segmentation. We also found that expensive text-image alignment is not a prerequisite; image-only (RAD-DINO) and label-supervised (Ark+) FMs were among top performers. Notably, a supervised, end-to-end baseline remained highly competitive, matching or exceeding the best FMs on segmentation tasks. These findings show that while medical pre-training is beneficial, architectural choices (e.g., multi-scale) are critical, and pre-trained features are not universally effective, especially for complex localization tasks where supervised models remain a strong alternative.
Evaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025



Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.
Subgroup Performance of a Commercial Digital Breast Tomosynthesis Model for Breast Cancer Detection
Mar 17, 2025While research has established the potential of AI models for mammography to improve breast cancer screening outcomes, there have not been any detailed subgroup evaluations performed to assess the strengths and weaknesses of commercial models for digital breast tomosynthesis (DBT) imaging. This study presents a granular evaluation of the Lunit INSIGHT DBT model on a large retrospective cohort of 163,449 screening mammography exams from the Emory Breast Imaging Dataset (EMBED). Model performance was evaluated in a binary context with various negative exam types (162,081 exams) compared against screen detected cancers (1,368 exams) as the positive class. The analysis was stratified across demographic, imaging, and pathologic subgroups to identify potential disparities. The model achieved an overall AUC of 0.91 (95% CI: 0.90-0.92) with a precision of 0.08 (95% CI: 0.08-0.08), and a recall of 0.73 (95% CI: 0.71-0.76). Performance was found to be robust across demographics, but cases with non-invasive cancers (AUC: 0.85, 95% CI: 0.83-0.87), calcifications (AUC: 0.80, 95% CI: 0.78-0.82), and dense breast tissue (AUC: 0.90, 95% CI: 0.88-0.91) were associated with significantly lower performance compared to other groups. These results highlight the need for detailed evaluation of model characteristics and vigilance in considering adoption of new tools for clinical deployment.
Synthetically Enhanced: Unveiling Synthetic Data's Potential in Medical Imaging Research
Nov 15, 2023



Chest X-rays (CXR) are the most common medical imaging study and are used to diagnose multiple medical conditions. This study examines the impact of synthetic data supplementation, using diffusion models, on the performance of deep learning (DL) classifiers for CXR analysis. We employed three datasets: CheXpert, MIMIC-CXR, and Emory Chest X-ray, training conditional denoising diffusion probabilistic models (DDPMs) to generate synthetic frontal radiographs. Our approach ensured that synthetic images mirrored the demographic and pathological traits of the original data. Evaluating the classifiers' performance on internal and external datasets revealed that synthetic data supplementation enhances model accuracy, particularly in detecting less prevalent pathologies. Furthermore, models trained on synthetic data alone approached the performance of those trained on real data. This suggests that synthetic data can potentially compensate for real data shortages in training robust DL models. However, despite promising outcomes, the superiority of real data persists.