 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimation and Optimal Control in Offline Contextual MDPs without Stationarity
May 05, 2026Contextual MDPs are powerful tools with wide applicability in areas from biostatistics to machine learning. However, specializing them to offline datasets has been challenging due to a lack of robust, theoretically backed methods. Our work tackles this problem by introducing a new approach towards adaptive estimation and cost optimization of contextual MDPs. This estimator, to the best of our knowledge, is the first of its kind, and is endowed with strong optimality guarantees. We achieve this by overcoming the key technical challenges evolving from the endogenous properties of contextual MDPs; such as non-stationarity, or model irregularity. Our guarantees are established under complete generality by utilizing the relatively recent and powerful statistical technique of $T$-estimation (Baraud, 2011). We first provide a procedure for selecting an estimator given a sample from a contextual MDP and use it to derive oracle risk bounds under two distinct, but nevertheless meaningful, loss functions. We then consider the problem of determining the optimal control with the aid of the aforementioned density estimate and provide finite sample guarantees for the cost function.
Identifying and Mitigating Gender Cues in Academic Recommendation Letters: An Interpretability Case Study
Apr 14, 2026Letters of recommendation (LoRs) can carry patterns of implicitly gendered language that can inadvertently influence downstream decisions, e.g. in hiring and admissions. In this work, we investigate the extent to which Transformer-based encoder models as well as Large Language Models (LLMs) can infer the gender of applicants in academic LoRs submitted to an U.S. medical-residency program after explicit identifiers like names and pronouns are de-gendered. While using three models (DistilBERT, RoBERTa, and Llama 2) to classify the gender of anonymized and de-gendered LoRs, significant gender leakage was observed as evident from up to 68% classification accuracy. Text interpretation methods, like TF-IDF and SHAP, demonstrate that certain linguistic patterns are strong proxies for gender, e.g. "emotional'' and "humanitarian'' are commonly associated with LoRs from female applicants. As an experiment in creating truly gender-neutral LoRs, these implicit gender cues were remove resulting in a drop of up to 5.5% accuracy and 2.7% macro $F_1$ score on re-training the classifiers. However, applicant gender prediction still remains better than chance. In this case study, our findings highlight that 1) LoRs contain gender-identifying cues that are hard to remove and may activate bias in decision-making and 2) while our technical framework may be a concrete step toward fairer academic and professional evaluations, future work is needed to interrogate the role that gender plays in LoR review. Taken together, our findings motivate upstream auditing of evaluative text in real-world academic letters of recommendation as a necessary complement to model-level fairness interventions.
Is Sliding Window All You Need? An Open Framework for Long-Sequence Recommendation
Apr 14, 2026Long interaction histories are central to modern recommender systems, yet training with long sequences is often dismissed as impractical under realistic memory and latency budgets. This work demonstrates that it is not only practical but also effective-at academic scale. We release a complete, end-to-end framework that implements industrial-style long-sequence training with sliding windows, including all data processing, training, and evaluation scripts. Beyond reproducing prior gains, we contribute two capabilities missing from earlier reports: (i) a runtime-aware ablation study that quantifies the accuracy-compute frontier across windowing regimes and strides, and (ii) a novel k-shift embedding layer that enables million-scale vocabularies on commodity GPUs with negligible accuracy loss. Our implementation trains reliably on modest university clusters while delivering competitive retrieval quality (e.g., up to +6.04% MRR and +6.34% Recall@10 on Retailrocket) with $\sim 4 \times $ training-time overheads. By packaging a robust pipeline, reporting training time costs, and introducing an embedding mechanism tailored for low-resource settings, we transform long-sequence training from a closed, industrial technique into a practical, open, and extensible methodology for the community.
PixRec: Leveraging Visual Context for Next-Item Prediction in Sequential Recommendation
Jan 10, 2026Large Language Models (LLMs) have recently shown strong potential for usage in sequential recommendation tasks through text-only models, which combine advanced prompt design, contrastive alignment, and fine-tuning on downstream domain-specific data. While effective, these approaches overlook the rich visual information present in many real-world recommendation scenarios, particularly in e-commerce. This paper proposes PixRec - a vision-language framework that incorporates both textual attributes and product images into the recommendation pipeline. Our architecture leverages a vision-language model backbone capable of jointly processing image-text sequences, maintaining a dual-tower structure and mixed training objective while aligning multi-modal feature projections for both item-item and user-item interactions. Using the Amazon Reviews dataset augmented with product images, our experiments demonstrate $3\times$ and 40% improvements in top-rank and top-10 rank accuracy over text-only recommenders respectively, indicating that visual features can help distinguish items with similar textual descriptions. Our work outlines future directions for scaling multi-modal recommenders training, enhancing visual-text feature fusion, and evaluating inference-time performance. This work takes a step toward building software systems utilizing visual information in sequential recommendation for real-world applications like e-commerce.
Time-Constrained Recommendations: Reinforcement Learning Strategies for E-Commerce
Dec 13, 2025Unlike traditional recommendation tasks, finite user time budgets introduce a critical resource constraint, requiring the recommender system to balance item relevance and evaluation cost. For example, in a mobile shopping interface, users interact with recommendations by scrolling, where each scroll triggers a list of items called slate. Users incur an evaluation cost - time spent assessing item features before deciding to click. Highly relevant items having higher evaluation costs may not fit within the user's time budget, affecting engagement. In this position paper, our objective is to evaluate reinforcement learning algorithms that learn patterns in user preferences and time budgets simultaneously, crafting recommendations with higher engagement potential under resource constraints. Our experiments explore the use of reinforcement learning to recommend items for users using Alibaba's Personalized Re-ranking dataset supporting slate optimization in e-commerce contexts. Our contributions include (i) a unified formulation of time-constrained slate recommendation modeled as Markov Decision Processes (MDPs) with budget-aware utilities; (ii) a simulation framework to study policy behavior on re-ranking data; and (iii) empirical evidence that on-policy and off-policy control can improve performance under tight time budgets than traditional contextual bandit-based methods.
CLT and Edgeworth Expansion for m-out-of-n Bootstrap Estimators of The Studentized Median
May 16, 2025The m-out-of-n bootstrap, originally proposed by Bickel, Gotze, and Zwet (1992), approximates the distribution of a statistic by repeatedly drawing m subsamples (with m much smaller than n) without replacement from an original sample of size n. It is now routinely used for robust inference with heavy-tailed data, bandwidth selection, and other large-sample applications. Despite its broad applicability across econometrics, biostatistics, and machine learning, rigorous parameter-free guarantees for the soundness of the m-out-of-n bootstrap when estimating sample quantiles have remained elusive. This paper establishes such guarantees by analyzing the estimator of sample quantiles obtained from m-out-of-n resampling of a dataset of size n. We first prove a central limit theorem for a fully data-driven version of the estimator that holds under a mild moment condition and involves no unknown nuisance parameters. We then show that the moment assumption is essentially tight by constructing a counter-example in which the CLT fails. Strengthening the assumptions slightly, we derive an Edgeworth expansion that provides exact convergence rates and, as a corollary, a Berry Esseen bound on the bootstrap approximation error. Finally, we illustrate the scope of our results by deriving parameter-free asymptotic distributions for practical statistics, including the quantiles for random walk Metropolis-Hastings and the rewards of ergodic Markov decision processes, thereby demonstrating the usefulness of our theory in modern estimation and learning tasks.
MM-PoE: Multiple Choice Reasoning via. Process of Elimination using Multi-Modal Models
Dec 10, 2024



This paper introduces Multiple Choice Reasoning via. Process of Elimination using Multi-Modal models, herein referred to as Multi-Modal Process of Elimination (MM-PoE). This novel methodology is engineered to augment the efficacy of Vision-Language Models (VLMs) in multiple-choice visual reasoning tasks. Diverging from conventional approaches that evaluate each option independently, MM-PoE employs a dual-step scoring paradigm that initially identifies and excludes implausible choices, subsequently concentrating on the most probable remaining options. This method emulates human test-taking strategies, where individuals typically eliminate clearly incorrect answers prior to selecting the optimal response. Our empirical evaluations, conducted across three benchmark datasets, reveal that MM-PoE significantly improves both zero-shot and few-shot performance of contemporary state-of-the-art VLMs. Critically, this approach not only broadens the application of the elimination process to multi-modal contexts but also allows few-shot experiments, thereby addressing two principal limitations concerning usage of PoE only in zero-shot settings and only with a language-only framework. As a result, MM-PoE not only refines the reasoning capabilities of VLMs but also broadens their applicability to complex visual question-answering scenarios. All code and documentation supporting our work are available at https://pypi.org/project/mm-poe/, enabling researchers and practitioners to easily integrate and further develop these techniques.
Free and Customizable Code Documentation with LLMs: A Fine-Tuning Approach
Dec 01, 2024
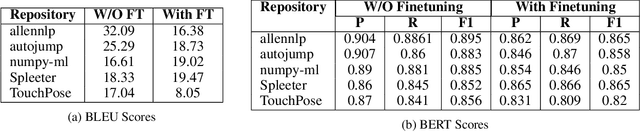

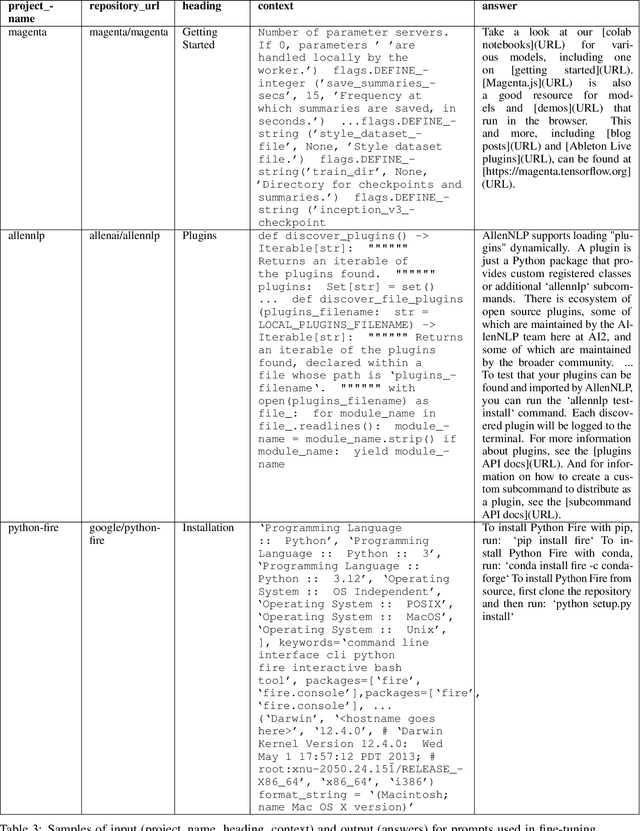
Automated documentation of programming source code is a challenging task with significant practical and scientific implications for the developer community. We present a large language model (LLM)-based application that developers can use as a support tool to generate basic documentation for any publicly available repository. Over the last decade, several papers have been written on generating documentation for source code using neural network architectures. With the recent advancements in LLM technology, some open-source applications have been developed to address this problem. However, these applications typically rely on the OpenAI APIs, which incur substantial financial costs, particularly for large repositories. Moreover, none of these open-source applications offer a fine-tuned model or features to enable users to fine-tune. Additionally, finding suitable data for fine-tuning is often challenging. Our application addresses these issues which is available at https://pypi.org/project/readme-ready/.
On the Consistency of Maximum Likelihood Estimation of Probabilistic Principal Component Analysis
Nov 13, 2023Probabilistic principal component analysis (PPCA) is currently one of the most used statistical tools to reduce the ambient dimension of the data. From multidimensional scaling to the imputation of missing data, PPCA has a broad spectrum of applications ranging from science and engineering to quantitative finance. Despite this wide applicability in various fields, hardly any theoretical guarantees exist to justify the soundness of the maximal likelihood (ML) solution for this model. In fact, it is well known that the maximum likelihood estimation (MLE) can only recover the true model parameters up to a rotation. The main obstruction is posed by the inherent identifiability nature of the PPCA model resulting from the rotational symmetry of the parameterization. To resolve this ambiguity, we propose a novel approach using quotient topological spaces and in particular, we show that the maximum likelihood solution is consistent in an appropriate quotient Euclidean space. Furthermore, our consistency results encompass a more general class of estimators beyond the MLE. Strong consistency of the ML estimate and consequently strong covariance estimation of the PPCA model have also been established under a compactness assumption.
Single-Pass Pivot Algorithm for Correlation Clustering. Keep it simple!
May 23, 2023
We show that a simple single-pass semi-streaming variant of the Pivot algorithm for Correlation Clustering gives a (3 + {\epsilon})-approximation using O(n/{\epsilon}) words of memory. This is a slight improvement over the recent results of Cambus, Kuhn, Lindy, Pai, and Uitto, who gave a (3 + {\epsilon})-approximation using O(n log n) words of memory, and Behnezhad, Charikar, Ma, and Tan, who gave a 5-approximation using O(n) words of memory. One of the main contributions of this paper is that both the algorithm and its analysis are very simple, and also the algorithm is easy to implement.