 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixRec: Leveraging Visual Context for Next-Item Prediction in Sequential Recommendation
Jan 10, 2026Large Language Models (LLMs) have recently shown strong potential for usage in sequential recommendation tasks through text-only models, which combine advanced prompt design, contrastive alignment, and fine-tuning on downstream domain-specific data. While effective, these approaches overlook the rich visual information present in many real-world recommendation scenarios, particularly in e-commerce. This paper proposes PixRec - a vision-language framework that incorporates both textual attributes and product images into the recommendation pipeline. Our architecture leverages a vision-language model backbone capable of jointly processing image-text sequences, maintaining a dual-tower structure and mixed training objective while aligning multi-modal feature projections for both item-item and user-item interactions. Using the Amazon Reviews dataset augmented with product images, our experiments demonstrate $3\times$ and 40% improvements in top-rank and top-10 rank accuracy over text-only recommenders respectively, indicating that visual features can help distinguish items with similar textual descriptions. Our work outlines future directions for scaling multi-modal recommenders training, enhancing visual-text feature fusion, and evaluating inference-time performance. This work takes a step toward building software systems utilizing visual information in sequential recommendation for real-world applications like e-commerce.
Time-Constrained Recommendations: Reinforcement Learning Strategies for E-Commerce
Dec 13, 2025Unlike traditional recommendation tasks, finite user time budgets introduce a critical resource constraint, requiring the recommender system to balance item relevance and evaluation cost. For example, in a mobile shopping interface, users interact with recommendations by scrolling, where each scroll triggers a list of items called slate. Users incur an evaluation cost - time spent assessing item features before deciding to click. Highly relevant items having higher evaluation costs may not fit within the user's time budget, affecting engagement. In this position paper, our objective is to evaluate reinforcement learning algorithms that learn patterns in user preferences and time budgets simultaneously, crafting recommendations with higher engagement potential under resource constraints. Our experiments explore the use of reinforcement learning to recommend items for users using Alibaba's Personalized Re-ranking dataset supporting slate optimization in e-commerce contexts. Our contributions include (i) a unified formulation of time-constrained slate recommendation modeled as Markov Decision Processes (MDPs) with budget-aware utilities; (ii) a simulation framework to study policy behavior on re-ranking data; and (iii) empirical evidence that on-policy and off-policy control can improve performance under tight time budgets than traditional contextual bandit-based methods.
MM-PoE: Multiple Choice Reasoning via. Process of Elimination using Multi-Modal Models
Dec 10, 2024



This paper introduces Multiple Choice Reasoning via. Process of Elimination using Multi-Modal models, herein referred to as Multi-Modal Process of Elimination (MM-PoE). This novel methodology is engineered to augment the efficacy of Vision-Language Models (VLMs) in multiple-choice visual reasoning tasks. Diverging from conventional approaches that evaluate each option independently, MM-PoE employs a dual-step scoring paradigm that initially identifies and excludes implausible choices, subsequently concentrating on the most probable remaining options. This method emulates human test-taking strategies, where individuals typically eliminate clearly incorrect answers prior to selecting the optimal response. Our empirical evaluations, conducted across three benchmark datasets, reveal that MM-PoE significantly improves both zero-shot and few-shot performance of contemporary state-of-the-art VLMs. Critically, this approach not only broadens the application of the elimination process to multi-modal contexts but also allows few-shot experiments, thereby addressing two principal limitations concerning usage of PoE only in zero-shot settings and only with a language-only framework. As a result, MM-PoE not only refines the reasoning capabilities of VLMs but also broadens their applicability to complex visual question-answering scenarios. All code and documentation supporting our work are available at https://pypi.org/project/mm-poe/, enabling researchers and practitioners to easily integrate and further develop these techniques.
Free and Customizable Code Documentation with LLMs: A Fine-Tuning Approach
Dec 01, 2024
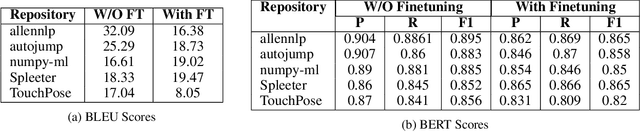

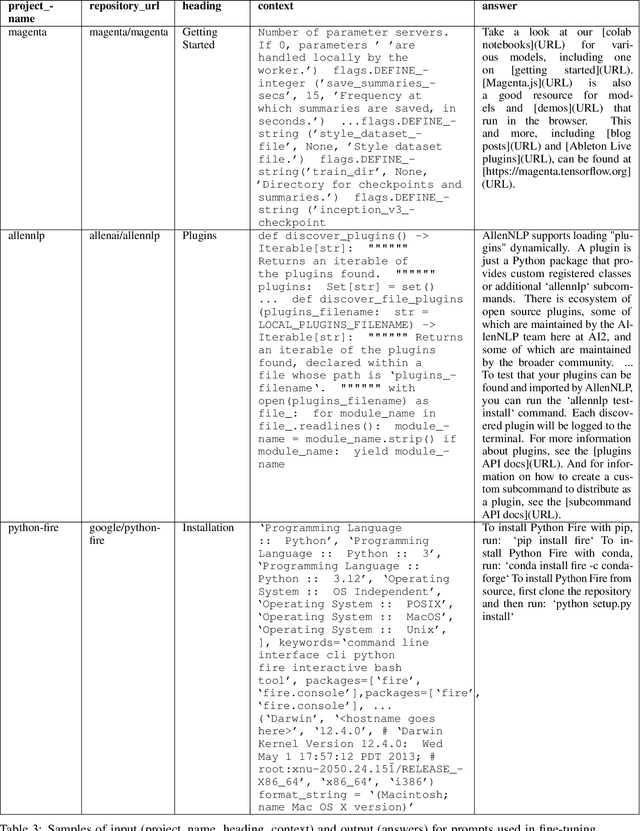
Automated documentation of programming source code is a challenging task with significant practical and scientific implications for the developer community. We present a large language model (LLM)-based application that developers can use as a support tool to generate basic documentation for any publicly available repository. Over the last decade, several papers have been written on generating documentation for source code using neural network architectures. With the recent advancements in LLM technology, some open-source applications have been developed to address this problem. However, these applications typically rely on the OpenAI APIs, which incur substantial financial costs, particularly for large repositories. Moreover, none of these open-source applications offer a fine-tuned model or features to enable users to fine-tune. Additionally, finding suitable data for fine-tuning is often challenging. Our application addresses these issues which is available at https://pypi.org/project/readme-ready/.