 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Hybrid framework for ANomaly Detection (HAND) -- applied to Screening Mammogram
Sep 17, 2024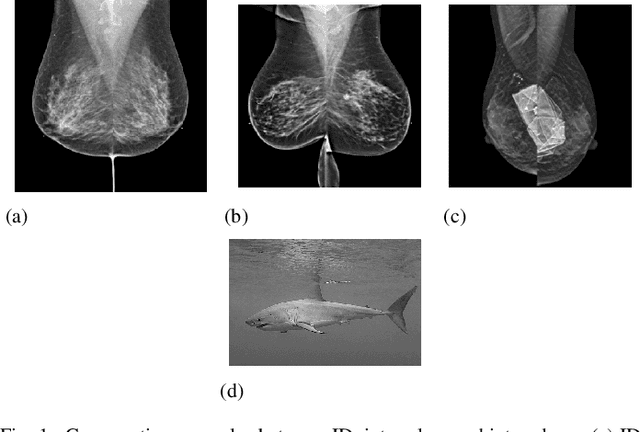
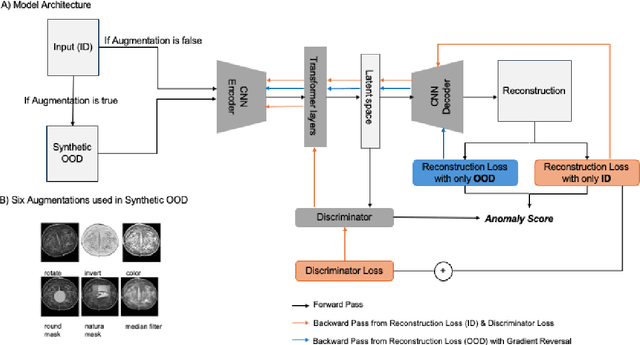
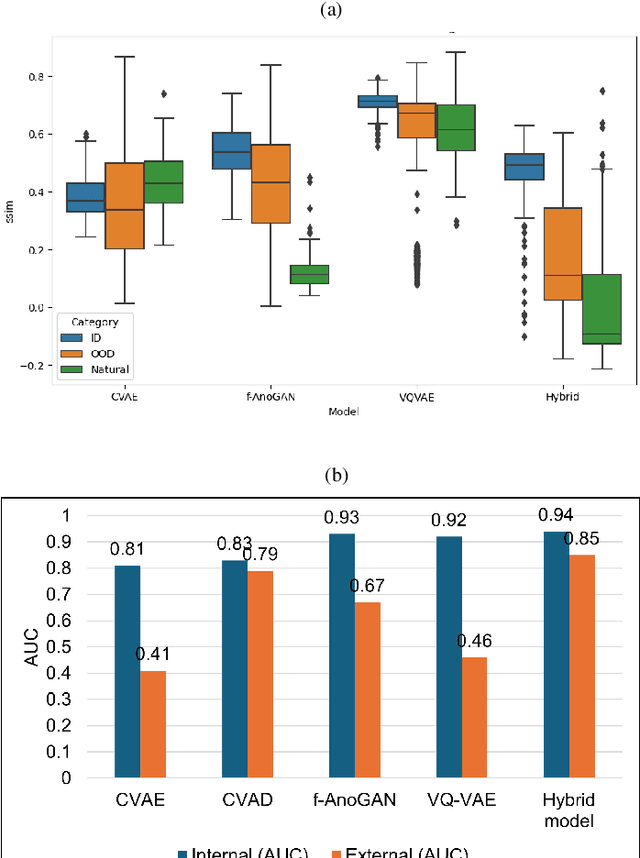
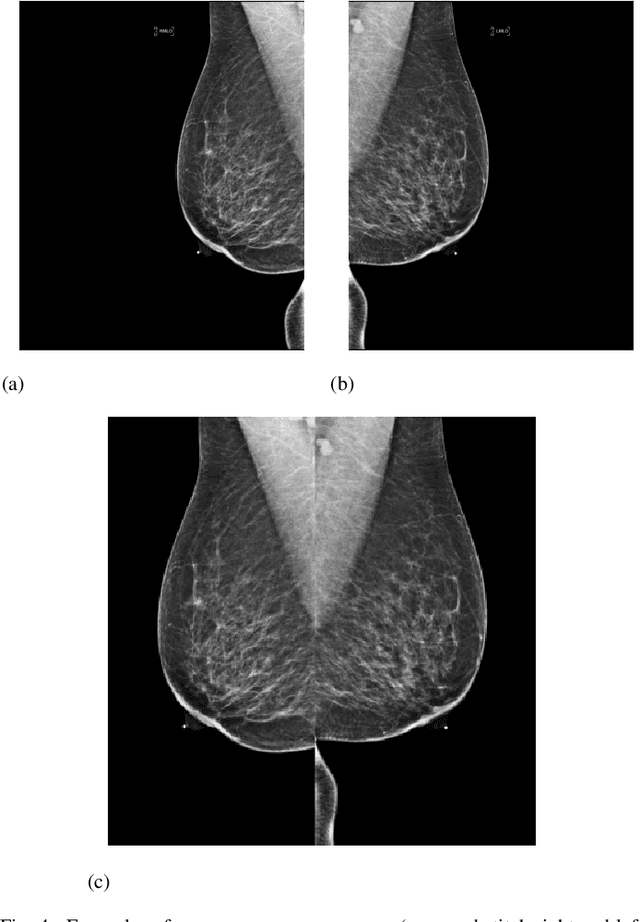
Out-of-distribution (OOD) detection is crucial for enhancing the generalization of AI models used in mammogram screening. Given the challenge of limited prior knowledge about OOD samples in external datasets, unsupervised generative learning is a preferable solution which trains the model to discern the normal characteristics of in-distribution (ID) data. The hypothesis is that during inference, the model aims to reconstruct ID samples accurately, while OOD samples exhibit poorer reconstruction due to their divergence from normality. Inspired by state-of-the-art (SOTA) hybrid architectures combining CNNs and transformers, we developed a novel backbone - HAND, for detecting OOD from large-scale digital screening mammogram studies. To boost the learning efficiency, we incorporated synthetic OOD samples and a parallel discriminator in the latent space to distinguish between ID and OOD samples. Gradient reversal to the OOD reconstruction loss penalizes the model for learning OOD reconstructions. An anomaly score is computed by weighting the reconstruction and discriminator loss. On internal RSNA mammogram held-out test and external Mayo clinic hand-curated dataset, the proposed HAND model outperformed encoder-based and GAN-based baselines, and interestingly, it also outperformed the hybrid CNN+transformer baselines. Therefore, the proposed HAND pipeline offers an automated efficient computational solution for domain-specific quality checks in external screening mammograms, yielding actionable insights without direct exposure to the private medical imaging data.
HcNet: Image Modeling with Heat Conduction Equation
Aug 13, 2024



Foundation models, such as CNNs and ViTs, have powered the development of image modeling. However, general guidance to model architecture design is still missing. The design of many modern model architectures, such as residual structures, multiplicative gating signal, and feed-forward networks, can be interpreted in terms of the heat conduction equation. This finding inspired us to model images by the heat conduction equation, where the essential idea is to conceptualize image features as temperatures and model their information interaction as the diffusion of thermal energy. We can take advantage of the rich knowledge in the heat conduction equation to guide us in designing new and more interpretable models. As an example, we propose Heat Conduction Layer and Refine Approximation Layer inspired by solving the heat conduction equation using Finite Difference Method and Fourier series, respectively. This paper does not aim to present a state-of-the-art model; instead, it seeks to integrate the overall architectural design of the model into the heat conduction theory framework. Nevertheless, our Heat Conduction Network (HcNet) still shows competitive performance. Code available at \url{https://github.com/ZheminZhang1/HcNet}.
Generating Multi-Center Classifier via Conditional Gaussian Distribution
Jan 29, 2024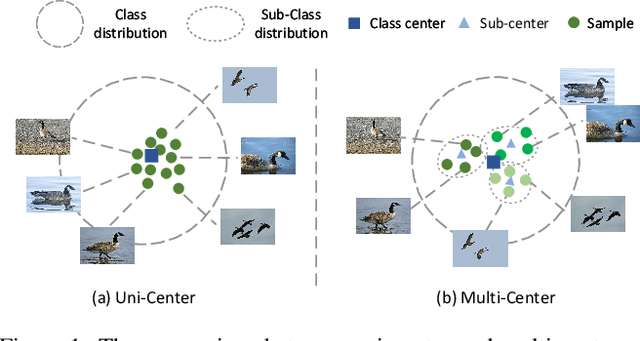
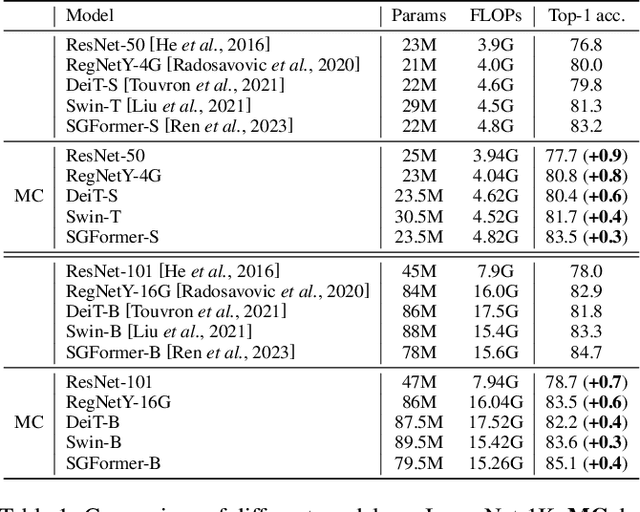
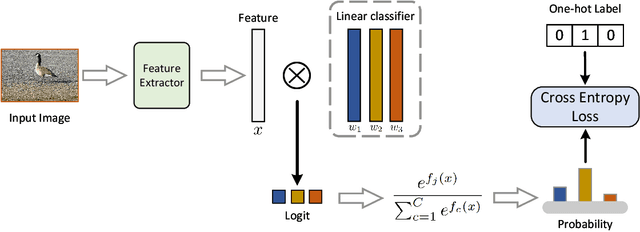
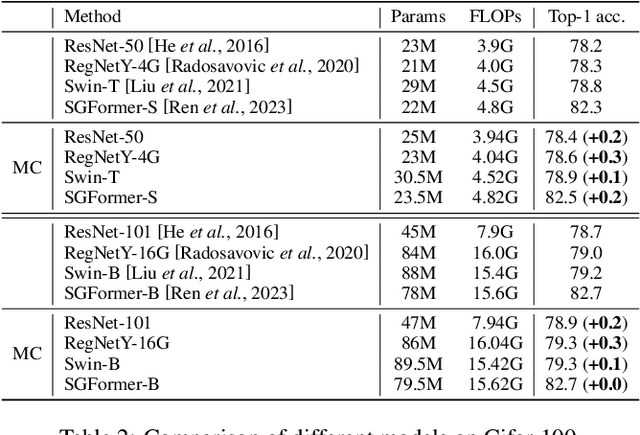
The linear classifier is widely used in various image classification tasks. It works by optimizing the distance between a sample and its corresponding class center. However, in real-world data, one class can contain several local clusters, e.g., birds of different poses. To address this complexity, we propose a novel multi-center classifier. Different from the vanilla linear classifier, our proposal is established on the assumption that the deep features of the training set follow a Gaussian Mixture distribution. Specifically, we create a conditional Gaussian distribution for each class and then sample multiple sub-centers from that distribution to extend the linear classifier. This approach allows the model to capture intra-class local structures more efficiently. In addition, at test time we set the mean of the conditional Gaussian distribution as the class center of the linear classifier and follow the vanilla linear classifier outputs, thus requiring no additional parameters or computational overhead. Extensive experiments on image classification show that the proposed multi-center classifier is a powerful alternative to widely used linear classifiers. Code available at https://github.com/ZheminZhang1/MultiCenter-Classifier.
Vision Big Bird: Random Sparsification for Full Attention
Nov 10, 2023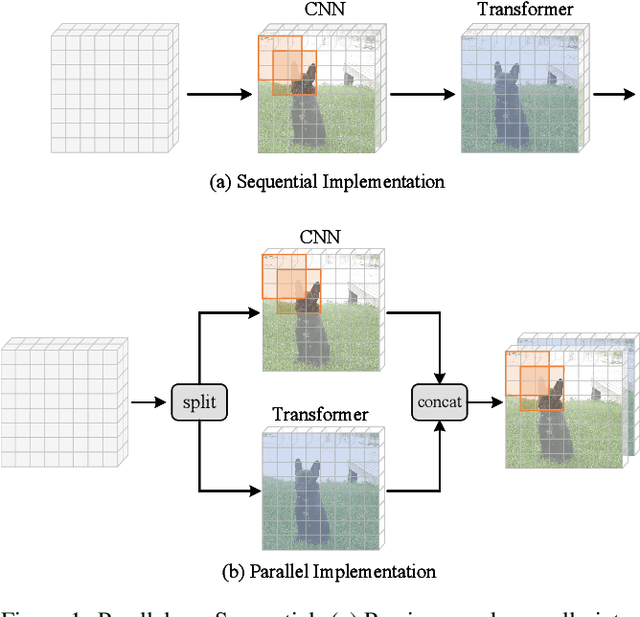
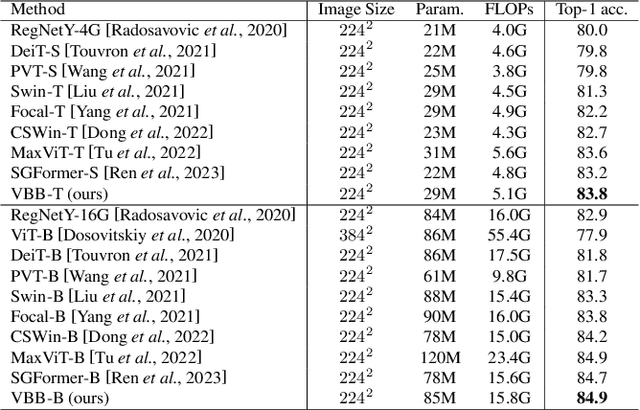
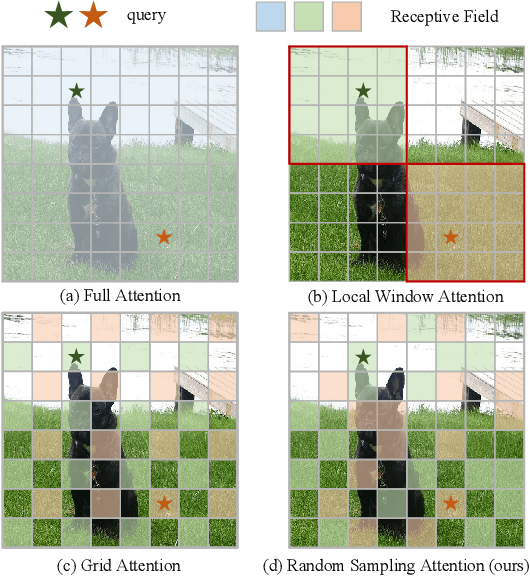
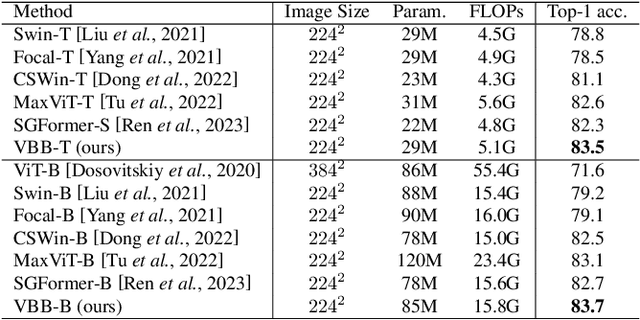
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Inspired by one of the most successful transformers-based models for NLP: Big Bird, we propose a novel sparse attention mechanism for Vision Transformers (ViT). Specifically, we separate the heads into three groups, the first group used convolutional neural network (CNN) to extract local features and provide positional information for the model, the second group used Random Sampling Windows (RS-Win) for sparse self-attention calculation, and the third group reduces the resolution of the keys and values by average pooling for global attention. Based on these components, ViT maintains the sparsity of self-attention while maintaining the merits of Big Bird (i.e., the model is a universal approximator of sequence functions and is Turing complete). Moreover, our results show that the positional encoding, a crucial component in ViTs, can be safely removed in our model. Experiments show that Vision Big Bird demonstrates competitive performance on common vision tasks.
RSIR Transformer: Hierarchical Vision Transformer using Random Sampling Windows and Important Region Windows
Apr 27, 2023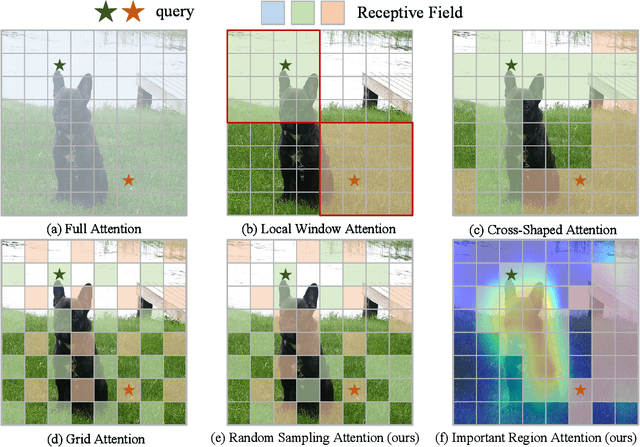
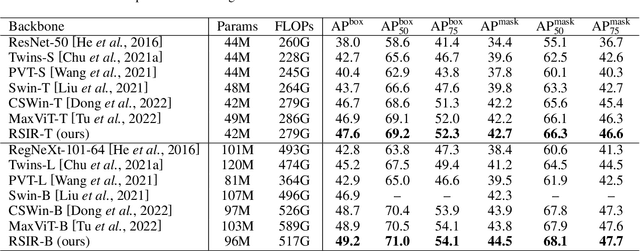
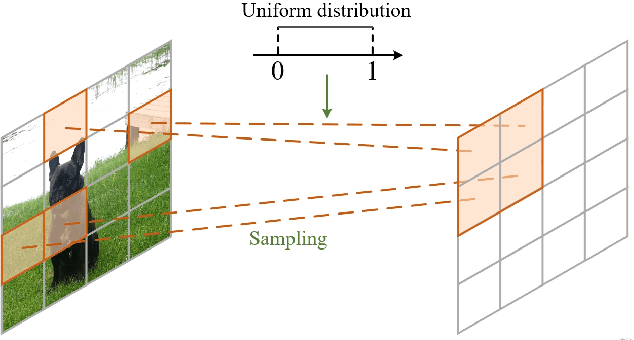
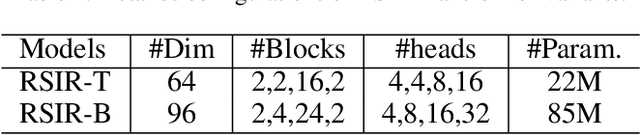
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Local self-attention runs attention computation within a limited region for the sake of efficiency, resulting in insufficient context modeling as their receptive fields are small. In this work, we introduce two new attention modules to enhance the global modeling capability of the hierarchical vision transformer, namely, random sampling windows (RS-Win) and important region windows (IR-Win). Specifically, RS-Win sample random image patches to compose the window, following a uniform distribution, i.e., the patches in RS-Win can come from any position in the image. IR-Win composes the window according to the weights of the image patches in the attention map. Notably, RS-Win is able to capture global information throughout the entire model, even in earlier, high-resolution stages. IR-Win enables the self-attention module to focus on important regions of the image and capture more informative features. Incorporated with these designs, RSIR-Win Transformer demonstrates competitive performance on common vision tasks.
Axially Expanded Windows for Local-Global Interaction in Vision Transformers
Sep 19, 2022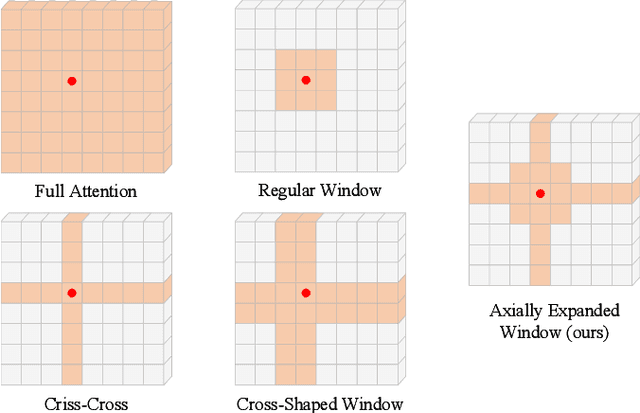
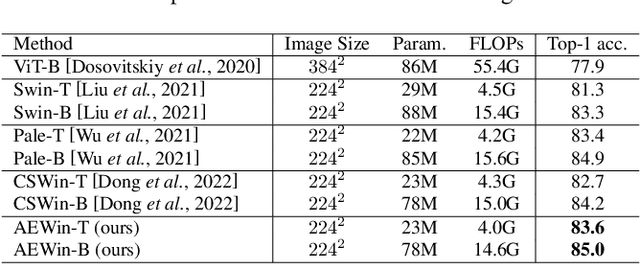
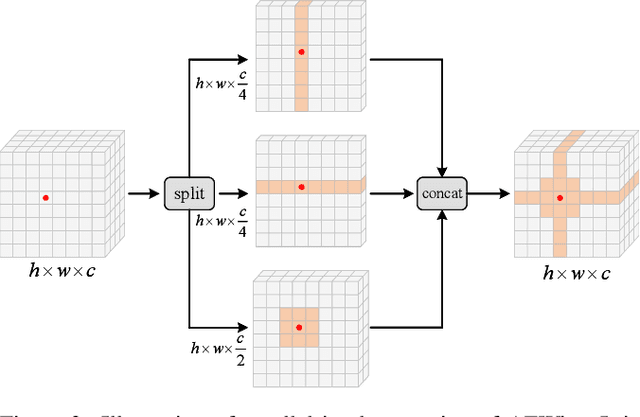
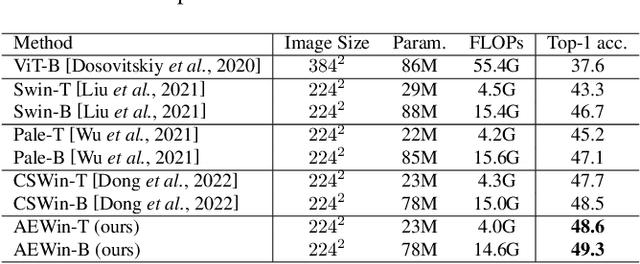
Recently, Transformers have shown promising performance in various vision tasks. A challenging issue in Transformer design is that global self-attention is very expensive to compute, especially for the high-resolution vision tasks. Local self-attention performs attention computation within a local region to improve its efficiency, which leads to their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. When observing a scene, humans usually focus on a local region while attending to non-attentional regions at coarse granularity. Based on this observation, we develop the axially expanded window self-attention mechanism that performs fine-grained self-attention within the local window and coarse-grained self-attention in the horizontal and vertical axes, and thus can effectively capturing both short- and long-range visual dependencies.
Self-Supervised Implicit Attention: Guided Attention by The Model Itself
Jun 15, 2022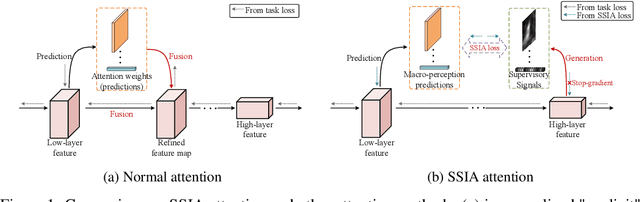

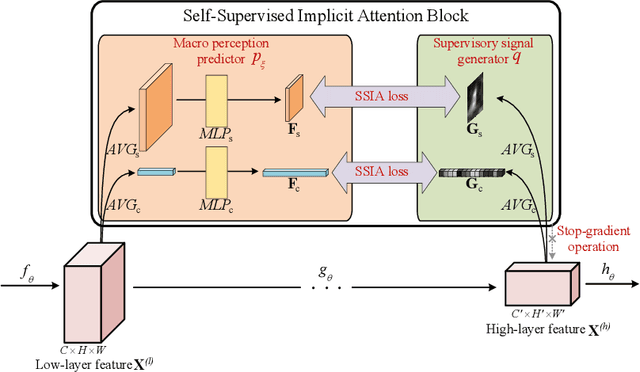
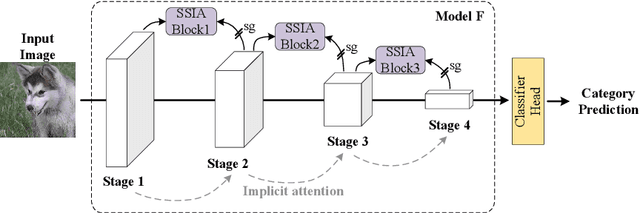
We propose Self-Supervised Implicit Attention (SSIA), a new approach that adaptively guides deep neural network models to gain attention by exploiting the properties of the models themselves. SSIA is a novel attention mechanism that does not require any extra parameters, computation, or memory access costs during inference, which is in contrast to existing attention mechanism. In short, by considering attention weights as higher-level semantic information, we reconsidered the implementation of existing attention mechanisms and further propose generating supervisory signals from higher network layers to guide lower network layers for parameter updates. We achieved this by building a self-supervised learning task using the hierarchical features of the network itself, which only works at the training stage. To verify the effectiveness of SSIA, we performed a particular implementation (called an SSIA block) in convolutional neural network models and validated it on several image classification datasets. The experimental results show that an SSIA block can significantly improve the model performance, even outperforms many popular attention methods that require additional parameters and computation costs, such as Squeeze-and-Excitation and Convolutional Block Attention Module. Our implementation will be available on GitHub.
Position Labels for Self-Supervised Vision Transformer
Jun 10, 2022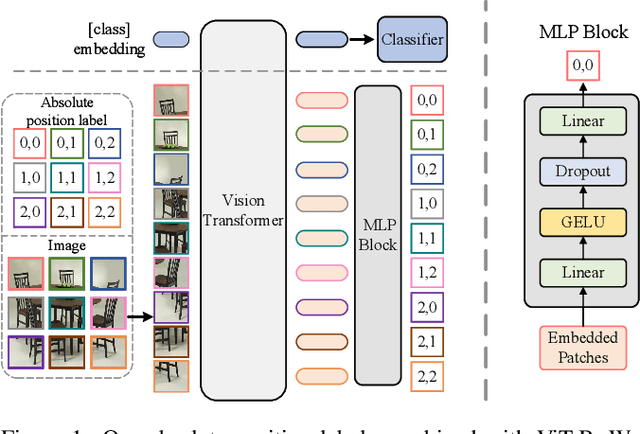
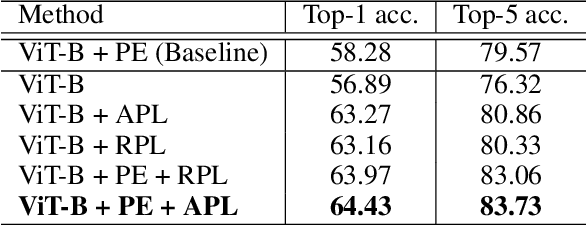
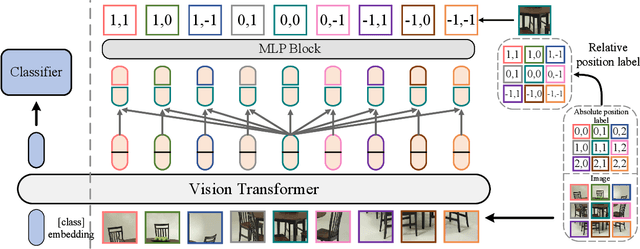
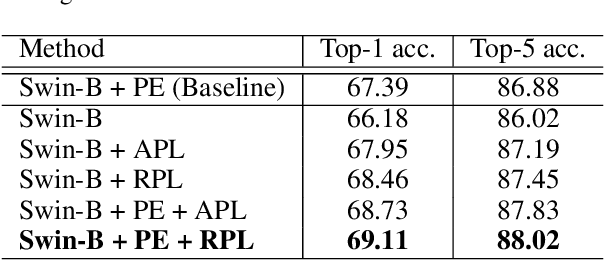
Position encoding is important for vision transformer (ViT) to capture the spatial structure of the input image. General efficacy has been proven in ViT. In our work we propose to train ViT to recognize the 2D position encoding of patches of the input image, this apparently simple task actually yields a meaningful self-supervisory task. Based on previous work on ViT position encoding, we propose two position labels dedicated to 2D images including absolute position and relative position. Our position labels can be easily plugged into transformer, combined with the various current ViT variants. It can work in two ways: 1.As an auxiliary training target for vanilla ViT (e.g., ViT-B and Swin-B) to improve model performance. 2. Combine the self-supervised ViT (e.g., MAE) to provide a more powerful self-supervised signal for semantic feature learning. Experiments demonstrate that solely due to the proposed self-supervised methods, Swin-B and ViT-B obtained improvements of 1.9% (top-1 Acc) and 5.6% (top-1 Acc) on Mini-ImageNet, respectively.
ReplaceBlock: An improved regularization method based on background information
Mar 30, 2022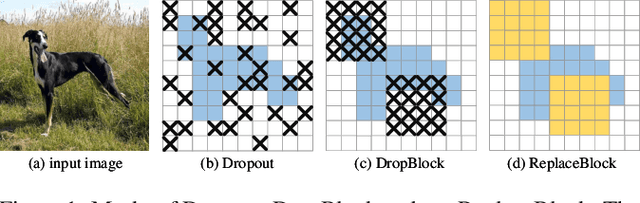
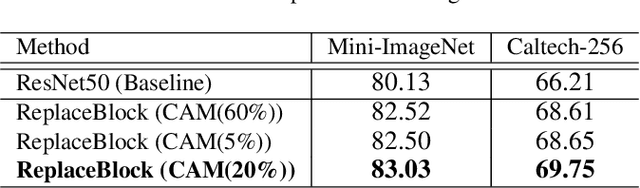
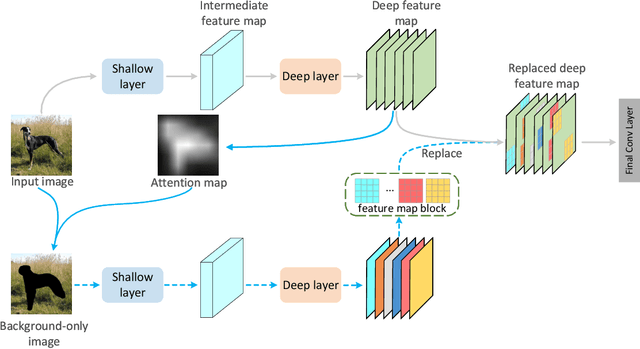
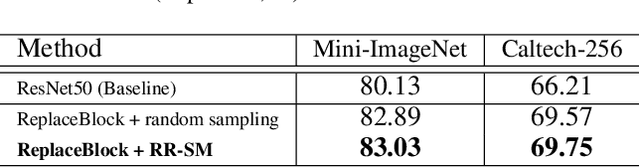
Attention mechanism, being frequently used to train networks for better feature representations, can effectively disentangle the target object from irrelevant objects in the background. Given an arbitrary image, we find that the background's irrelevant objects are most likely to occlude/block the target object. We propose, based on this finding, a ReplaceBlock to simulate the situations when the target object is partially occluded by the objects that are deemed as background. Specifically, ReplaceBlock erases the target object in the image, and then generates a feature map with only irrelevant objects and background by the model. Finally, some regions in the background feature map are used to replace some regions of the target object in the original image feature map. In this way, ReplaceBlock can effectively simulate the feature map of the occluded image. The experimental results show that ReplaceBlock works better than DropBlock in regularizing convolutional networks.
The Fixed Sub-Center: A Better Way to Capture Data Complexity
Mar 24, 2022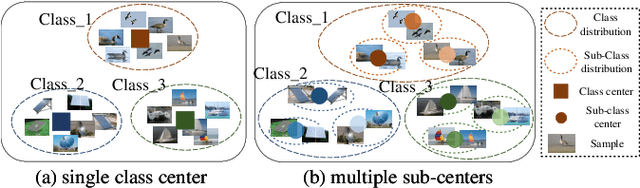
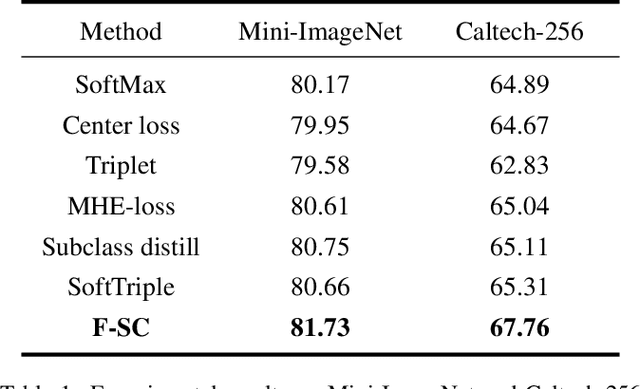
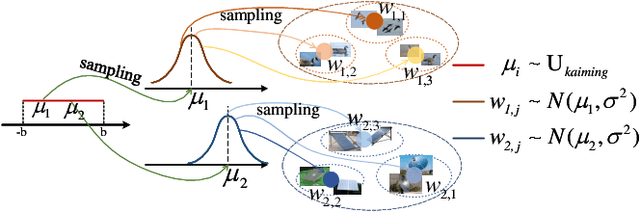
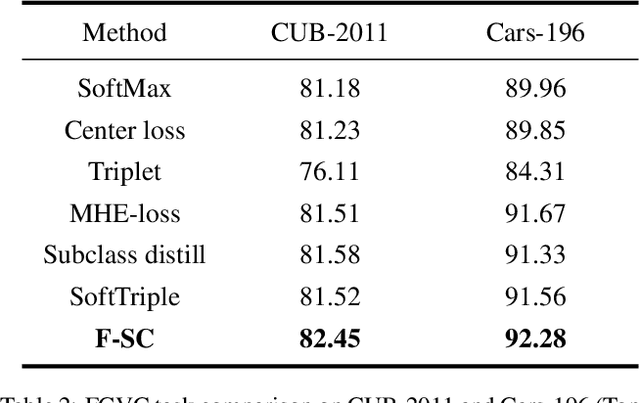
Treating class with a single center may hardly capture data distribution complexities. Using multiple sub-centers is an alternative way to address this problem. However, highly correlated sub-classes, the classifier's parameters grow linearly with the number of classes, and lack of intra-class compactness are three typical issues that need to be addressed in existing multi-subclass methods. To this end, we propose to use Fixed Sub-Center (F-SC), which allows the model to create more discrepant sub-centers while saving memory and cutting computational costs considerably. The F-SC specifically, first samples a class center Ui for each class from a uniform distribution, and then generates a normal distribution for each class, where the mean is equal to Ui. Finally, the sub-centers are sampled based on the normal distribution corresponding to each class, and the sub-centers are fixed during the training process avoiding the overhead of gradient calculation. Moreover, F-SC penalizes the Euclidean distance between the samples and their corresponding sub-centers, it helps remain intra-compactness. The experimental results show that F-SC significantly improves the accuracy of both image classification and fine-grained recognition tasks.