 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
Jul 22, 2022



Generative models for audio-conditioned dance motion synthesis map music features to dance movements. Models are trained to associate motion patterns to audio patterns, usually without an explicit knowledge of the human body. This approach relies on a few assumptions: strong music-dance correlation, controlled motion data and relatively simple poses and movements. These characteristics are found in all existing datasets for dance motion synthesis, and indeed recent methods can achieve good results.We introduce a new dataset aiming to challenge these common assumptions, compiling a set of dynamic dance sequences displaying complex human poses. We focus on breakdancing which features acrobatic moves and tangled postures. We source our data from the Red Bull BC One competition videos. Estimating human keypoints from these videos is difficult due to the complexity of the dance, as well as the multiple moving cameras recording setup. We adopt a hybrid labelling pipeline leveraging deep estimation models as well as manual annotations to obtain good quality keypoint sequences at a reduced cost. Our efforts produced the BRACE dataset, which contains over 3 hours and 30 minutes of densely annotated poses. We test state-of-the-art methods on BRACE, showing their limitations when evaluated on complex sequences. Our dataset can readily foster advance in dance motion synthesis. With intricate poses and swift movements, models are forced to go beyond learning a mapping between modalities and reason more effectively about body structure and movements.
Self-Supervised Implicit Attention: Guided Attention by The Model Itself
Jun 15, 2022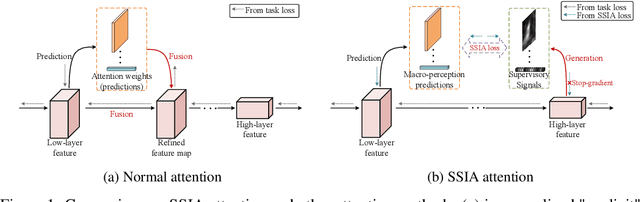

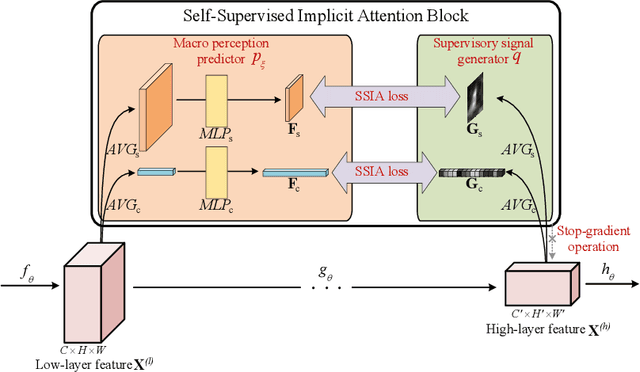
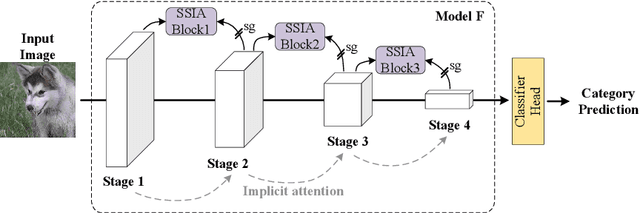
We propose Self-Supervised Implicit Attention (SSIA), a new approach that adaptively guides deep neural network models to gain attention by exploiting the properties of the models themselves. SSIA is a novel attention mechanism that does not require any extra parameters, computation, or memory access costs during inference, which is in contrast to existing attention mechanism. In short, by considering attention weights as higher-level semantic information, we reconsidered the implementation of existing attention mechanisms and further propose generating supervisory signals from higher network layers to guide lower network layers for parameter updates. We achieved this by building a self-supervised learning task using the hierarchical features of the network itself, which only works at the training stage. To verify the effectiveness of SSIA, we performed a particular implementation (called an SSIA block) in convolutional neural network models and validated it on several image classification datasets. The experimental results show that an SSIA block can significantly improve the model performance, even outperforms many popular attention methods that require additional parameters and computation costs, such as Squeeze-and-Excitation and Convolutional Block Attention Module. Our implementation will be available on GitHub.
Position Labels for Self-Supervised Vision Transformer
Jun 10, 2022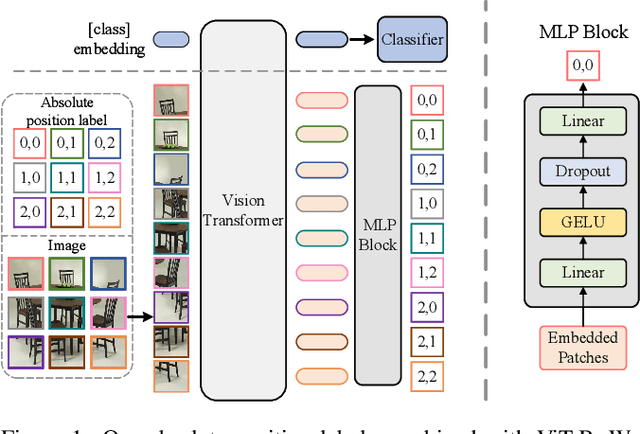
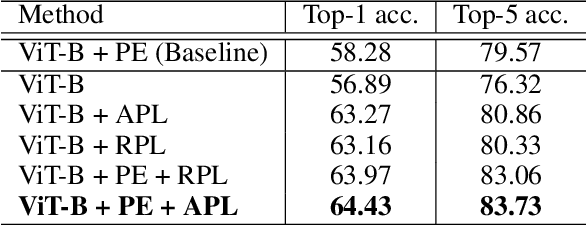
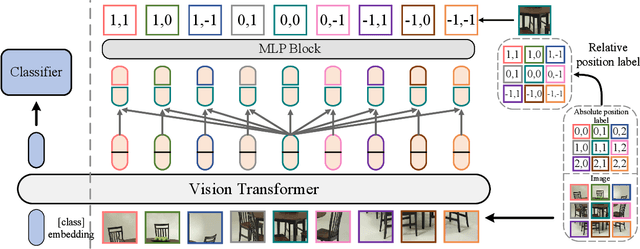
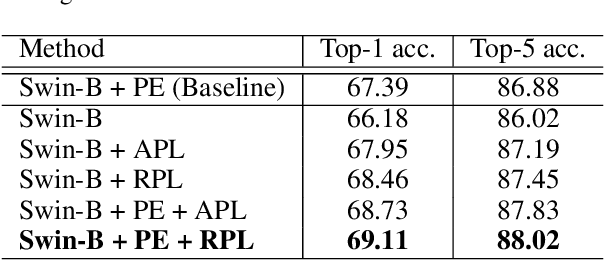
Position encoding is important for vision transformer (ViT) to capture the spatial structure of the input image. General efficacy has been proven in ViT. In our work we propose to train ViT to recognize the 2D position encoding of patches of the input image, this apparently simple task actually yields a meaningful self-supervisory task. Based on previous work on ViT position encoding, we propose two position labels dedicated to 2D images including absolute position and relative position. Our position labels can be easily plugged into transformer, combined with the various current ViT variants. It can work in two ways: 1.As an auxiliary training target for vanilla ViT (e.g., ViT-B and Swin-B) to improve model performance. 2. Combine the self-supervised ViT (e.g., MAE) to provide a more powerful self-supervised signal for semantic feature learning. Experiments demonstrate that solely due to the proposed self-supervised methods, Swin-B and ViT-B obtained improvements of 1.9% (top-1 Acc) and 5.6% (top-1 Acc) on Mini-ImageNet, respectively.
ReplaceBlock: An improved regularization method based on background information
Mar 30, 2022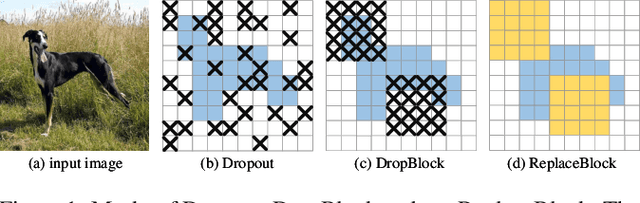
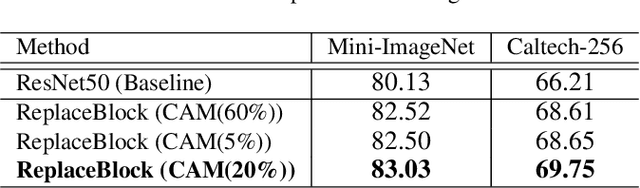
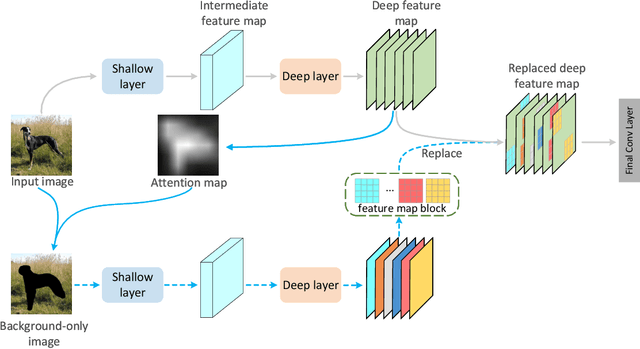
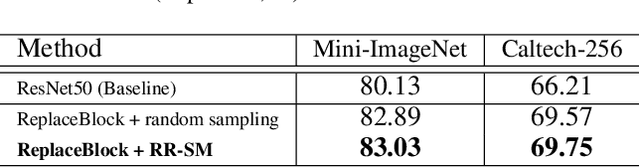
Attention mechanism, being frequently used to train networks for better feature representations, can effectively disentangle the target object from irrelevant objects in the background. Given an arbitrary image, we find that the background's irrelevant objects are most likely to occlude/block the target object. We propose, based on this finding, a ReplaceBlock to simulate the situations when the target object is partially occluded by the objects that are deemed as background. Specifically, ReplaceBlock erases the target object in the image, and then generates a feature map with only irrelevant objects and background by the model. Finally, some regions in the background feature map are used to replace some regions of the target object in the original image feature map. In this way, ReplaceBlock can effectively simulate the feature map of the occluded image. The experimental results show that ReplaceBlock works better than DropBlock in regularizing convolutional networks.