 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Labels for Self-Supervised Vision Transformer
Paper and Code
Jun 10, 2022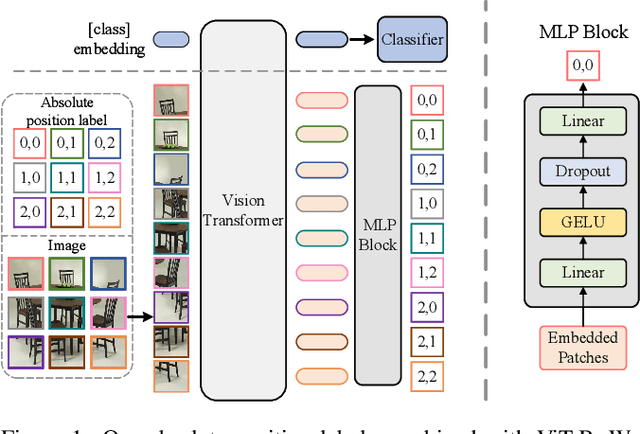
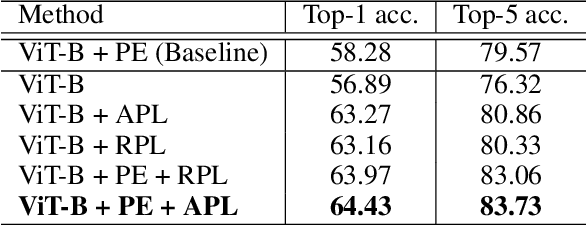
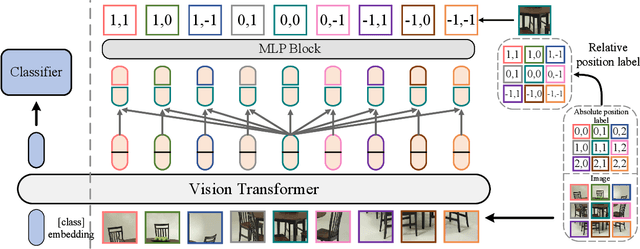
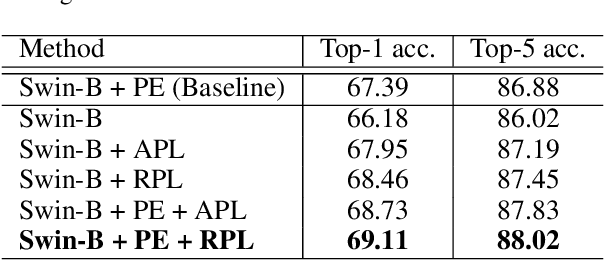
Position encoding is important for vision transformer (ViT) to capture the spatial structure of the input image. General efficacy has been proven in ViT. In our work we propose to train ViT to recognize the 2D position encoding of patches of the input image, this apparently simple task actually yields a meaningful self-supervisory task. Based on previous work on ViT position encoding, we propose two position labels dedicated to 2D images including absolute position and relative position. Our position labels can be easily plugged into transformer, combined with the various current ViT variants. It can work in two ways: 1.As an auxiliary training target for vanilla ViT (e.g., ViT-B and Swin-B) to improve model performance. 2. Combine the self-supervised ViT (e.g., MAE) to provide a more powerful self-supervised signal for semantic feature learning. Experiments demonstrate that solely due to the proposed self-supervised methods, Swin-B and ViT-B obtained improvements of 1.9% (top-1 Acc) and 5.6% (top-1 Acc) on Mini-ImageNet, respectively.