 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxially Expanded Windows for Local-Global Interaction in Vision Transformers
Paper and Code
Sep 19, 2022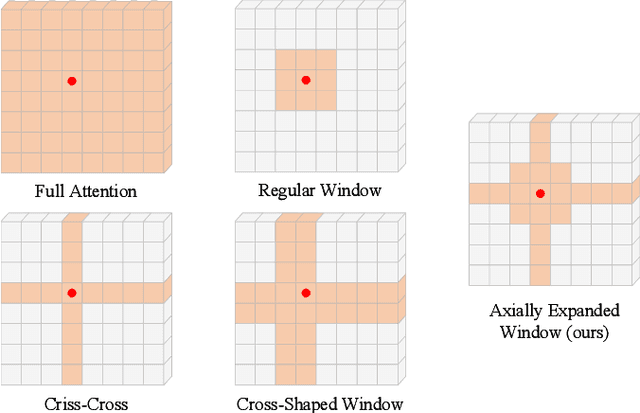
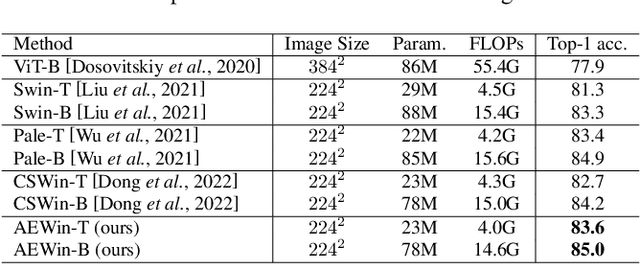
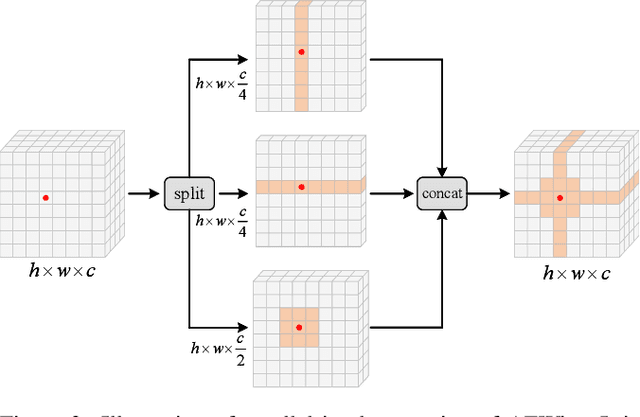
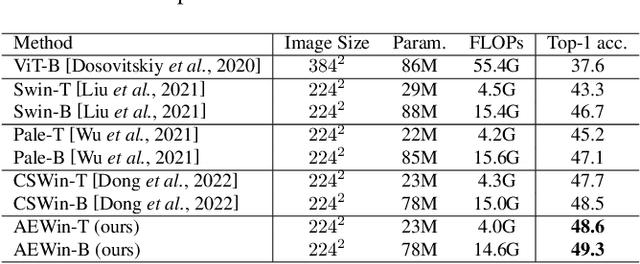
Recently, Transformers have shown promising performance in various vision tasks. A challenging issue in Transformer design is that global self-attention is very expensive to compute, especially for the high-resolution vision tasks. Local self-attention performs attention computation within a local region to improve its efficiency, which leads to their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. When observing a scene, humans usually focus on a local region while attending to non-attentional regions at coarse granularity. Based on this observation, we develop the axially expanded window self-attention mechanism that performs fine-grained self-attention within the local window and coarse-grained self-attention in the horizontal and vertical axes, and thus can effectively capturing both short- and long-range visual dependencies.