 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-grounded Adaptation Strategy for Vision-language Models: Building Unique Case-set for Screening Mammograms for Residents Training
May 30, 2024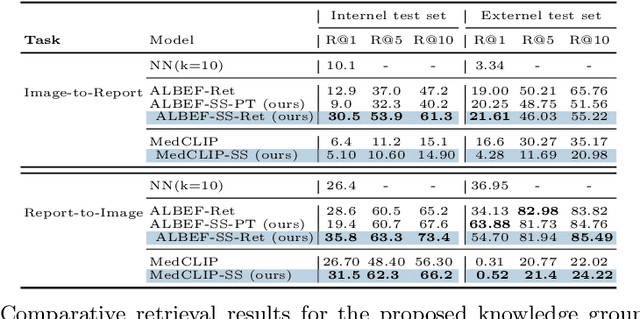
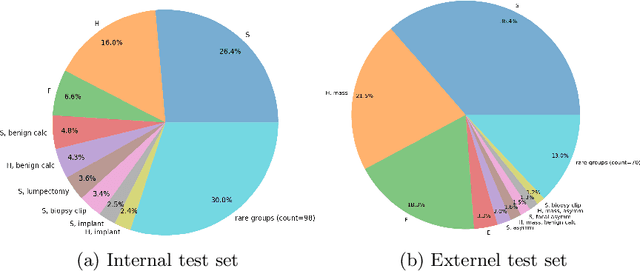
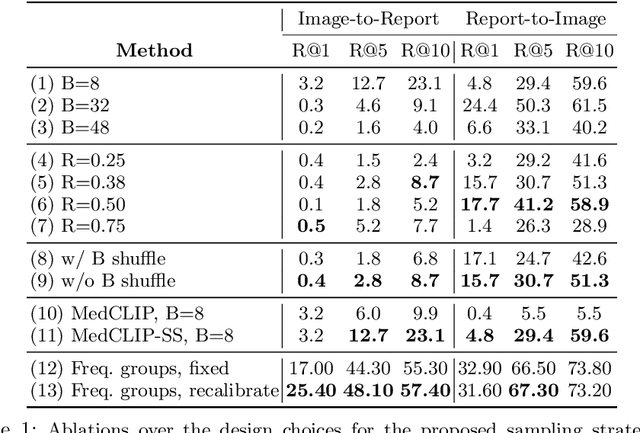
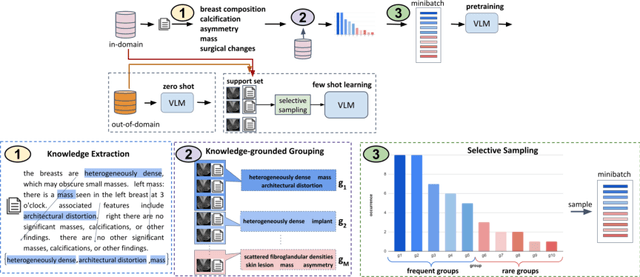
A visual-language model (VLM) pre-trained on natural images and text pairs poses a significant barrier when applied to medical contexts due to domain shift. Yet, adapting or fine-tuning these VLMs for medical use presents considerable hurdles, including domain misalignment, limited access to extensive datasets, and high-class imbalances. Hence, there is a pressing need for strategies to effectively adapt these VLMs to the medical domain, as such adaptations would prove immensely valuable in healthcare applications. In this study, we propose a framework designed to adeptly tailor VLMs to the medical domain, employing selective sampling and hard-negative mining techniques for enhanced performance in retrieval tasks. We validate the efficacy of our proposed approach by implementing it across two distinct VLMs: the in-domain VLM (MedCLIP) and out-of-domain VLMs (ALBEF). We assess the performance of these models both in their original off-the-shelf state and after undergoing our proposed training strategies, using two extensive datasets containing mammograms and their corresponding reports. Our evaluation spans zero-shot, few-shot, and supervised scenarios. Through our approach, we observe a notable enhancement in Recall@K performance for the image-text retrieval task.