 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of Deep Convolutional Neural Networks -- A Case-study on Open-source Chest Radiographs
Jul 11, 2020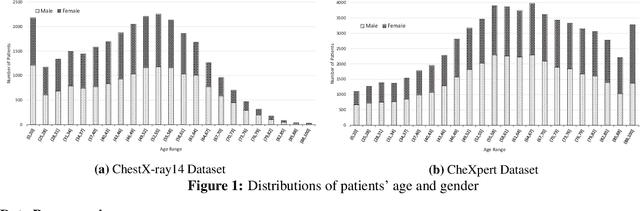
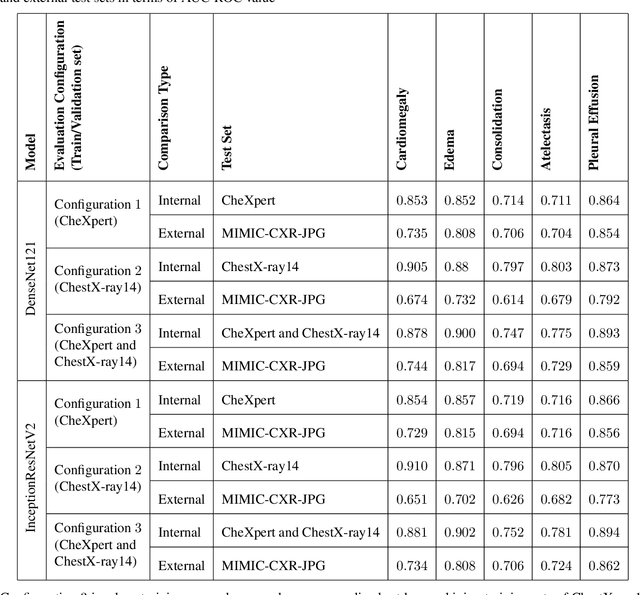
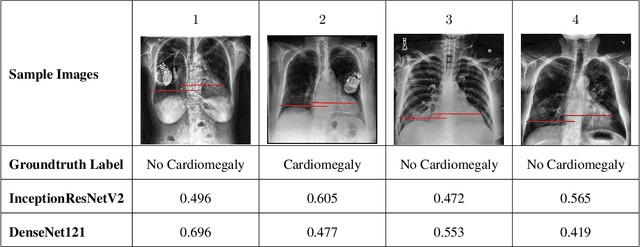
Deep Convolutional Neural Networks (DCNNs) have attracted extensive attention and been applied in many areas, including medical image analysis and clinical diagnosis. One major challenge is to conceive a DCNN model with remarkable performance on both internal and external data. We demonstrate that DCNNs may not generalize to new data, but increasing the quality and heterogeneity of the training data helps to improve the generalizibility factor. We use InceptionResNetV2 and DenseNet121 architectures to predict the risk of 5 common chest pathologies. The experiments were conducted on three publicly available databases: CheXpert, ChestX-ray14, and MIMIC Chest Xray JPG. The results show the internal performance of each of the 5 pathologies outperformed external performance on both of the models. Moreover, our strategy of exposing the models to a mix of different datasets during the training phase helps to improve model performance on the external dataset.
Was there COVID-19 back in 2012? Challenge for AI in Diagnosis with Similar Indications
Jun 23, 2020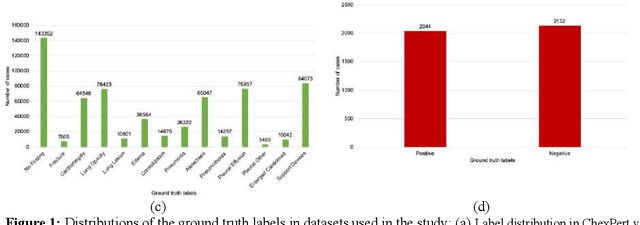
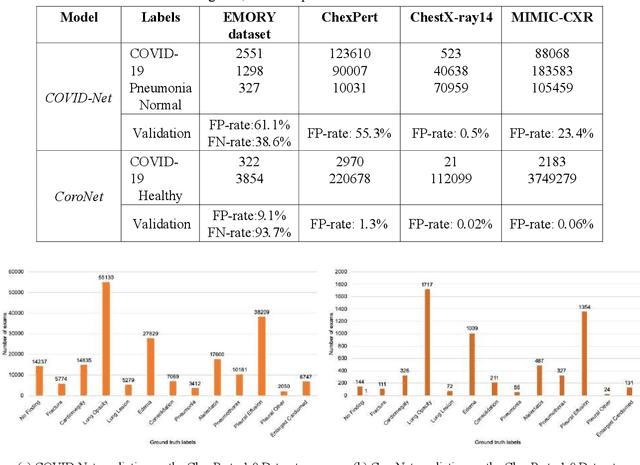
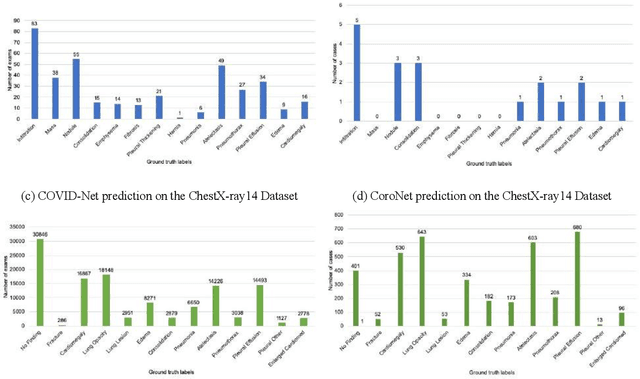

Purpose: Since the recent COVID-19 outbreak, there has been an avalanche of research papers applying deep learning based image processing to chest radiographs for detection of the disease. To test the performance of the two top models for CXR COVID-19 diagnosis on external datasets to assess model generalizability. Methods: In this paper, we present our argument regarding the efficiency and applicability of existing deep learning models for COVID-19 diagnosis. We provide results from two popular models - COVID-Net and CoroNet evaluated on three publicly available datasets and an additional institutional dataset collected from EMORY Hospital between January and May 2020, containing patients tested for COVID-19 infection using RT-PCR. Results: There is a large false positive rate (FPR) for COVID-Net on both ChexPert (55.3%) and MIMIC-CXR (23.4%) dataset. On the EMORY Dataset, COVID-Net has 61.4% sensitivity, 0.54 F1-score and 0.49 precision value. The FPR of the CoroNet model is significantly lower across all the datasets as compared to COVID-Net - EMORY(9.1%), ChexPert (1.3%), ChestX-ray14 (0.02%), MIMIC-CXR (0.06%). Conclusion: The models reported good to excellent performance on their internal datasets, however we observed from our testing that their performance dramatically worsened on external data. This is likely from several causes including overfitting models due to lack of appropriate control patients and ground truth labels. The fourth institutional dataset was labeled using RT-PCR, which could be positive without radiographic findings and vice versa. Therefore, a fusion model of both clinical and radiographic data may have better performance and generalization.