 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards trustworthy seizure onset detection using workflow notes
Jun 14, 2023



A major barrier to deploying healthcare AI models is their trustworthiness. One form of trustworthiness is a model's robustness across different subgroups: while existing models may exhibit expert-level performance on aggregate metrics, they often rely on non-causal features, leading to errors in hidden subgroups. To take a step closer towards trustworthy seizure onset detection from EEG, we propose to leverage annotations that are produced by healthcare personnel in routine clinical workflows -- which we refer to as workflow notes -- that include multiple event descriptions beyond seizures. Using workflow notes, we first show that by scaling training data to an unprecedented level of 68,920 EEG hours, seizure onset detection performance significantly improves (+12.3 AUROC points) compared to relying on smaller training sets with expensive manual gold-standard labels. Second, we reveal that our binary seizure onset detection model underperforms on clinically relevant subgroups (e.g., up to a margin of 6.5 AUROC points between pediatrics and adults), while having significantly higher false positives on EEG clips showing non-epileptiform abnormalities compared to any EEG clip (+19 FPR points). To improve model robustness to hidden subgroups, we train a multilabel model that classifies 26 attributes other than seizures, such as spikes, slowing, and movement artifacts. We find that our multilabel model significantly improves overall seizure onset detection performance (+5.9 AUROC points) while greatly improving performance among subgroups (up to +8.3 AUROC points), and decreases false positives on non-epileptiform abnormalities by 8 FPR points. Finally, we propose a clinical utility metric based on false positives per 24 EEG hours and find that our multilabel model improves this clinical utility metric by a factor of 2x across different clinical settings.
Spatiotemporal Modeling of Multivariate Signals With Graph Neural Networks and Structured State Space Models
Nov 21, 2022Multivariate signals are prevalent in various domains, such as healthcare, transportation systems, and space sciences. Modeling spatiotemporal dependencies in multivariate signals is challenging due to (1) long-range temporal dependencies and (2) complex spatial correlations between sensors. To address these challenges, we propose representing multivariate signals as graphs and introduce GraphS4mer, a general graph neural network (GNN) architecture that captures both spatial and temporal dependencies in multivariate signals. Specifically, (1) we leverage Structured State Spaces model (S4), a state-of-the-art sequence model, to capture long-term temporal dependencies and (2) we propose a graph structure learning layer in GraphS4mer to learn dynamically evolving graph structures in the data. We evaluate our proposed model on three distinct tasks and show that GraphS4mer consistently improves over existing models, including (1) seizure detection from electroencephalography signals, outperforming a previous GNN with self-supervised pretraining by 3.1 points in AUROC; (2) sleep staging from polysomnography signals, a 4.1 points improvement in macro-F1 score compared to existing sleep staging models; and (3) traffic forecasting, reducing MAE by 8.8% compared to existing GNNs and by 1.4% compared to Transformer-based models.
Multimodal spatiotemporal graph neural networks for improved prediction of 30-day all-cause hospital readmission
Apr 14, 2022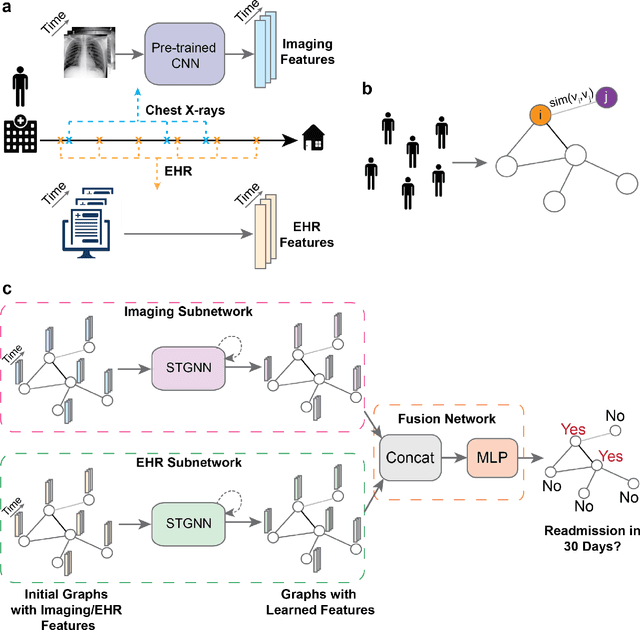
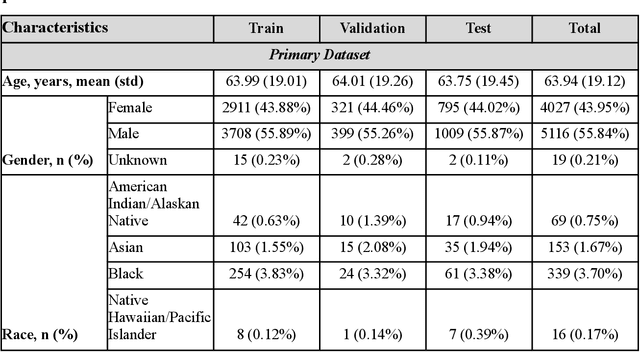
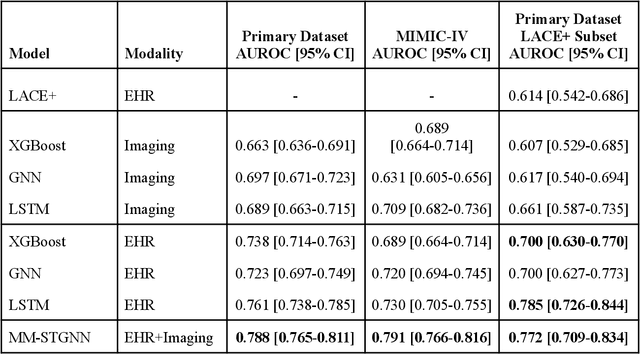
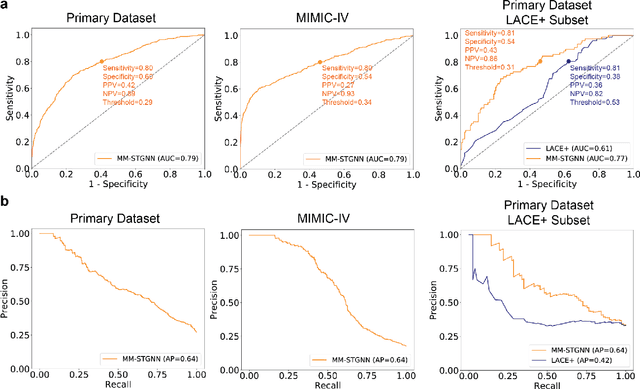
Measures to predict 30-day readmission are considered an important quality factor for hospitals as accurate predictions can reduce the overall cost of care by identifying high risk patients before they are discharged. While recent deep learning-based studies have shown promising empirical results on readmission prediction, several limitations exist that may hinder widespread clinical utility, such as (a) only patients with certain conditions are considered, (b) existing approaches do not leverage data temporality, (c) individual admissions are assumed independent of each other, which is unrealistic, (d) prior studies are usually limited to single source of data and single center data. To address these limitations, we propose a multimodal, modality-agnostic spatiotemporal graph neural network (MM-STGNN) for prediction of 30-day all-cause hospital readmission that fuses multimodal in-patient longitudinal data. By training and evaluating our methods using longitudinal chest radiographs and electronic health records from two independent centers, we demonstrate that MM-STGNN achieves AUROC of 0.79 on both primary and external datasets. Furthermore, MM-STGNN significantly outperforms the current clinical reference standard, LACE+ score (AUROC=0.61), on the primary dataset. For subset populations of patients with heart and vascular disease, our model also outperforms baselines on predicting 30-day readmission (e.g., 3.7 point improvement in AUROC in patients with heart disease). Lastly, qualitative model interpretability analysis indicates that while patients' primary diagnoses were not explicitly used to train the model, node features crucial for model prediction directly reflect patients' primary diagnoses. Importantly, our MM-STGNN is agnostic to node feature modalities and could be utilized to integrate multimodal data for triaging patients in various downstream resource allocation tasks.
Double Descent Optimization Pattern and Aliasing: Caveats of Noisy Labels
Jun 03, 2021

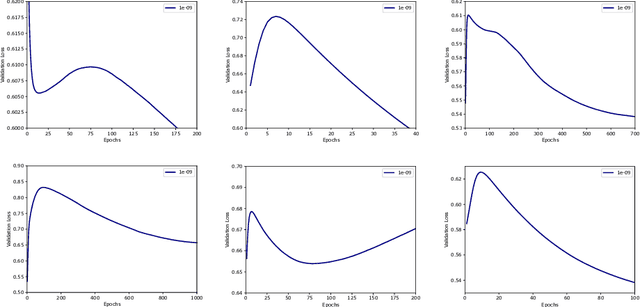
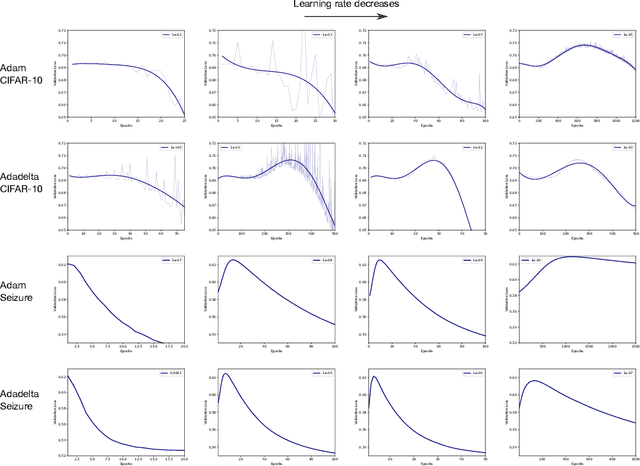
Optimization plays a key role in the training of deep neural networks. Deciding when to stop training can have a substantial impact on the performance of the network during inference. Under certain conditions, the generalization error can display a double descent pattern during training: the learning curve is non-monotonic and seemingly diverges before converging again after additional epochs. This optimization pattern can lead to early stopping procedures to stop training before the second convergence and consequently select a suboptimal set of parameters for the network, with worse performance during inference. In this work, in addition to confirming that double descent occurs with small datasets and noisy labels as evidenced by others, we show that noisy labels must be present both in the training and generalization sets to observe a double descent pattern. We also show that the learning rate has an influence on double descent, and study how different optimizers and optimizer parameters influence the apparition of double descent. Finally, we show that increasing the learning rate can create an aliasing effect that masks the double descent pattern without suppressing it. We study this phenomenon through extensive experiments on variants of CIFAR-10 and show that they translate to a real world application: the forecast of seizure events in epileptic patients from continuous electroencephalographic recordings.
Automated Seizure Detection and Seizure Type Classification From Electroencephalography With a Graph Neural Network and Self-Supervised Pre-Training
Apr 16, 2021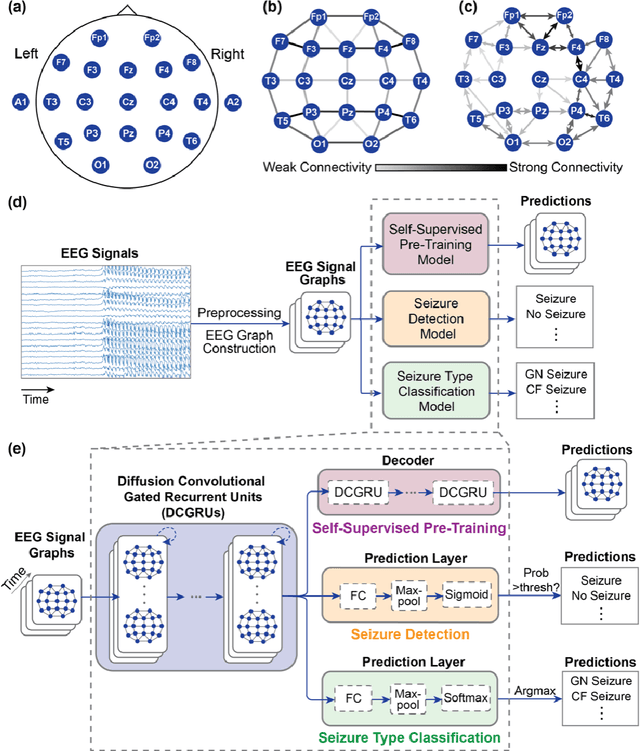
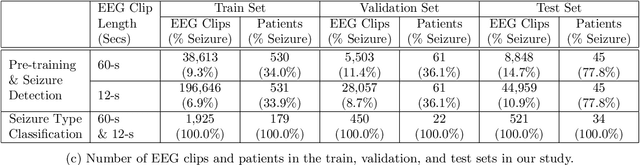
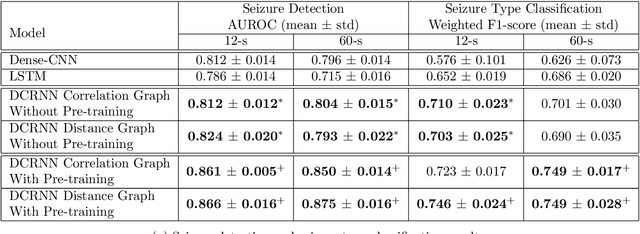
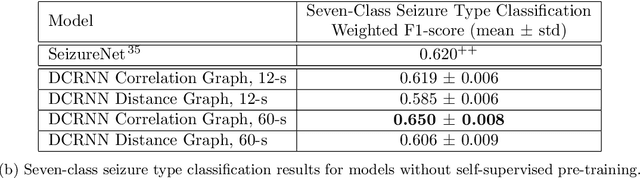
Automated seizure detection and classification from electroencephalography (EEG) can greatly improve the diagnosis and treatment of seizures. While prior studies mainly used convolutional neural networks (CNNs) that assume image-like structure in EEG signals or spectrograms, this modeling choice does not reflect the natural geometry of or connectivity between EEG electrodes. In this study, we propose modeling EEGs as graphs and present a graph neural network for automated seizure detection and classification. In addition, we leverage unlabeled EEG data using a self-supervised pre-training strategy. Our graph model with self-supervised pre-training significantly outperforms previous state-of-the-art CNN and Long Short-Term Memory (LSTM) models by 6.3 points (7.8%) in Area Under the Receiver Operating Characteristic curve (AUROC) for seizure detection and 6.3 points (9.2%) in weighted F1-score for seizure type classification. Ablation studies show that our graph-based modeling approach significantly outperforms existing CNN or LSTM models, and that self-supervision helps further improve the model performance. Moreover, we find that self-supervised pre-training substantially improves model performance on combined tonic seizures, a low-prevalence seizure type. Furthermore, our model interpretability analysis suggests that our model is better at identifying seizure regions compared to an existing CNN. In summary, our graph-based modeling approach integrates domain knowledge about EEG, sets a new state-of-the-art for seizure detection and classification on a large public dataset (5,499 EEG files), and provides better ability to identify seizure regions.
Inaccurate Supervision of Neural Networks with Incorrect Labels: Application to Epilepsy
Dec 01, 2020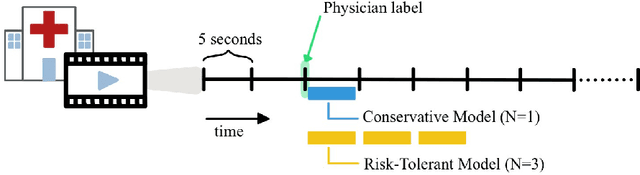
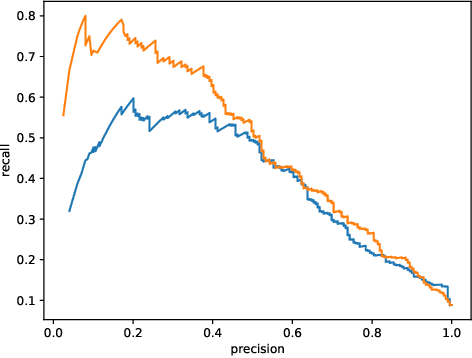
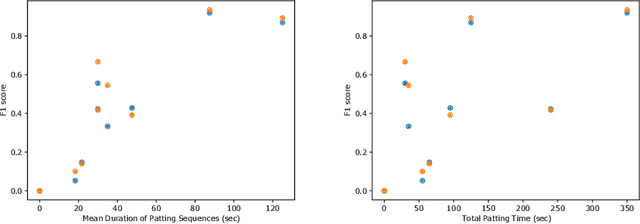
This work describes multiple weak supervision strategies for video processing with neural networks in the context of seizure detection. To study seizure onset, we have designed automated methods to detect seizures from electroencephalography (EEG), a modality used for recording electrical brain activity. However, the EEG signal alone is sometimes not enough for existing detection methods to discriminate seizure from artifacts having a similar signal on EEG. For example, such artifacts could be triggered by patting, rocking or suctioning in the case of neonates. In this article, we addressed this problem by automatically detecting an example artifact -- patting of neonates -- from continuous video recordings of neonates acquired during clinical routine. We computed frame-to-frame cross-correlation matrices to isolate patterns showing repetitive movements indicative of patting of the patient. Next, a convolutional neural network was trained to classify whether these matrices contained patting events using weak training labels -- noisy labels generated during daily clinical procedure. The labels were considered weak as they were sometimes incorrect. We investigated whether networks trained with more samples, containing more uncertain and weak labels, could achieve a higher performance. Our results showed that, in the case of patting detection, such networks could achieve a higher recall, without sacrificing precision. These networks focused on areas of the cross-correlation matrices that were more meaningful to the task. More generally, our work gives insights into building more accurate models from weakly labelled time sequences.
Data Valuation for Medical Imaging Using Shapley Value: Application on A Large-scale Chest X-ray Dataset
Oct 15, 2020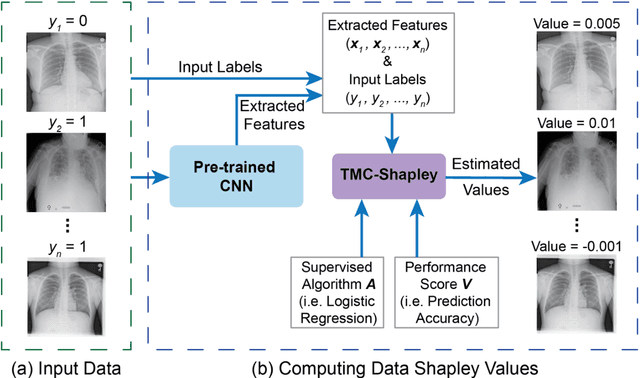
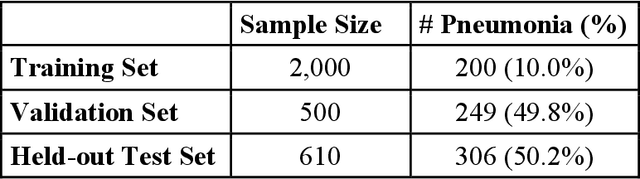
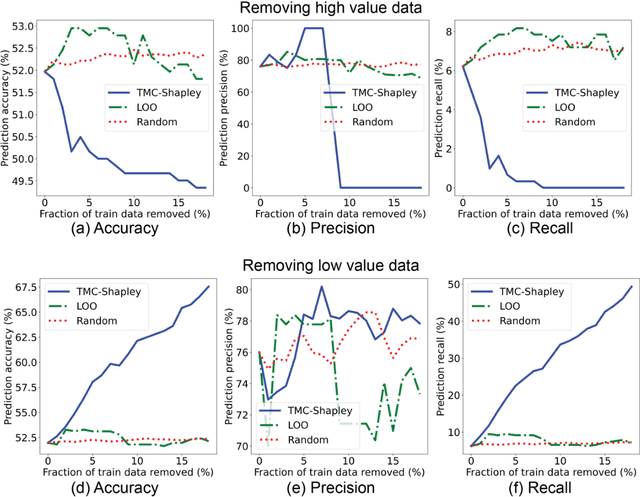

The reliability of machine learning models can be compromised when trained on low quality data. Many large-scale medical imaging datasets contain low quality labels extracted from sources such as medical reports. Moreover, images within a dataset may have heterogeneous quality due to artifacts and biases arising from equipment or measurement errors. Therefore, algorithms that can automatically identify low quality data are highly desired. In this study, we used data Shapley, a data valuation metric, to quantify the value of training data to the performance of a pneumonia detection algorithm in a large chest X-ray dataset. We characterized the effectiveness of data Shapley in identifying low quality versus valuable data for pneumonia detection. We found that removing training data with high Shapley values decreased the pneumonia detection performance, whereas removing data with low Shapley values improved the model performance. Furthermore, there were more mislabeled examples in low Shapley value data and more true pneumonia cases in high Shapley value data. Our results suggest that low Shapley value indicates mislabeled or poor quality images, whereas high Shapley value indicates data that are valuable for pneumonia detection. Our method can serve as a framework for using data Shapley to denoise large-scale medical imaging datasets.
Pose-Invariant Object Recognition for Event-Based Vision with Slow-ELM
Mar 19, 2019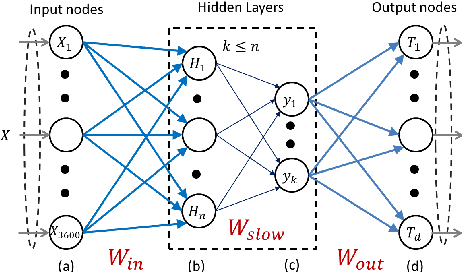
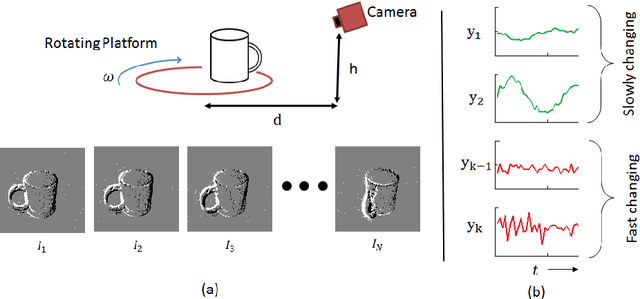
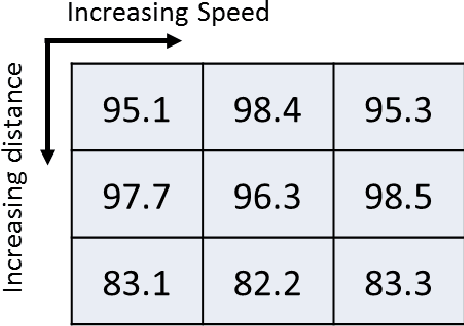
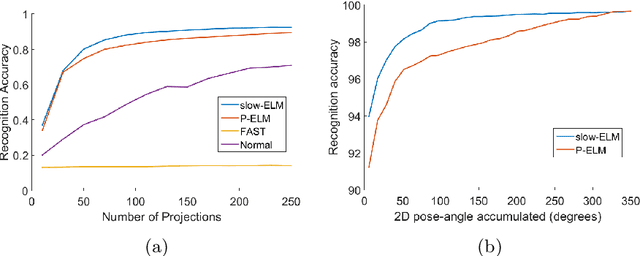
Neuromorphic image sensors produce activity-driven spiking output at every pixel. These low-power consuming imagers which encode visual change information in the form of spikes help reduce computational overhead and realize complex real-time systems; object recognition and pose-estimation to name a few. However, there exists a lack of algorithms in event-based vision aimed towards capturing invariance to transformations. In this work, we propose a methodology for recognizing objects invariant to their pose with the Dynamic Vision Sensor (DVS). A novel slow-ELM architecture is proposed which combines the effectiveness of Extreme Learning Machines and Slow Feature Analysis. The system, tested on an Intel Core i5-4590 CPU, can perform 10,000 classifications per second and achieves 1% classification error for 8 objects with views accumulated over 90 degrees of 2D pose.
Spatiotemporal Feature Learning for Event-Based Vision
Mar 16, 2019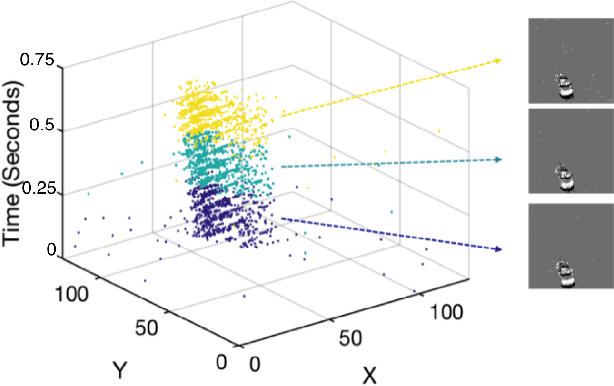
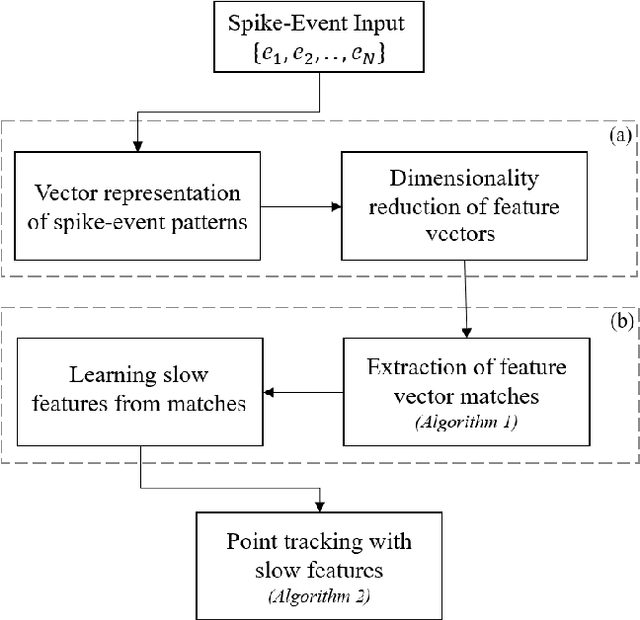
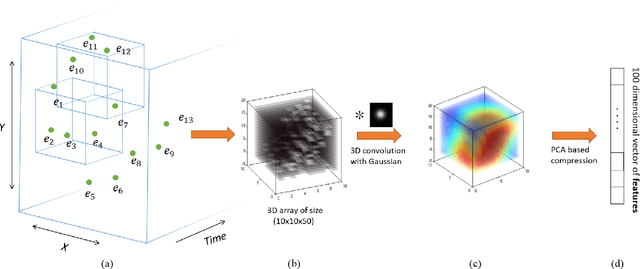
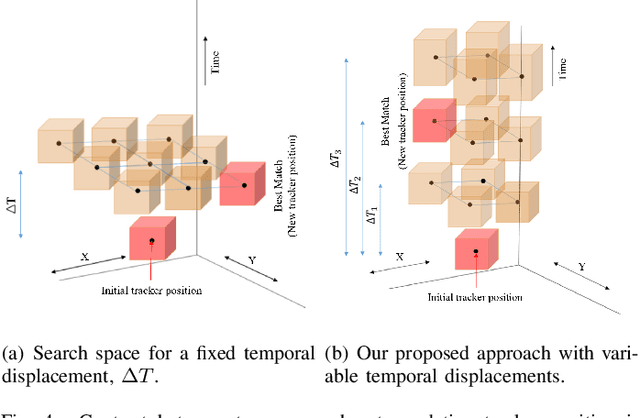
Unlike conventional frame-based sensors, event-based visual sensors output information through spikes at a high temporal resolution. By only encoding changes in pixel intensity, they showcase a low-power consuming, low-latency approach to visual information sensing. To use this information for higher sensory tasks like object recognition and tracking, an essential simplification step is the extraction and learning of features. An ideal feature descriptor must be robust to changes involving (i) local transformations and (ii) re-appearances of a local event pattern. To that end, we propose a novel spatiotemporal feature representation learning algorithm based on slow feature analysis (SFA). Using SFA, smoothly changing linear projections are learnt which are robust to local visual transformations. In order to determine if the features can learn to be invariant to various visual transformations, feature point tracking tasks are used for evaluation. Extensive experiments across two datasets demonstrate the adaptability of the spatiotemporal feature learner to translation, scaling and rotational transformations of the feature points. More importantly, we find that the obtained feature representations are able to exploit the high temporal resolution of such event-based cameras in generating better feature tracks.