 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Image Augmentations for Siamese Representation Learning with Chest X-Rays
Jan 30, 2023



Image augmentations are quintessential for effective visual representation learning across self-supervised learning techniques. While augmentation strategies for natural imaging have been studied extensively, medical images are vastly different from their natural counterparts. Thus, it is unknown whether common augmentation strategies employed in Siamese representation learning generalize to medical images and to what extent. To address this challenge, in this study, we systematically assess the effect of various augmentations on the quality and robustness of the learned representations. We train and evaluate Siamese Networks for abnormality detection on chest X-Rays across three large datasets (MIMIC-CXR, CheXpert and VinDR-CXR). We investigate the efficacy of the learned representations through experiments involving linear probing, fine-tuning, zero-shot transfer, and data efficiency. Finally, we identify a set of augmentations that yield robust representations that generalize well to both out-of-distribution data and diseases, while outperforming supervised baselines using just zero-shot transfer and linear probes by up to 20%.
Data-Limited Tissue Segmentation using Inpainting-Based Self-Supervised Learning
Oct 14, 2022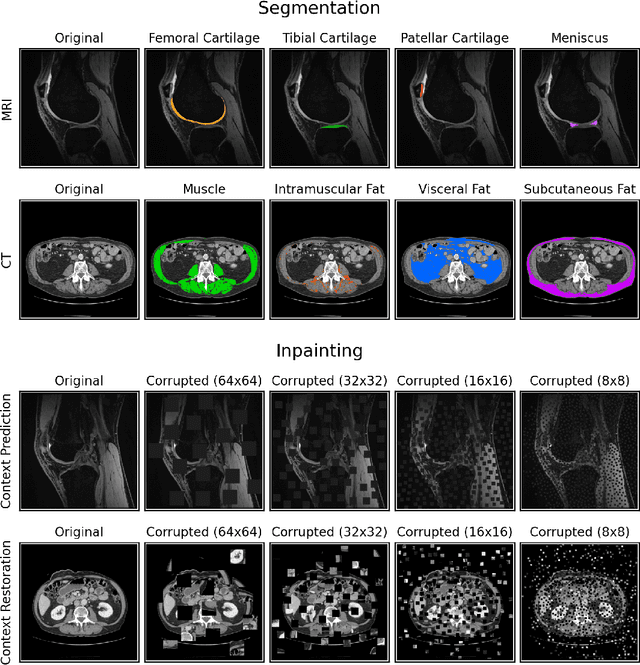
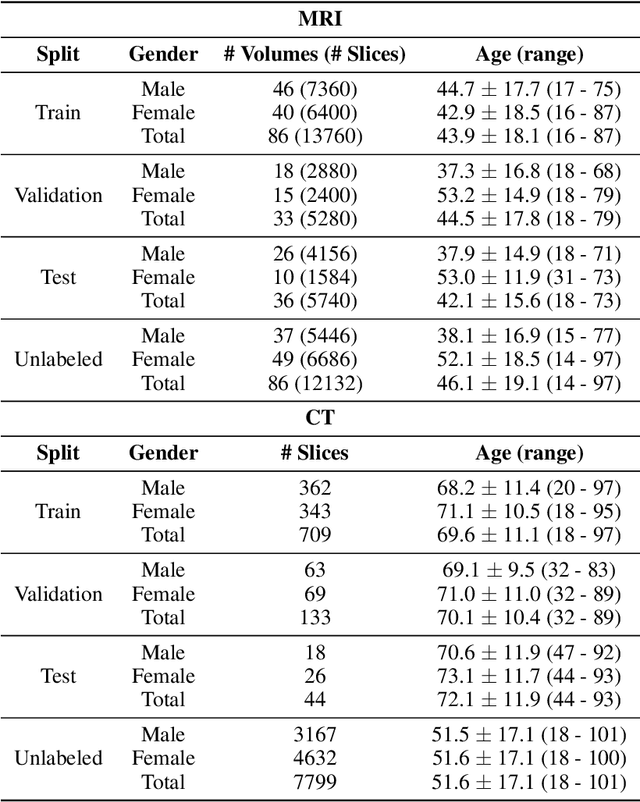
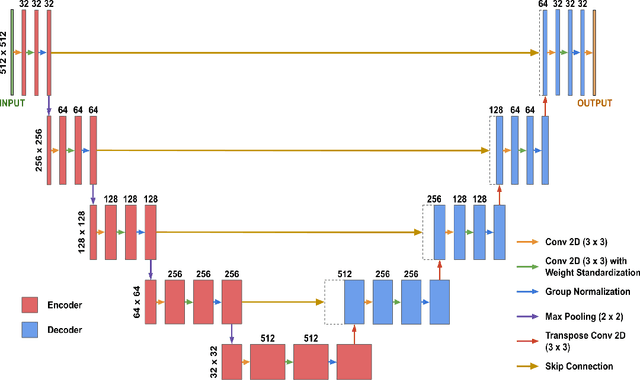
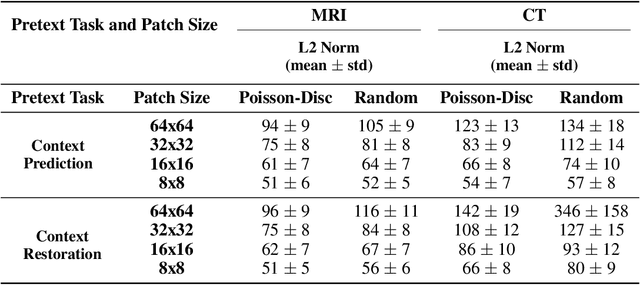
Although supervised learning has enabled high performance for image segmentation, it requires a large amount of labeled training data, which can be difficult to obtain in the medical imaging field. Self-supervised learning (SSL) methods involving pretext tasks have shown promise in overcoming this requirement by first pretraining models using unlabeled data. In this work, we evaluate the efficacy of two SSL methods (inpainting-based pretext tasks of context prediction and context restoration) for CT and MRI image segmentation in label-limited scenarios, and investigate the effect of implementation design choices for SSL on downstream segmentation performance. We demonstrate that optimally trained and easy-to-implement inpainting-based SSL segmentation models can outperform classically supervised methods for MRI and CT tissue segmentation in label-limited scenarios, for both clinically-relevant metrics and the traditional Dice score.
TRUST-LAPSE: An Explainable & Actionable Mistrust Scoring Framework for Model Monitoring
Jul 22, 2022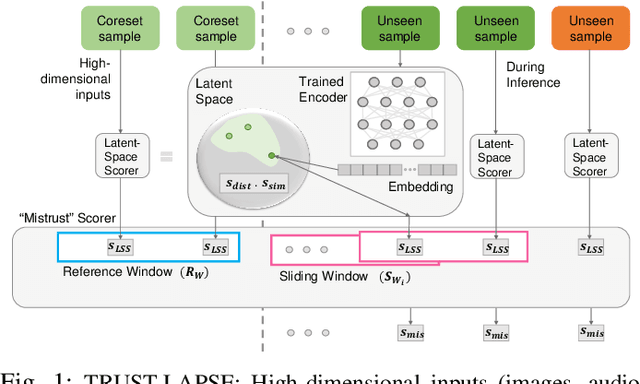
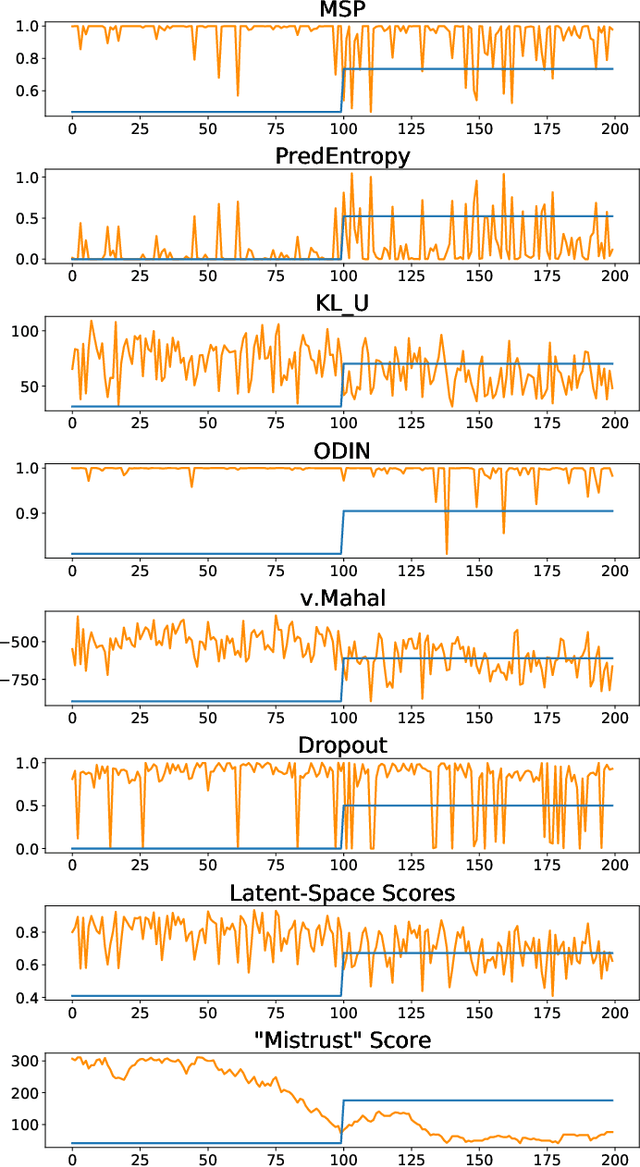


Continuous monitoring of trained ML models to determine when their predictions should and should not be trusted is essential for their safe deployment. Such a framework ought to be high-performing, explainable, post-hoc and actionable. We propose TRUST-LAPSE, a "mistrust" scoring framework for continuous model monitoring. We assess the trustworthiness of each input sample's model prediction using a sequence of latent-space embeddings. Specifically, (a) our latent-space mistrust score estimates mistrust using distance metrics (Mahalanobis distance) and similarity metrics (cosine similarity) in the latent-space and (b) our sequential mistrust score determines deviations in correlations over the sequence of past input representations in a non-parametric, sliding-window based algorithm for actionable continuous monitoring. We evaluate TRUST-LAPSE via two downstream tasks: (1) distributionally shifted input detection and (2) data drift detection, across diverse domains -- audio & vision using public datasets and further benchmark our approach on challenging, real-world electroencephalograms (EEG) datasets for seizure detection. Our latent-space mistrust scores achieve state-of-the-art results with AUROCs of 84.1 (vision), 73.9 (audio), 77.1 (clinical EEGs), outperforming baselines by over 10 points. We expose critical failures in popular baselines that remain insensitive to input semantic content, rendering them unfit for real-world model monitoring. We show that our sequential mistrust scores achieve high drift detection rates: over 90% of the streams show < 20% error for all domains. Through extensive qualitative and quantitative evaluations, we show that our mistrust scores are more robust and provide explainability for easy adoption into practice.
Double Descent Optimization Pattern and Aliasing: Caveats of Noisy Labels
Jun 03, 2021

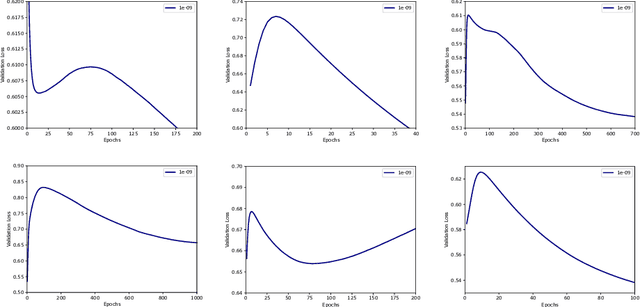
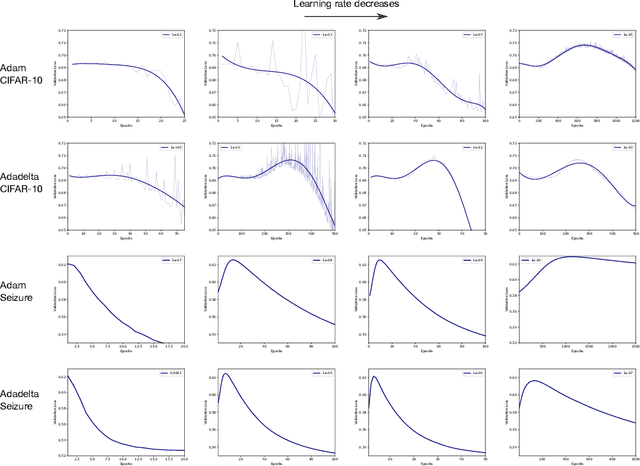
Optimization plays a key role in the training of deep neural networks. Deciding when to stop training can have a substantial impact on the performance of the network during inference. Under certain conditions, the generalization error can display a double descent pattern during training: the learning curve is non-monotonic and seemingly diverges before converging again after additional epochs. This optimization pattern can lead to early stopping procedures to stop training before the second convergence and consequently select a suboptimal set of parameters for the network, with worse performance during inference. In this work, in addition to confirming that double descent occurs with small datasets and noisy labels as evidenced by others, we show that noisy labels must be present both in the training and generalization sets to observe a double descent pattern. We also show that the learning rate has an influence on double descent, and study how different optimizers and optimizer parameters influence the apparition of double descent. Finally, we show that increasing the learning rate can create an aliasing effect that masks the double descent pattern without suppressing it. We study this phenomenon through extensive experiments on variants of CIFAR-10 and show that they translate to a real world application: the forecast of seizure events in epileptic patients from continuous electroencephalographic recordings.
Inaccurate Supervision of Neural Networks with Incorrect Labels: Application to Epilepsy
Dec 01, 2020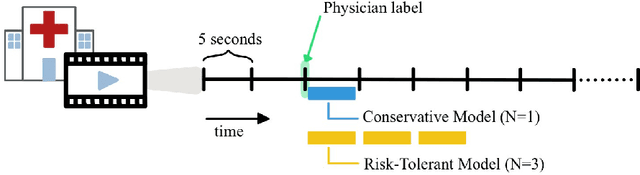
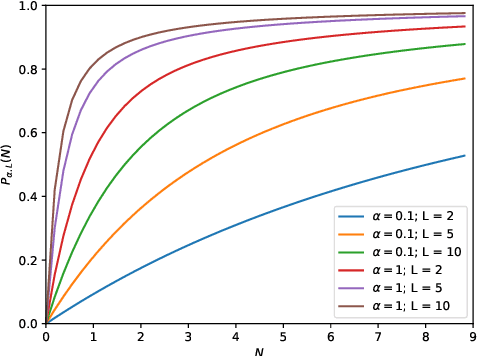
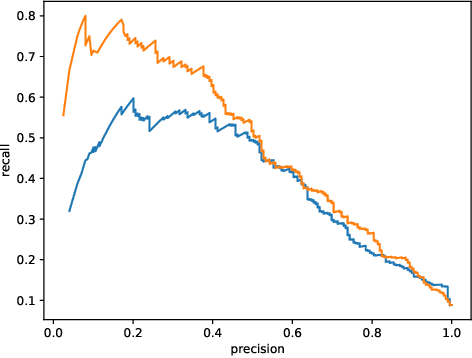
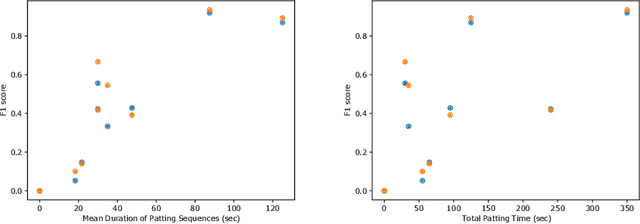
This work describes multiple weak supervision strategies for video processing with neural networks in the context of seizure detection. To study seizure onset, we have designed automated methods to detect seizures from electroencephalography (EEG), a modality used for recording electrical brain activity. However, the EEG signal alone is sometimes not enough for existing detection methods to discriminate seizure from artifacts having a similar signal on EEG. For example, such artifacts could be triggered by patting, rocking or suctioning in the case of neonates. In this article, we addressed this problem by automatically detecting an example artifact -- patting of neonates -- from continuous video recordings of neonates acquired during clinical routine. We computed frame-to-frame cross-correlation matrices to isolate patterns showing repetitive movements indicative of patting of the patient. Next, a convolutional neural network was trained to classify whether these matrices contained patting events using weak training labels -- noisy labels generated during daily clinical procedure. The labels were considered weak as they were sometimes incorrect. We investigated whether networks trained with more samples, containing more uncertain and weak labels, could achieve a higher performance. Our results showed that, in the case of patting detection, such networks could achieve a higher recall, without sacrificing precision. These networks focused on areas of the cross-correlation matrices that were more meaningful to the task. More generally, our work gives insights into building more accurate models from weakly labelled time sequences.