 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Descent Optimization Pattern and Aliasing: Caveats of Noisy Labels
Paper and Code
Jun 03, 2021

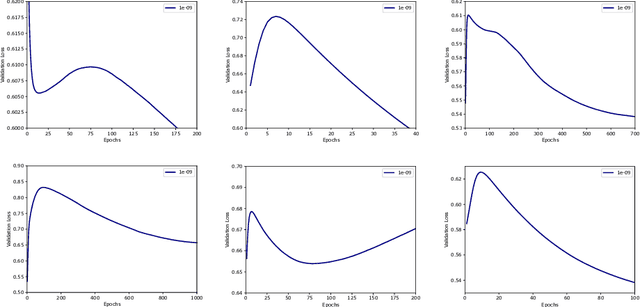
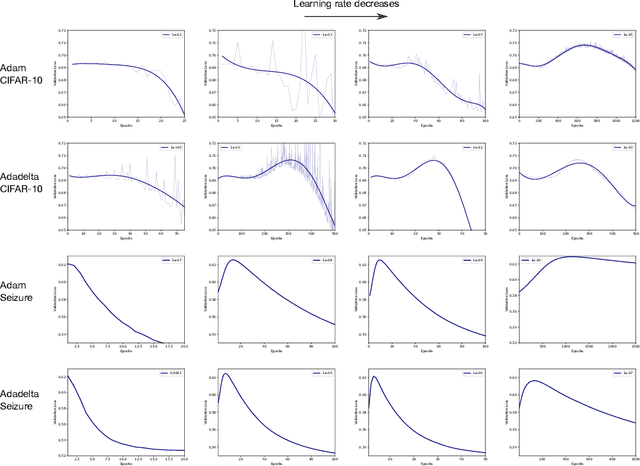
Optimization plays a key role in the training of deep neural networks. Deciding when to stop training can have a substantial impact on the performance of the network during inference. Under certain conditions, the generalization error can display a double descent pattern during training: the learning curve is non-monotonic and seemingly diverges before converging again after additional epochs. This optimization pattern can lead to early stopping procedures to stop training before the second convergence and consequently select a suboptimal set of parameters for the network, with worse performance during inference. In this work, in addition to confirming that double descent occurs with small datasets and noisy labels as evidenced by others, we show that noisy labels must be present both in the training and generalization sets to observe a double descent pattern. We also show that the learning rate has an influence on double descent, and study how different optimizers and optimizer parameters influence the apparition of double descent. Finally, we show that increasing the learning rate can create an aliasing effect that masks the double descent pattern without suppressing it. We study this phenomenon through extensive experiments on variants of CIFAR-10 and show that they translate to a real world application: the forecast of seizure events in epileptic patients from continuous electroencephalographic recordings.