 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022
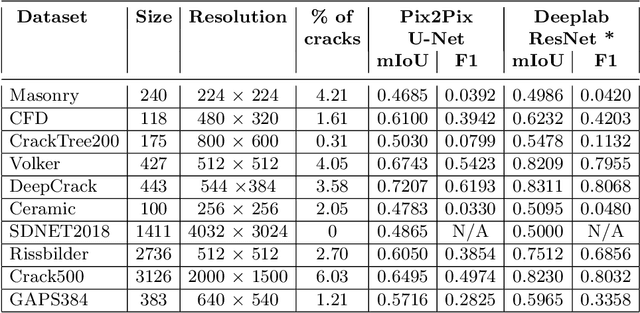

The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.
Automated Detection of Patients in Hospital Video Recordings
Nov 28, 2021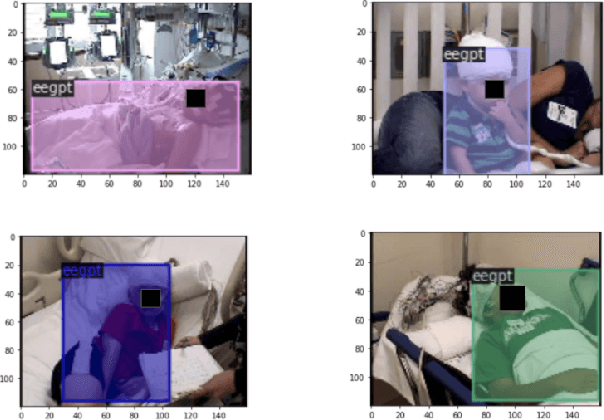
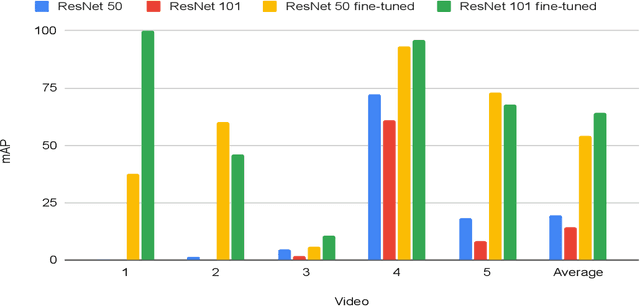
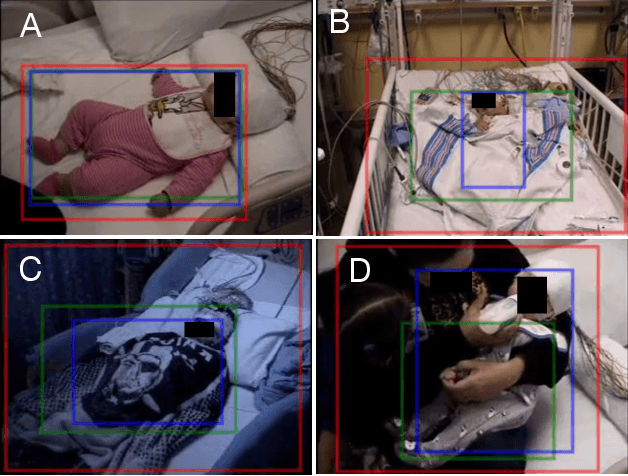
In a clinical setting, epilepsy patients are monitored via video electroencephalogram (EEG) tests. A video EEG records what the patient experiences on videotape while an EEG device records their brainwaves. Currently, there are no existing automated methods for tracking the patient's location during a seizure, and video recordings of hospital patients are substantially different from publicly available video benchmark datasets. For example, the camera angle can be unusual, and patients can be partially covered with bedding sheets and electrode sets. Being able to track a patient in real-time with video EEG would be a promising innovation towards improving the quality of healthcare. Specifically, an automated patient detection system could supplement clinical oversight and reduce the resource-intensive efforts of nurses and doctors who need to continuously monitor patients. We evaluate an ImageNet pre-trained Mask R-CNN, a standard deep learning model for object detection, on the task of patient detection using our own curated dataset of 45 videos of hospital patients. The dataset was aggregated and curated for this work. We show that without fine-tuning, ImageNet pre-trained Mask R-CNN models perform poorly on such data. By fine-tuning the models with a subset of our dataset, we observe a substantial improvement in patient detection performance, with a mean average precision of 0.64. We show that the results vary substantially depending on the video clip.
Double Descent Optimization Pattern and Aliasing: Caveats of Noisy Labels
Jun 03, 2021

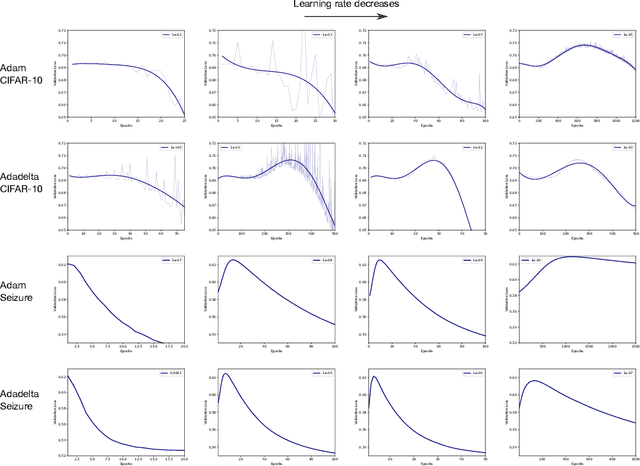
Optimization plays a key role in the training of deep neural networks. Deciding when to stop training can have a substantial impact on the performance of the network during inference. Under certain conditions, the generalization error can display a double descent pattern during training: the learning curve is non-monotonic and seemingly diverges before converging again after additional epochs. This optimization pattern can lead to early stopping procedures to stop training before the second convergence and consequently select a suboptimal set of parameters for the network, with worse performance during inference. In this work, in addition to confirming that double descent occurs with small datasets and noisy labels as evidenced by others, we show that noisy labels must be present both in the training and generalization sets to observe a double descent pattern. We also show that the learning rate has an influence on double descent, and study how different optimizers and optimizer parameters influence the apparition of double descent. Finally, we show that increasing the learning rate can create an aliasing effect that masks the double descent pattern without suppressing it. We study this phenomenon through extensive experiments on variants of CIFAR-10 and show that they translate to a real world application: the forecast of seizure events in epileptic patients from continuous electroencephalographic recordings.
QEML : Using Quantum Computing to Enhance ML Classifiers and Feature Spaces
Mar 22, 2020Machine learning and quantum computing are two technologies that are causing a paradigm shift in the performance and behavior of certain algorithms, achieving previously unattainable results. Machine learning (kernel classification) has become ubiquitous as the forefront method for pattern recognition and has been shown to have numerous societal applications. While not yet fault-tolerant, Quantum computing is an entirely new method of computation due to its exploitation of quantum phenomena such as superposition and entanglement. While current machine learning classifiers like the Support Vector Machine are seeing gradual improvements in performance, there are still severe limitations on the efficiency and scalability of such algorithms due to a limited feature space which makes the kernel functions computationally expensive to estimate. By integrating quantum circuits into traditional ML, we may solve this problem through the use of quantum feature space, a technique that improves existing Machine Learning algorithms through the use of parallelization and the reduction of the storage space from exponential to linear. This research expands on this concept of the Hilbert space and applies it for classical machine learning by implementing the quantum-enhanced version of the K nearest neighbors algorithm. This paper first understands the mathematical intuition for the implementation of quantum feature space and successfully simulates quantum properties and algorithms like Fidelity and Grover's Algorithm via the Qiskit python library and the IBM Quantum Experience platform. The primary experiment of this research is to build a noisy variational quantum circuit KNN (QKNN) which mimics the classification methods of a traditional KNN classifier. The QKNN utilizes the distance metric of Hamming Distance and is able to outperform the existing KNN on a 10-dimensional Breast Cancer dataset.
Urban Driving with Conditional Imitation Learning
Dec 05, 2019



Hand-crafting generalised decision-making rules for real-world urban autonomous driving is hard. Alternatively, learning behaviour from easy-to-collect human driving demonstrations is appealing. Prior work has studied imitation learning (IL) for autonomous driving with a number of limitations. Examples include only performing lane-following rather than following a user-defined route, only using a single camera view or heavily cropped frames lacking state observability, only lateral (steering) control, but not longitudinal (speed) control and a lack of interaction with traffic. Importantly, the majority of such systems have been primarily evaluated in simulation - a simple domain, which lacks real-world complexities. Motivated by these challenges, we focus on learning representations of semantics, geometry and motion with computer vision for IL from human driving demonstrations. As our main contribution, we present an end-to-end conditional imitation learning approach, combining both lateral and longitudinal control on a real vehicle for following urban routes with simple traffic. We address inherent dataset bias by data balancing, training our final policy on approximately 30 hours of demonstrations gathered over six months. We evaluate our method on an autonomous vehicle by driving 35km of novel routes in European urban streets.