 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransitGPT: A Generative AI-based framework for interacting with GTFS data using Large Language Models
Dec 07, 2024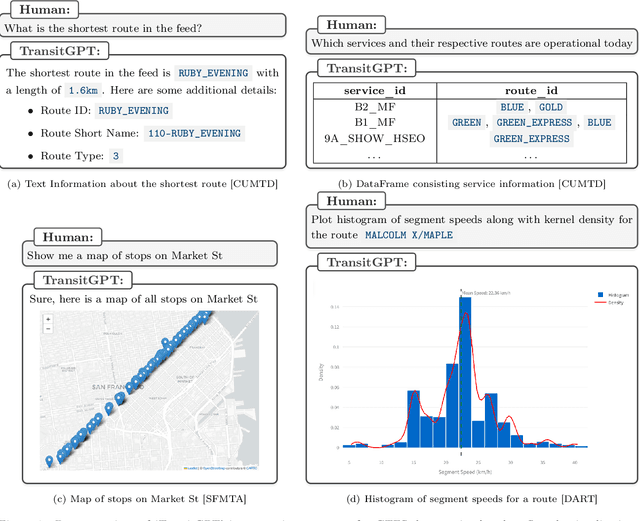
This paper introduces a framework that leverages Large Language Models (LLMs) to answer natural language queries about General Transit Feed Specification (GTFS) data. The framework is implemented in a chatbot called TransitGPT with open-source code. TransitGPT works by guiding LLMs to generate Python code that extracts and manipulates GTFS data relevant to a query, which is then executed on a server where the GTFS feed is stored. It can accomplish a wide range of tasks, including data retrieval, calculations, and interactive visualizations, without requiring users to have extensive knowledge of GTFS or programming. The LLMs that produce the code are guided entirely by prompts, without fine-tuning or access to the actual GTFS feeds. We evaluate TransitGPT using GPT-4o and Claude-3.5-Sonnet LLMs on a benchmark dataset of 100 tasks, to demonstrate its effectiveness and versatility. The results show that TransitGPT can significantly enhance the accessibility and usability of transit data.
ChatGPT for GTFS: From Words to Information
Aug 04, 2023
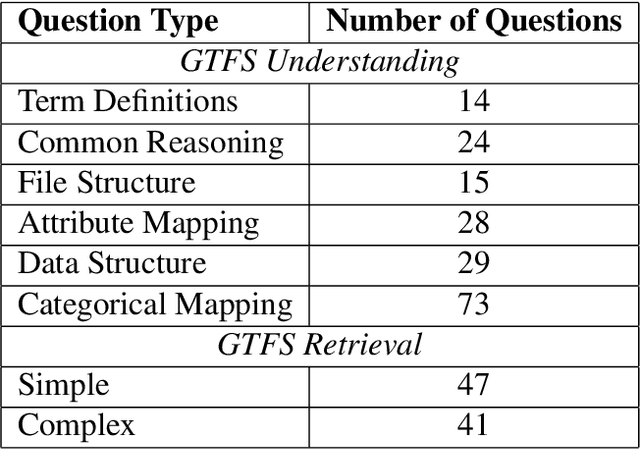


The General Transit Feed Specification (GTFS) standard for publishing transit data is ubiquitous. GTFS being tabular data, with information spread across different files, necessitates specialized tools or packages to retrieve information. Concurrently, the use of Large Language Models for text and information retrieval is growing. The idea of this research is to see if the current widely adopted LLMs (ChatGPT) are able to retrieve information from GTFS using natural language instructions. We first test whether ChatGPT (GPT-3.5) understands the GTFS specification. GPT-3.5 answers 77% of our multiple-choice questions (MCQ) correctly. Next, we task the LLM with information extractions from a filtered GTFS feed with 4 routes. For information retrieval, we compare zero-shot and program synthesis. Program synthesis works better, achieving ~90% accuracy on simple questions and ~40% accuracy on complex questions.
CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022
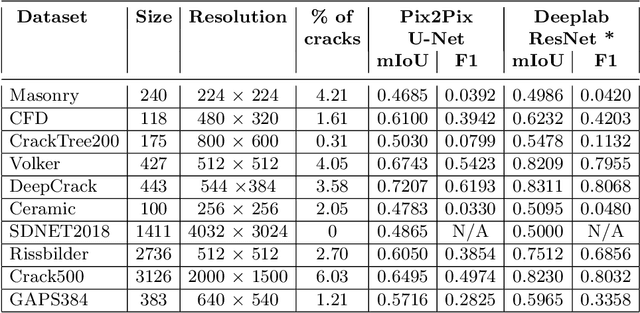

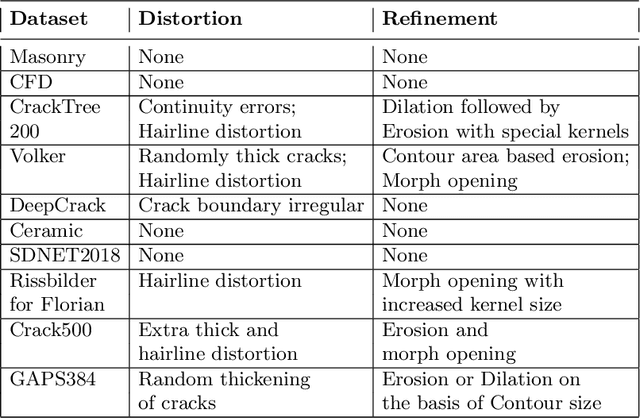
The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.