 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRISHUL: Towards Region Identification and Screen Hierarchy Understanding for Large VLM based GUI Agents
Feb 12, 2025Recent advancements in Large Vision Language Models (LVLMs) have enabled the development of LVLM-based Graphical User Interface (GUI) agents under various paradigms. Training-based approaches, such as CogAgent and SeeClick, struggle with cross-dataset and cross-platform generalization due to their reliance on dataset-specific training. Generalist LVLMs, such as GPT-4V, employ Set-of-Marks (SoM) for action grounding, but obtaining SoM labels requires metadata like HTML source, which is not consistently available across platforms. Moreover, existing methods often specialize in singular GUI tasks rather than achieving comprehensive GUI understanding. To address these limitations, we introduce TRISHUL, a novel, training-free agentic framework that enhances generalist LVLMs for holistic GUI comprehension. Unlike prior works that focus on either action grounding (mapping instructions to GUI elements) or GUI referring (describing GUI elements given a location), TRISHUL seamlessly integrates both. At its core, TRISHUL employs Hierarchical Screen Parsing (HSP) and the Spatially Enhanced Element Description (SEED) module, which work synergistically to provide multi-granular, spatially, and semantically enriched representations of GUI elements. Our results demonstrate TRISHUL's superior performance in action grounding across the ScreenSpot, VisualWebBench, AITW, and Mind2Web datasets. Additionally, for GUI referring, TRISHUL surpasses the ToL agent on the ScreenPR benchmark, setting a new standard for robust and adaptable GUI comprehension.
SEE-DPO: Self Entropy Enhanced Direct Preference Optimization
Nov 06, 2024


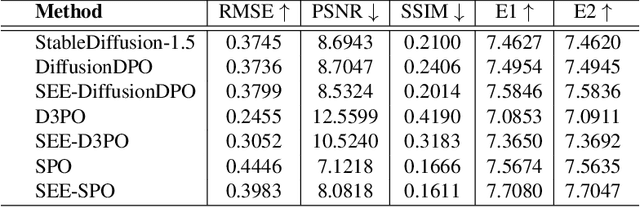
Direct Preference Optimization (DPO) has been successfully used to align large language models (LLMs) according to human preferences, and more recently it has also been applied to improving the quality of text-to-image diffusion models. However, DPO-based methods such as SPO, Diffusion-DPO, and D3PO are highly susceptible to overfitting and reward hacking, especially when the generative model is optimized to fit out-of-distribution during prolonged training. To overcome these challenges and stabilize the training of diffusion models, we introduce a self-entropy regularization mechanism in reinforcement learning from human feedback. This enhancement improves DPO training by encouraging broader exploration and greater robustness. Our regularization technique effectively mitigates reward hacking, leading to improved stability and enhanced image quality across the latent space. Extensive experiments demonstrate that integrating human feedback with self-entropy regularization can significantly boost image diversity and specificity, achieving state-of-the-art results on key image generation metrics.
HDRSplat: Gaussian Splatting for High Dynamic Range 3D Scene Reconstruction from Raw Images
Jul 23, 2024The recent advent of 3D Gaussian Splatting (3DGS) has revolutionized the 3D scene reconstruction space enabling high-fidelity novel view synthesis in real-time. However, with the exception of RawNeRF, all prior 3DGS and NeRF-based methods rely on 8-bit tone-mapped Low Dynamic Range (LDR) images for scene reconstruction. Such methods struggle to achieve accurate reconstructions in scenes that require a higher dynamic range. Examples include scenes captured in nighttime or poorly lit indoor spaces having a low signal-to-noise ratio, as well as daylight scenes with shadow regions exhibiting extreme contrast. Our proposed method HDRSplat tailors 3DGS to train directly on 14-bit linear raw images in near darkness which preserves the scenes' full dynamic range and content. Our key contributions are two-fold: Firstly, we propose a linear HDR space-suited loss that effectively extracts scene information from noisy dark regions and nearly saturated bright regions simultaneously, while also handling view-dependent colors without increasing the degree of spherical harmonics. Secondly, through careful rasterization tuning, we implicitly overcome the heavy reliance and sensitivity of 3DGS on point cloud initialization. This is critical for accurate reconstruction in regions of low texture, high depth of field, and low illumination. HDRSplat is the fastest method to date that does 14-bit (HDR) 3D scene reconstruction in $\le$15 minutes/scene ($\sim$30x faster than prior state-of-the-art RawNeRF). It also boasts the fastest inference speed at $\ge$120fps. We further demonstrate the applicability of our HDR scene reconstruction by showcasing various applications like synthetic defocus, dense depth map extraction, and post-capture control of exposure, tone-mapping and view-point.
Passive Snapshot Coded Aperture Dual-Pixel RGB-D Imaging
Feb 28, 2024



Passive, compact, single-shot 3D sensing is useful in many application areas such as microscopy, medical imaging, surgical navigation, and autonomous driving where form factor, time, and power constraints can exist. Obtaining RGB-D scene information over a short imaging distance, in an ultra-compact form factor, and in a passive, snapshot manner is challenging. Dual-pixel (DP) sensors are a potential solution to achieve the same. DP sensors collect light rays from two different halves of the lens in two interleaved pixel arrays, thus capturing two slightly different views of the scene, like a stereo camera system. However, imaging with a DP sensor implies that the defocus blur size is directly proportional to the disparity seen between the views. This creates a trade-off between disparity estimation vs. deblurring accuracy. To improve this trade-off effect, we propose CADS (Coded Aperture Dual-Pixel Sensing), in which we use a coded aperture in the imaging lens along with a DP sensor. In our approach, we jointly learn an optimal coded pattern and the reconstruction algorithm in an end-to-end optimization setting. Our resulting CADS imaging system demonstrates improvement of $>$1.5dB PSNR in all-in-focus (AIF) estimates and 5-6% in depth estimation quality over naive DP sensing for a wide range of aperture settings. Furthermore, we build the proposed CADS prototypes for DSLR photography settings and in an endoscope and a dermoscope form factor. Our novel coded dual-pixel sensing approach demonstrates accurate RGB-D reconstruction results in simulations and real-world experiments in a passive, snapshot, and compact manner.
CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022
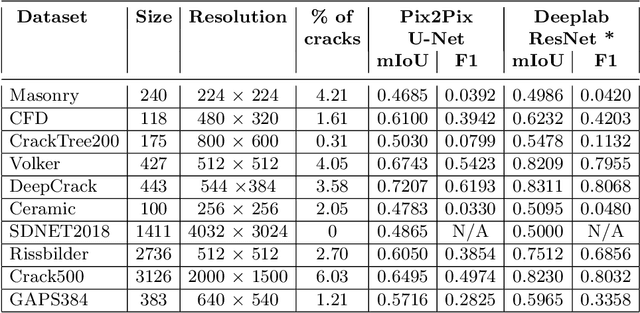

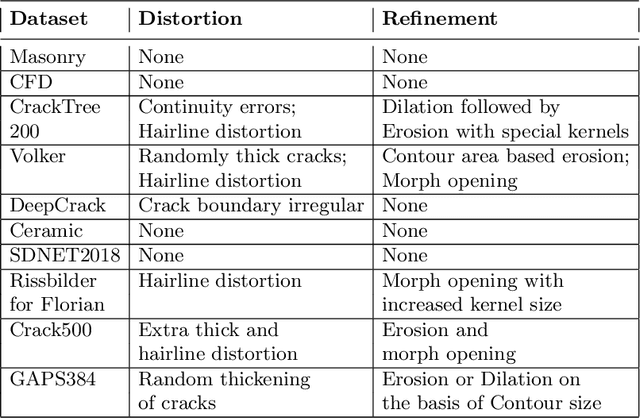
The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.