 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-1 by Josh Talks: A Full-Duplex Conversational Modeling Framework in Hindi using Real-World Conversations
Apr 25, 2026Full-duplex spoken dialogue systems can model natural conversational behaviours such as interruptions, overlaps, and backchannels, yet such systems remain largely unexplored for Indian languages. We present the first open, reproducible full-duplex spoken dialogue system for Hindi by adapting Moshi, a state-of-the-art duplex speech architecture, using a custom Hindi tokeniser and training on 26,000 hours of real spontaneous conversations collected from 14,695 speakers with separate speaker channels, enabling direct learning of turn-taking and overlap patterns from natural interactions. To support Hindi text generation, we replace the original English tokeniser and reinitialise text-vocabulary-dependent parameters while retaining the pre-trained audio components. We propose a two-stage training recipe -- large-scale pre-training followed by fine-tuning on 1,000 hours of conversational data. Evaluation through the prompted dialogue continuation paradigm with both automatic metrics and human judgments demonstrates that the resulting model generates natural and meaningful full-duplex conversational behaviour in Hindi. This work serves as a first step toward real-time duplex spoken dialogue systems for Hindi and other Indian languages.
Passive Snapshot Coded Aperture Dual-Pixel RGB-D Imaging
Feb 28, 2024



Passive, compact, single-shot 3D sensing is useful in many application areas such as microscopy, medical imaging, surgical navigation, and autonomous driving where form factor, time, and power constraints can exist. Obtaining RGB-D scene information over a short imaging distance, in an ultra-compact form factor, and in a passive, snapshot manner is challenging. Dual-pixel (DP) sensors are a potential solution to achieve the same. DP sensors collect light rays from two different halves of the lens in two interleaved pixel arrays, thus capturing two slightly different views of the scene, like a stereo camera system. However, imaging with a DP sensor implies that the defocus blur size is directly proportional to the disparity seen between the views. This creates a trade-off between disparity estimation vs. deblurring accuracy. To improve this trade-off effect, we propose CADS (Coded Aperture Dual-Pixel Sensing), in which we use a coded aperture in the imaging lens along with a DP sensor. In our approach, we jointly learn an optimal coded pattern and the reconstruction algorithm in an end-to-end optimization setting. Our resulting CADS imaging system demonstrates improvement of $>$1.5dB PSNR in all-in-focus (AIF) estimates and 5-6% in depth estimation quality over naive DP sensing for a wide range of aperture settings. Furthermore, we build the proposed CADS prototypes for DSLR photography settings and in an endoscope and a dermoscope form factor. Our novel coded dual-pixel sensing approach demonstrates accurate RGB-D reconstruction results in simulations and real-world experiments in a passive, snapshot, and compact manner.
Achieving RGB-D level Segmentation Performance from a Single ToF Camera
Jun 30, 2023
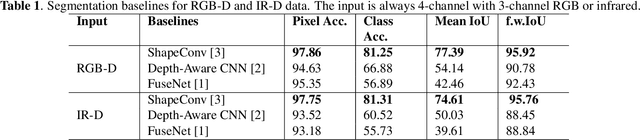
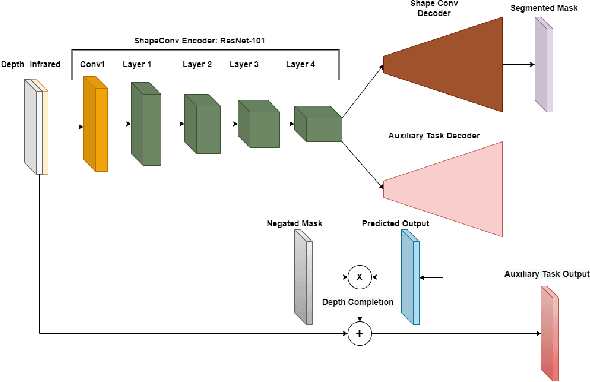
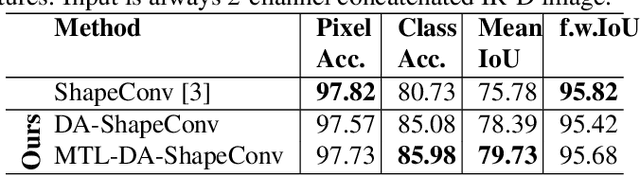
Depth is a very important modality in computer vision, typically used as complementary information to RGB, provided by RGB-D cameras. In this work, we show that it is possible to obtain the same level of accuracy as RGB-D cameras on a semantic segmentation task using infrared (IR) and depth images from a single Time-of-Flight (ToF) camera. In order to fuse the IR and depth modalities of the ToF camera, we introduce a method utilizing depth-specific convolutions in a multi-task learning framework. In our evaluation on an in-car segmentation dataset, we demonstrate the competitiveness of our method against the more costly RGB-D approaches.
Pro-KD: Progressive Distillation by Following the Footsteps of the Teacher
Oct 16, 2021


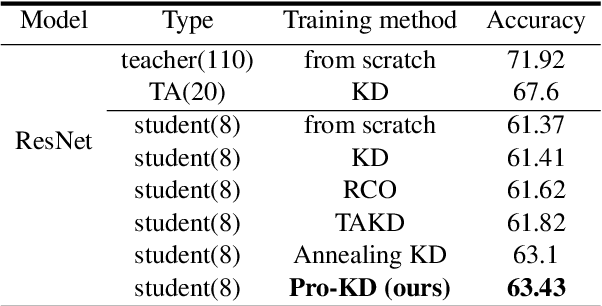
With ever growing scale of neural models, knowledge distillation (KD) attracts more attention as a prominent tool for neural model compression. However, there are counter intuitive observations in the literature showing some challenging limitations of KD. A case in point is that the best performing checkpoint of the teacher might not necessarily be the best teacher for training the student in KD. Therefore, one important question would be how to find the best checkpoint of the teacher for distillation? Searching through the checkpoints of the teacher would be a very tedious and computationally expensive process, which we refer to as the \textit{checkpoint-search problem}. Moreover, another observation is that larger teachers might not necessarily be better teachers in KD which is referred to as the \textit{capacity-gap} problem. To address these challenging problems, in this work, we introduce our progressive knowledge distillation (Pro-KD) technique which defines a smoother training path for the student by following the training footprints of the teacher instead of solely relying on distilling from a single mature fully-trained teacher. We demonstrate that our technique is quite effective in mitigating the capacity-gap problem and the checkpoint search problem. We evaluate our technique using a comprehensive set of experiments on different tasks such as image classification (CIFAR-10 and CIFAR-100), natural language understanding tasks of the GLUE benchmark, and question answering (SQuAD 1.1 and 2.0) using BERT-based models and consistently got superior results over state-of-the-art techniques.
How to Select One Among All? An Extensive Empirical Study Towards the Robustness of Knowledge Distillation in Natural Language Understanding
Sep 20, 2021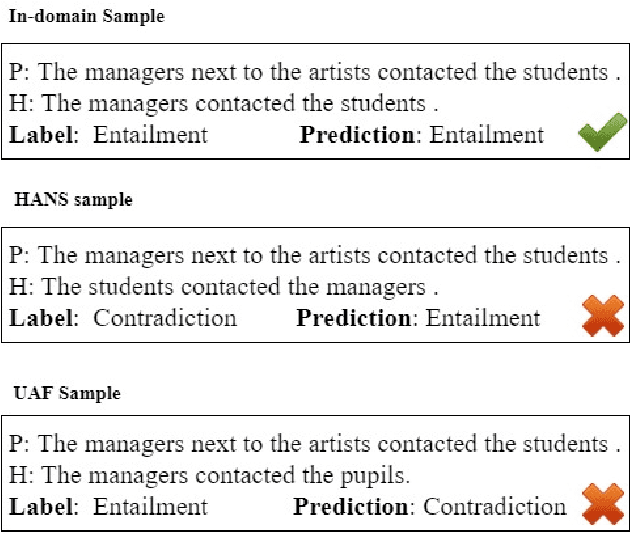
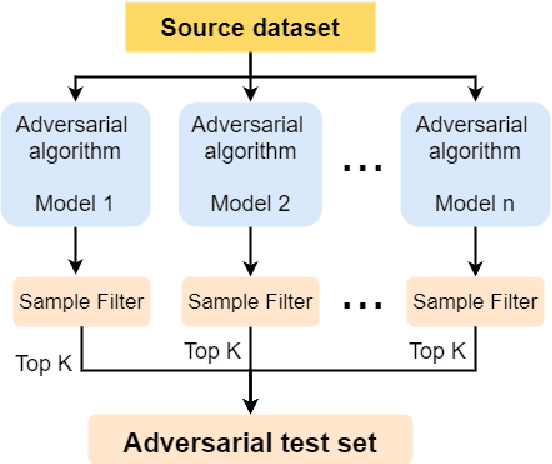
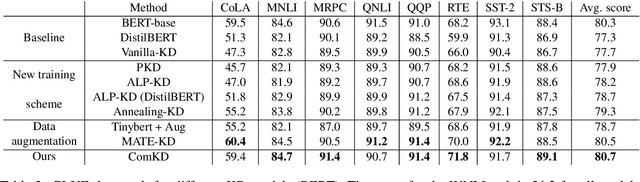
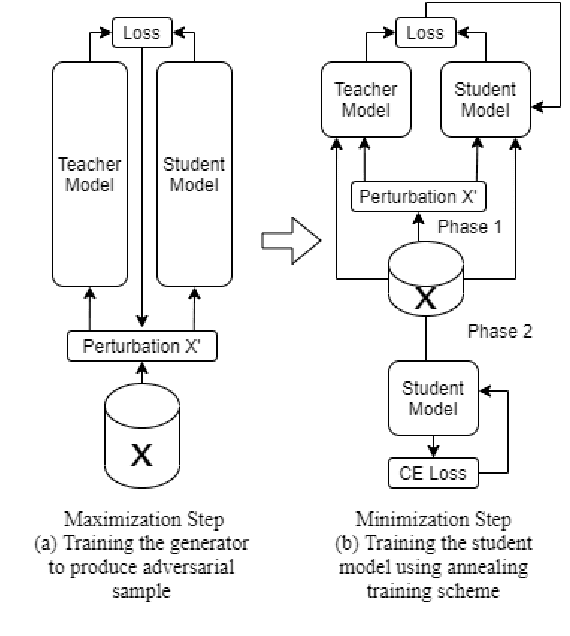
Knowledge Distillation (KD) is a model compression algorithm that helps transfer the knowledge of a large neural network into a smaller one. Even though KD has shown promise on a wide range of Natural Language Processing (NLP) applications, little is understood about how one KD algorithm compares to another and whether these approaches can be complimentary to each other. In this work, we evaluate various KD algorithms on in-domain, out-of-domain and adversarial testing. We propose a framework to assess the adversarial robustness of multiple KD algorithms. Moreover, we introduce a new KD algorithm, Combined-KD, which takes advantage of two promising approaches (better training scheme and more efficient data augmentation). Our extensive experimental results show that Combined-KD achieves state-of-the-art results on the GLUE benchmark, out-of-domain generalization, and adversarial robustness compared to competitive methods.
Annealing Knowledge Distillation
Apr 14, 2021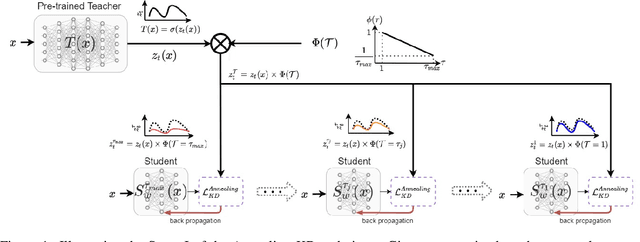

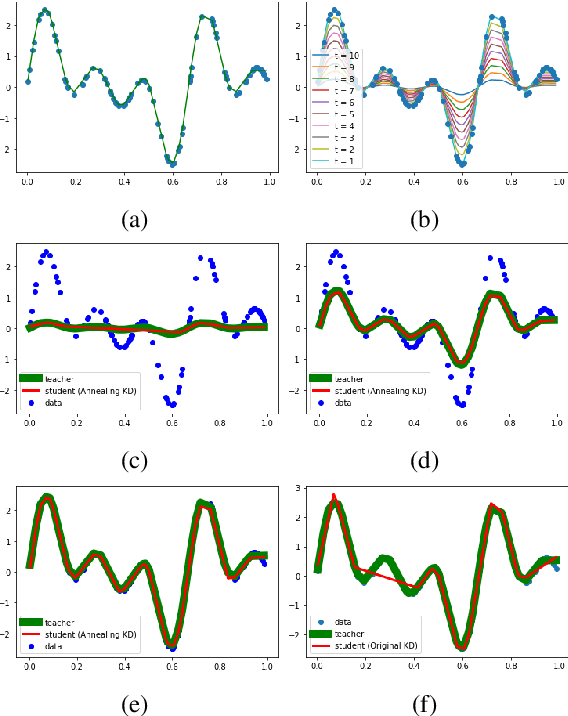
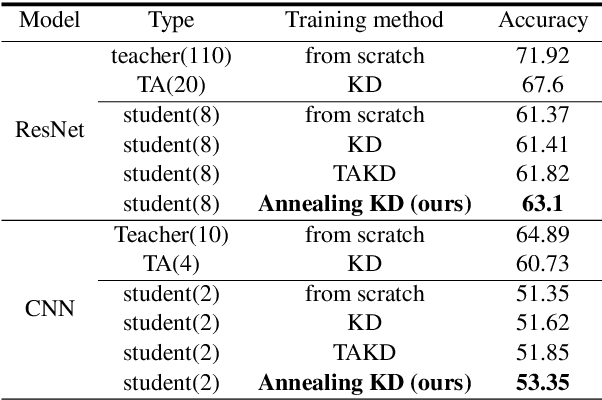
Significant memory and computational requirements of large deep neural networks restrict their application on edge devices. Knowledge distillation (KD) is a prominent model compression technique for deep neural networks in which the knowledge of a trained large teacher model is transferred to a smaller student model. The success of knowledge distillation is mainly attributed to its training objective function, which exploits the soft-target information (also known as "dark knowledge") besides the given regular hard labels in a training set. However, it is shown in the literature that the larger the gap between the teacher and the student networks, the more difficult is their training using knowledge distillation. To address this shortcoming, we propose an improved knowledge distillation method (called Annealing-KD) by feeding the rich information provided by the teacher's soft-targets incrementally and more efficiently. Our Annealing-KD technique is based on a gradual transition over annealed soft-targets generated by the teacher at different temperatures in an iterative process, and therefore, the student is trained to follow the annealed teacher output in a step-by-step manner. This paper includes theoretical and empirical evidence as well as practical experiments to support the effectiveness of our Annealing-KD method. We did a comprehensive set of experiments on different tasks such as image classification (CIFAR-10 and 100) and NLP language inference with BERT-based models on the GLUE benchmark and consistently got superior results.
LPar -- A Distributed Multi Agent platform for building Polyglot, Omni Channel and Industrial grade Natural Language Interfaces
Jun 25, 2020The goal of serving and delighting customers in a personal and near human like manner is very high on automation agendas of most Enterprises. Last few years, have seen huge progress in Natural Language Processing domain which has led to deployments of conversational agents in many enterprises. Most of the current industrial deployments tend to use Monolithic Single Agent designs that model the entire knowledge and skill of the Domain. While this approach is one of the fastest to market, the monolithic design makes it very hard to scale beyond a point. There are also challenges in seamlessly leveraging many tools offered by sub fields of Natural Language Processing and Information Retrieval in a single solution. The sub fields that can be leveraged to provide relevant information are, Question and Answer system, Abstractive Summarization, Semantic Search, Knowledge Graph etc. Current deployments also tend to be very dependent on the underlying Conversational AI platform (open source or commercial) , which is a challenge as this is a fast evolving space and no one platform can be considered future proof even in medium term of 3-4 years. Lately,there is also work done to build multi agent solutions that tend to leverage a concept of master agent. While this has shown promise, this approach still makes the master agent in itself difficult to scale. To address these challenges, we introduce LPar, a distributed multi agent platform for large scale industrial deployment of polyglot, diverse and inter-operable agents. The asynchronous design of LPar supports dynamically expandable domain. We also introduce multiple strategies available in the LPar system to elect the most suitable agent to service a customer query.