 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Select One Among All? An Extensive Empirical Study Towards the Robustness of Knowledge Distillation in Natural Language Understanding
Paper and Code
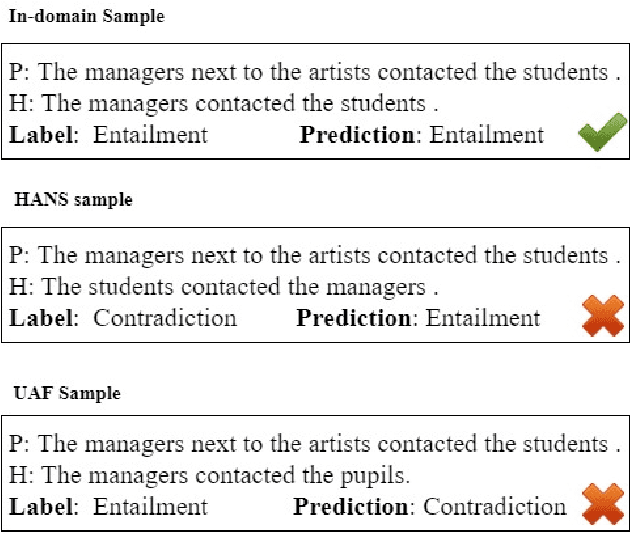
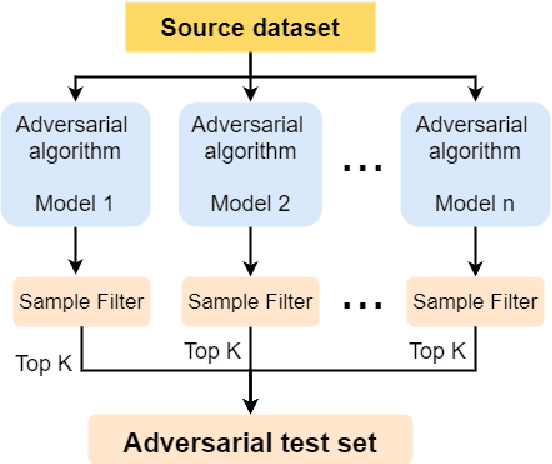
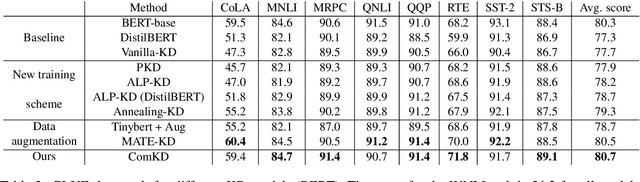
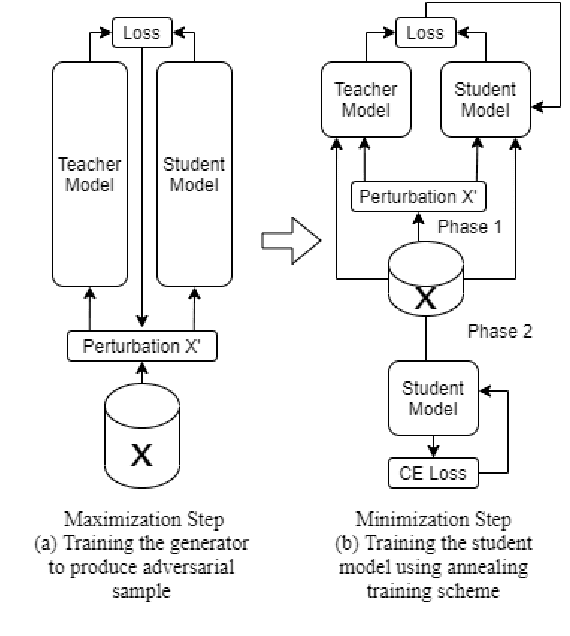
Knowledge Distillation (KD) is a model compression algorithm that helps transfer the knowledge of a large neural network into a smaller one. Even though KD has shown promise on a wide range of Natural Language Processing (NLP) applications, little is understood about how one KD algorithm compares to another and whether these approaches can be complimentary to each other. In this work, we evaluate various KD algorithms on in-domain, out-of-domain and adversarial testing. We propose a framework to assess the adversarial robustness of multiple KD algorithms. Moreover, we introduce a new KD algorithm, Combined-KD, which takes advantage of two promising approaches (better training scheme and more efficient data augmentation). Our extensive experimental results show that Combined-KD achieves state-of-the-art results on the GLUE benchmark, out-of-domain generalization, and adversarial robustness compared to competitive methods.