 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Sep 22, 2024



Large Language Models (LLMs), with their increasing depth and number of parameters, have demonstrated outstanding performance across a variety of natural language processing tasks. However, this growth in scale leads to increased computational demands, particularly during inference and fine-tuning. To address these challenges, we introduce EchoAtt, a novel framework aimed at optimizing transformer-based models by analyzing and leveraging the similarity of attention patterns across layers. Our analysis reveals that many inner layers in LLMs, especially larger ones, exhibit highly similar attention matrices. By exploiting this similarity, EchoAtt enables the sharing of attention matrices in less critical layers, significantly reducing computational requirements without compromising performance. We incorporate this approach within a knowledge distillation setup, where a pre-trained teacher model guides the training of a smaller student model. The student model selectively shares attention matrices in layers with high similarity while inheriting key parameters from the teacher. Our best results with TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15\%, training speed by 25\%, and reduces the number of parameters by approximately 4\%, all while improving zero-shot performance. These findings highlight the potential of attention matrix sharing to enhance the efficiency of LLMs, making them more practical for real-time and resource-limited applications.
HAGRID: A Human-LLM Collaborative Dataset for Generative Information-Seeking with Attribution
Jul 31, 2023



The rise of large language models (LLMs) had a transformative impact on search, ushering in a new era of search engines that are capable of generating search results in natural language text, imbued with citations for supporting sources. Building generative information-seeking models demands openly accessible datasets, which currently remain lacking. In this paper, we introduce a new dataset, HAGRID (Human-in-the-loop Attributable Generative Retrieval for Information-seeking Dataset) for building end-to-end generative information-seeking models that are capable of retrieving candidate quotes and generating attributed explanations. Unlike recent efforts that focus on human evaluation of black-box proprietary search engines, we built our dataset atop the English subset of MIRACL, a publicly available information retrieval dataset. HAGRID is constructed based on human and LLM collaboration. We first automatically collect attributed explanations that follow an in-context citation style using an LLM, i.e. GPT-3.5. Next, we ask human annotators to evaluate the LLM explanations based on two criteria: informativeness and attributability. HAGRID serves as a catalyst for the development of information-seeking models with better attribution capabilities.
Improved knowledge distillation by utilizing backward pass knowledge in neural networks
Jan 27, 2023Knowledge distillation (KD) is one of the prominent techniques for model compression. In this method, the knowledge of a large network (teacher) is distilled into a model (student) with usually significantly fewer parameters. KD tries to better-match the output of the student model to that of the teacher model based on the knowledge extracts from the forward pass of the teacher network. Although conventional KD is effective for matching the two networks over the given data points, there is no guarantee that these models would match in other areas for which we do not have enough training samples. In this work, we address that problem by generating new auxiliary training samples based on extracting knowledge from the backward pass of the teacher in the areas where the student diverges greatly from the teacher. We compute the difference between the teacher and the student and generate new data samples that maximize the divergence. This is done by perturbing data samples in the direction of the gradient of the difference between the student and the teacher. Augmenting the training set by adding this auxiliary improves the performance of KD significantly and leads to a closer match between the student and the teacher. Using this approach, when data samples come from a discrete domain, such as applications of natural language processing (NLP) and language understanding, is not trivial. However, we show how this technique can be used successfully in such applications. We evaluated the performance of our method on various tasks in computer vision and NLP domains and got promising results.
Continuation KD: Improved Knowledge Distillation through the Lens of Continuation Optimization
Dec 12, 2022Knowledge Distillation (KD) has been extensively used for natural language understanding (NLU) tasks to improve a small model's (a student) generalization by transferring the knowledge from a larger model (a teacher). Although KD methods achieve state-of-the-art performance in numerous settings, they suffer from several problems limiting their performance. It is shown in the literature that the capacity gap between the teacher and the student networks can make KD ineffective. Additionally, existing KD techniques do not mitigate the noise in the teacher's output: modeling the noisy behaviour of the teacher can distract the student from learning more useful features. We propose a new KD method that addresses these problems and facilitates the training compared to previous techniques. Inspired by continuation optimization, we design a training procedure that optimizes the highly non-convex KD objective by starting with the smoothed version of this objective and making it more complex as the training proceeds. Our method (Continuation-KD) achieves state-of-the-art performance across various compact architectures on NLU (GLUE benchmark) and computer vision tasks (CIFAR-10 and CIFAR-100).
Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
May 25, 2022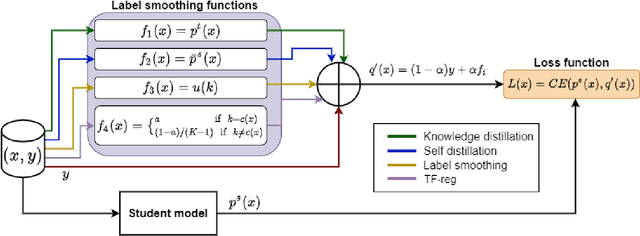
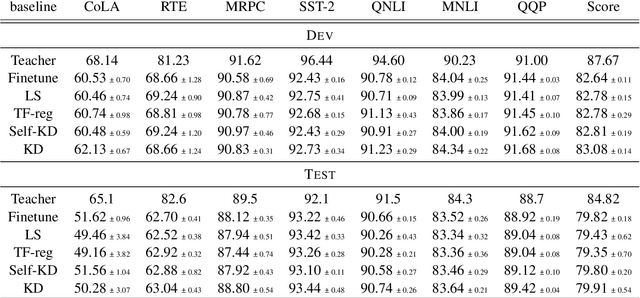
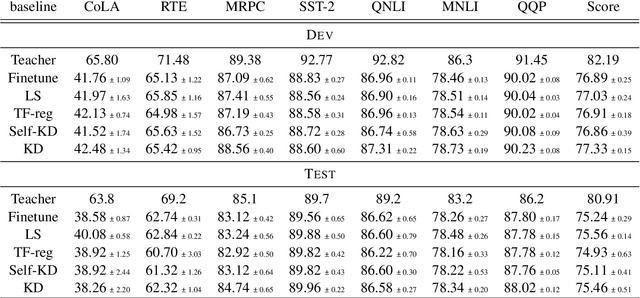
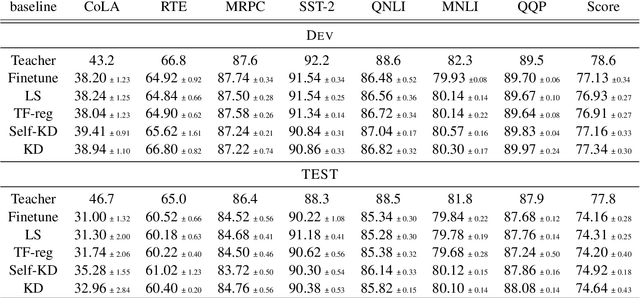
Knowledge Distillation (KD) is a prominent neural model compression technique which heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need the teacher labels to fine-tune smaller PLM student networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
Pro-KD: Progressive Distillation by Following the Footsteps of the Teacher
Oct 16, 2021


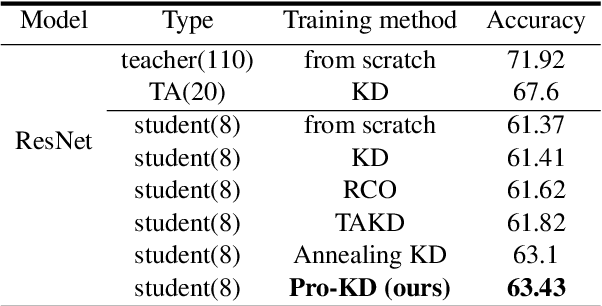
With ever growing scale of neural models, knowledge distillation (KD) attracts more attention as a prominent tool for neural model compression. However, there are counter intuitive observations in the literature showing some challenging limitations of KD. A case in point is that the best performing checkpoint of the teacher might not necessarily be the best teacher for training the student in KD. Therefore, one important question would be how to find the best checkpoint of the teacher for distillation? Searching through the checkpoints of the teacher would be a very tedious and computationally expensive process, which we refer to as the \textit{checkpoint-search problem}. Moreover, another observation is that larger teachers might not necessarily be better teachers in KD which is referred to as the \textit{capacity-gap} problem. To address these challenging problems, in this work, we introduce our progressive knowledge distillation (Pro-KD) technique which defines a smoother training path for the student by following the training footprints of the teacher instead of solely relying on distilling from a single mature fully-trained teacher. We demonstrate that our technique is quite effective in mitigating the capacity-gap problem and the checkpoint search problem. We evaluate our technique using a comprehensive set of experiments on different tasks such as image classification (CIFAR-10 and CIFAR-100), natural language understanding tasks of the GLUE benchmark, and question answering (SQuAD 1.1 and 2.0) using BERT-based models and consistently got superior results over state-of-the-art techniques.
How to Select One Among All? An Extensive Empirical Study Towards the Robustness of Knowledge Distillation in Natural Language Understanding
Sep 20, 2021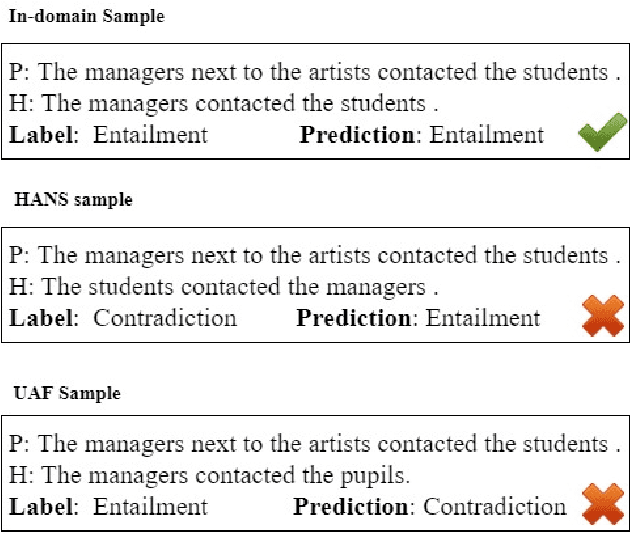
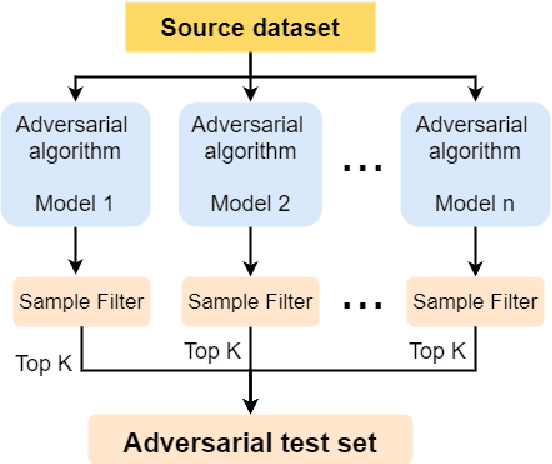
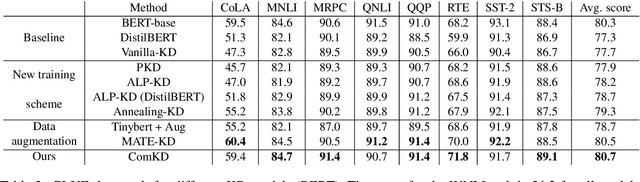
Knowledge Distillation (KD) is a model compression algorithm that helps transfer the knowledge of a large neural network into a smaller one. Even though KD has shown promise on a wide range of Natural Language Processing (NLP) applications, little is understood about how one KD algorithm compares to another and whether these approaches can be complimentary to each other. In this work, we evaluate various KD algorithms on in-domain, out-of-domain and adversarial testing. We propose a framework to assess the adversarial robustness of multiple KD algorithms. Moreover, we introduce a new KD algorithm, Combined-KD, which takes advantage of two promising approaches (better training scheme and more efficient data augmentation). Our extensive experimental results show that Combined-KD achieves state-of-the-art results on the GLUE benchmark, out-of-domain generalization, and adversarial robustness compared to competitive methods.
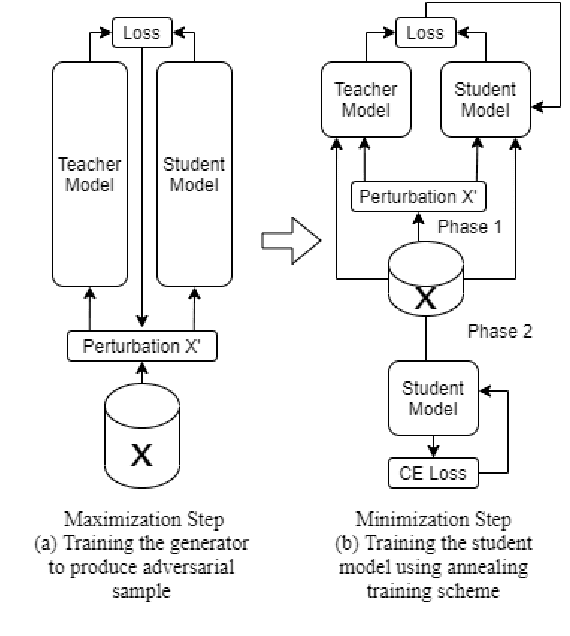
Annealing Knowledge Distillation
Apr 14, 2021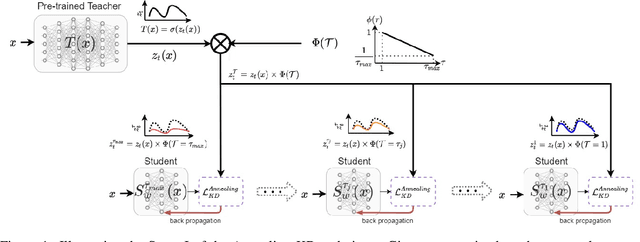

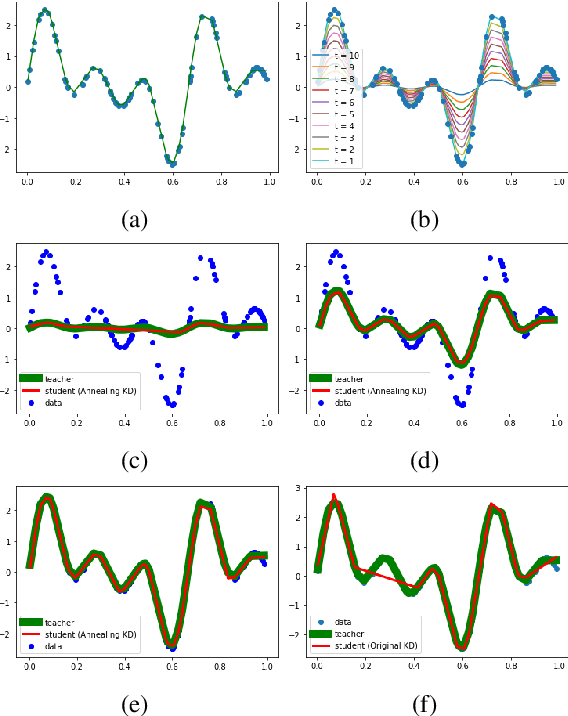
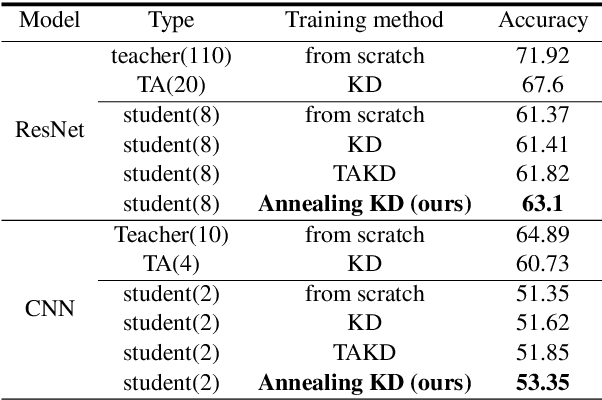
Significant memory and computational requirements of large deep neural networks restrict their application on edge devices. Knowledge distillation (KD) is a prominent model compression technique for deep neural networks in which the knowledge of a trained large teacher model is transferred to a smaller student model. The success of knowledge distillation is mainly attributed to its training objective function, which exploits the soft-target information (also known as "dark knowledge") besides the given regular hard labels in a training set. However, it is shown in the literature that the larger the gap between the teacher and the student networks, the more difficult is their training using knowledge distillation. To address this shortcoming, we propose an improved knowledge distillation method (called Annealing-KD) by feeding the rich information provided by the teacher's soft-targets incrementally and more efficiently. Our Annealing-KD technique is based on a gradual transition over annealed soft-targets generated by the teacher at different temperatures in an iterative process, and therefore, the student is trained to follow the annealed teacher output in a step-by-step manner. This paper includes theoretical and empirical evidence as well as practical experiments to support the effectiveness of our Annealing-KD method. We did a comprehensive set of experiments on different tasks such as image classification (CIFAR-10 and 100) and NLP language inference with BERT-based models on the GLUE benchmark and consistently got superior results.
Segmentation Approach for Coreference Resolution Task
Jun 30, 2020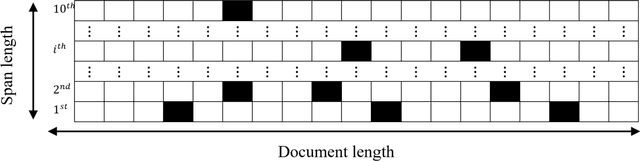

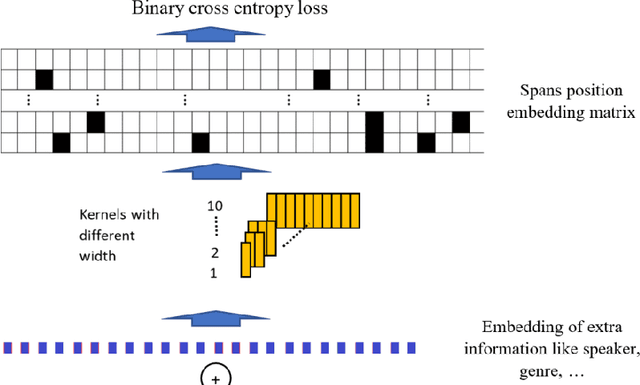
In coreference resolution, it is important to consider all members of a coreference cluster and decide about all of them at once. This technique can help to avoid losing precision and also in finding long-distance relations. The presented paper is a report of an ongoing study on an idea which proposes a new approach for coreference resolution which can resolve all coreference mentions to a given mention in the document in one pass. This has been accomplished by defining an embedding method for the position of all members of a coreference cluster in a document and resolving all of them for a given mention. In the proposed method, the BERT model has been used for encoding the documents and a head network designed to capture the relations between the embedded tokens. These are then converted to the proposed span position embedding matrix which embeds the position of all coreference mentions in the document. We tested this idea on CoNLL 2012 dataset and although the preliminary results from this method do not quite meet the state-of-the-art results, they are promising and they can capture features like long-distance relations better than the other approaches.