 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGLA: Refining Gated Linear Attention
Feb 03, 2025Recent advancements in Large Language Models (LLMs) have set themselves apart with their exceptional performance in complex language modelling tasks. However, these models are also known for their significant computational and storage requirements, primarily due to the quadratic computation complexity of softmax attention. To mitigate this issue, linear attention has been designed to reduce the quadratic space-time complexity that is inherent in standard transformers. In this work, we embarked on a comprehensive exploration of three key components that substantially impact the performance of the Gated Linear Attention module: feature maps, normalization, and the gating mechanism. We developed a feature mapping function to address some crucial issues that previous suggestions overlooked. Then we offered further rationale for the integration of normalization layers to stabilize the training process. Moreover, we explored the saturation phenomenon of the gating mechanism and augmented it with a refining module. We conducted extensive experiments and showed our architecture outperforms previous Gated Linear Attention mechanisms in extensive tasks including training from scratch and post-linearization with continual pre-training.
Draft on the Fly: Adaptive Self-Speculative Decoding using Cosine Similarity
Oct 01, 2024We present a simple on the fly method for faster inference of large language models. Unlike other (self-)speculative decoding techniques, our method does not require fine-tuning or black-box optimization to generate a fixed draft model, relying instead on simple rules to generate varying draft models adapted to the input context. We show empirically that our light-weight algorithm is competitive with the current SOTA for self-speculative decoding, while being a truly plug-and-play method.
OTTAWA: Optimal TransporT Adaptive Word Aligner for Hallucination and Omission Translation Errors Detection
Jun 04, 2024Recently, there has been considerable attention on detecting hallucinations and omissions in Machine Translation (MT) systems. The two dominant approaches to tackle this task involve analyzing the MT system's internal states or relying on the output of external tools, such as sentence similarity or MT quality estimators. In this work, we introduce OTTAWA, a novel Optimal Transport (OT)-based word aligner specifically designed to enhance the detection of hallucinations and omissions in MT systems. Our approach explicitly models the missing alignments by introducing a "null" vector, for which we propose a novel one-side constrained OT setting to allow an adaptive null alignment. Our approach yields competitive results compared to state-of-the-art methods across 18 language pairs on the HalOmi benchmark. In addition, it shows promising features, such as the ability to distinguish between both error types and perform word-level detection without accessing the MT system's internal states.
Resonance RoPE: Improving Context Length Generalization of Large Language Models
Feb 29, 2024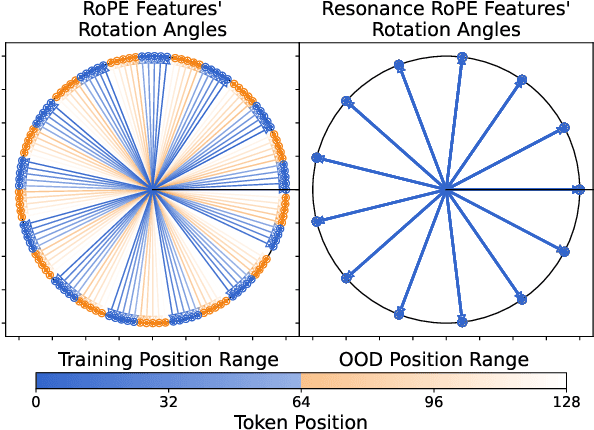

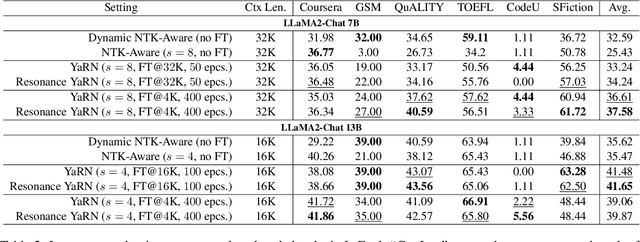
This paper addresses the challenge of train-short-test-long (TSTL) scenarios in Large Language Models (LLMs) equipped with Rotary Position Embedding (RoPE), where models pre-trained on shorter sequences face difficulty with out-of-distribution (OOD) token positions in longer sequences. We introduce Resonance RoPE, a novel approach designed to narrow the generalization gap in TSTL scenarios by refining the interpolation of RoPE features for OOD positions, significantly improving the model performance without additional online computational costs. Furthermore, we present PosGen, a new synthetic benchmark specifically designed for fine-grained behavior analysis in TSTL scenarios, aiming to isolate the constantly increasing difficulty of token generation on long contexts from the challenges of recognizing new token positions. Our experiments on synthetic tasks show that after applying Resonance RoPE, Transformers recognize OOD position better and more robustly. Our extensive LLM experiments also show superior performance after applying Resonance RoPE to the current state-of-the-art RoPE scaling method, YaRN, on both upstream language modeling tasks and a variety of downstream long-text applications.
Hyperparameter Optimization for Large Language Model Instruction-Tuning
Dec 01, 2023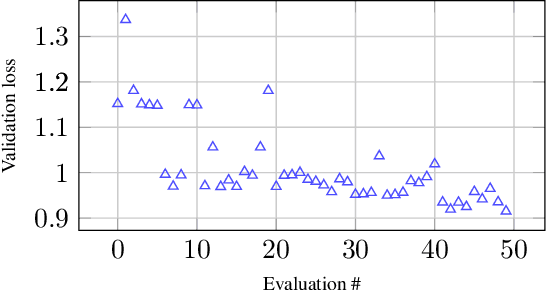
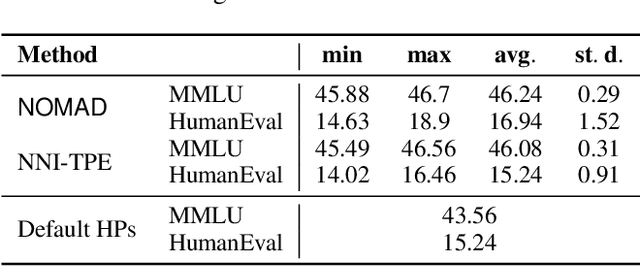
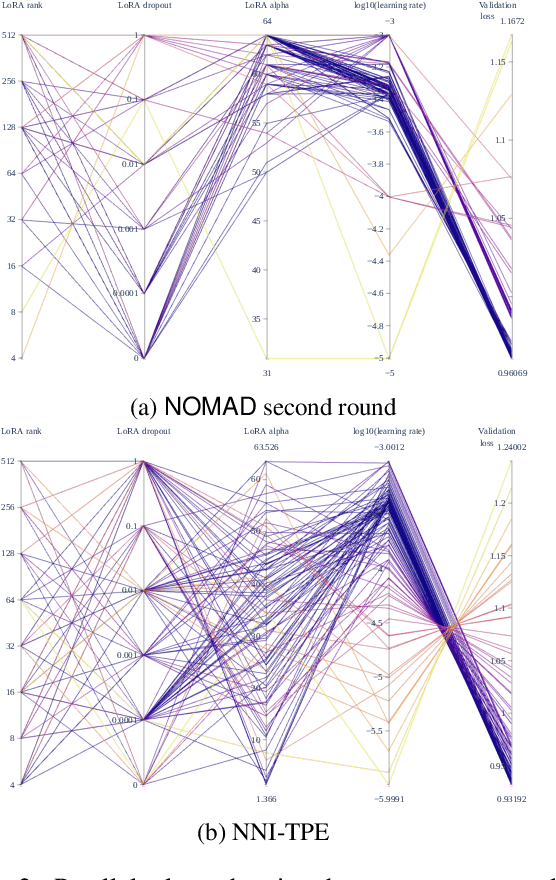

The fine-tuning of Large Language Models (LLMs) has enabled them to recently achieve milestones in natural language processing applications. The emergence of ever larger LLMs has paved the way for more efficient fine-tuning methods. Among these, the Low-Rank Adaptation (LoRA) method keeps most of the weights of the pre-trained LLM frozen while introducing a low-rank decomposition of the weight matrix, enabling the tuning of only a very small proportion of the network. The performance on downstream tasks of models fine-tuned with LoRA heavily relies on a set of hyperparameters including the rank of the decomposition. In this work, we investigate the choice of these hyperparameters through two main blackbox optimization (BBO) techniques. We examine the whole pipeline of performing fine-tuning and validation on a pre-trained LLM as a blackbox and efficiently explore the space of hyperparameters with the \nomad algorithm, achieving a boost in performance and human alignment of the tuned model.
Attribute Controlled Dialogue Prompting
Jul 11, 2023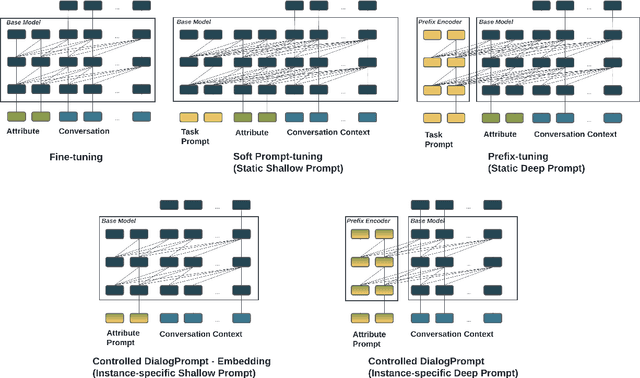


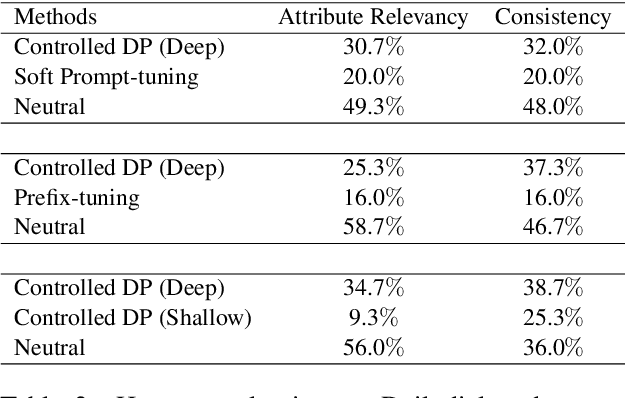
Prompt-tuning has become an increasingly popular parameter-efficient method for adapting large pretrained language models to downstream tasks. However, both discrete prompting and continuous prompting assume fixed prompts for all data samples within a task, neglecting the fact that inputs vary greatly in some tasks such as open-domain dialogue generation. In this paper, we present a novel, instance-specific prompt-tuning algorithm for dialogue generation. Specifically, we generate prompts based on instance-level control code, rather than the conversation history, to explore their impact on controlled dialogue generation. Experiments on popular open-domain dialogue datasets, evaluated on both automated metrics and human evaluation, demonstrate that our method is superior to prompting baselines and comparable to fine-tuning with only 5%-6% of total parameters.
LABO: Towards Learning Optimal Label Regularization via Bi-level Optimization
May 08, 2023



Regularization techniques are crucial to improving the generalization performance and training efficiency of deep neural networks. Many deep learning algorithms rely on weight decay, dropout, batch/layer normalization to converge faster and generalize. Label Smoothing (LS) is another simple, versatile and efficient regularization which can be applied to various supervised classification tasks. Conventional LS, however, regardless of the training instance assumes that each non-target class is equally likely. In this work, we present a general framework for training with label regularization, which includes conventional LS but can also model instance-specific variants. Based on this formulation, we propose an efficient way of learning LAbel regularization by devising a Bi-level Optimization (LABO) problem. We derive a deterministic and interpretable solution of the inner loop as the optimal label smoothing without the need to store the parameters or the output of a trained model. Finally, we conduct extensive experiments and demonstrate our LABO consistently yields improvement over conventional label regularization on various fields, including seven machine translation and three image classification tasks across various
Mathematical Challenges in Deep Learning
Mar 24, 2023



Deep models are dominating the artificial intelligence (AI) industry since the ImageNet challenge in 2012. The size of deep models is increasing ever since, which brings new challenges to this field with applications in cell phones, personal computers, autonomous cars, and wireless base stations. Here we list a set of problems, ranging from training, inference, generalization bound, and optimization with some formalism to communicate these challenges with mathematicians, statisticians, and theoretical computer scientists. This is a subjective view of the research questions in deep learning that benefits the tech industry in long run.
KronA: Parameter Efficient Tuning with Kronecker Adapter
Dec 20, 2022



Fine-tuning a Pre-trained Language Model (PLM) on a specific downstream task has been a well-known paradigm in Natural Language Processing. However, with the ever-growing size of PLMs, training the entire model on several downstream tasks becomes very expensive and resource-hungry. Recently, different Parameter Efficient Tuning (PET) techniques are proposed to improve the efficiency of fine-tuning PLMs. One popular category of PET methods is the low-rank adaptation methods which insert learnable truncated SVD modules into the original model either sequentially or in parallel. However, low-rank decomposition suffers from limited representation power. In this work, we address this problem using the Kronecker product instead of the low-rank representation. We introduce KronA, a Kronecker product-based adapter module for efficient fine-tuning of Transformer-based PLMs. We apply the proposed methods for fine-tuning T5 on the GLUE benchmark to show that incorporating the Kronecker-based modules can outperform state-of-the-art PET methods.
Improving Generalization of Pre-trained Language Models via Stochastic Weight Averaging
Dec 16, 2022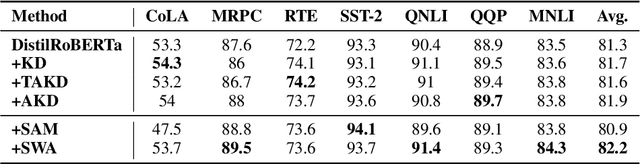
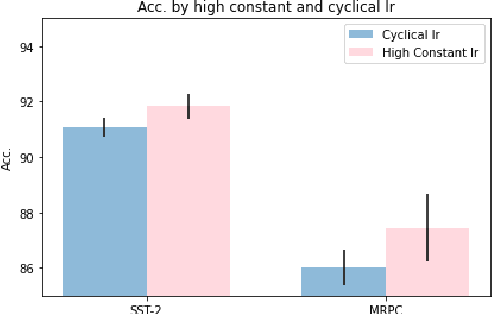
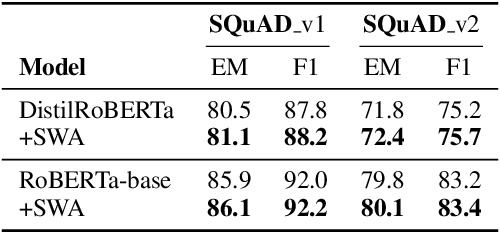
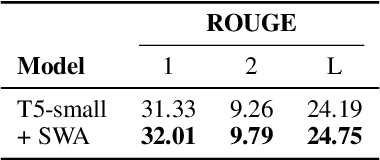
Knowledge Distillation (KD) is a commonly used technique for improving the generalization of compact Pre-trained Language Models (PLMs) on downstream tasks. However, such methods impose the additional burden of training a separate teacher model for every new dataset. Alternatively, one may directly work on the improvement of the optimization procedure of the compact model toward better generalization. Recent works observe that the flatness of the local minimum correlates well with better generalization. In this work, we adapt Stochastic Weight Averaging (SWA), a method encouraging convergence to a flatter minimum, to fine-tuning PLMs. We conduct extensive experiments on various NLP tasks (text classification, question answering, and generation) and different model architectures and demonstrate that our adaptation improves the generalization without extra computation cost. Moreover, we observe that this simple optimization technique is able to outperform the state-of-the-art KD methods for compact models.