 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization of Pre-trained Language Models via Stochastic Weight Averaging
Paper and Code
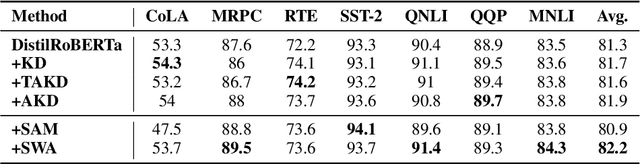
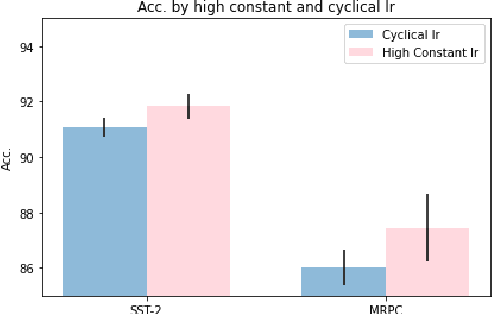
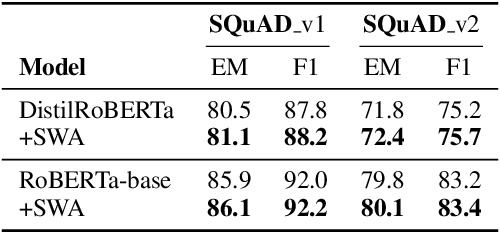
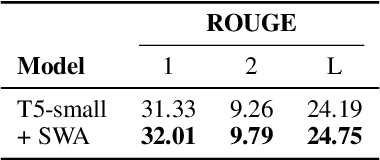
Knowledge Distillation (KD) is a commonly used technique for improving the generalization of compact Pre-trained Language Models (PLMs) on downstream tasks. However, such methods impose the additional burden of training a separate teacher model for every new dataset. Alternatively, one may directly work on the improvement of the optimization procedure of the compact model toward better generalization. Recent works observe that the flatness of the local minimum correlates well with better generalization. In this work, we adapt Stochastic Weight Averaging (SWA), a method encouraging convergence to a flatter minimum, to fine-tuning PLMs. We conduct extensive experiments on various NLP tasks (text classification, question answering, and generation) and different model architectures and demonstrate that our adaptation improves the generalization without extra computation cost. Moreover, we observe that this simple optimization technique is able to outperform the state-of-the-art KD methods for compact models.