 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGLA: Refining Gated Linear Attention
Feb 03, 2025Recent advancements in Large Language Models (LLMs) have set themselves apart with their exceptional performance in complex language modelling tasks. However, these models are also known for their significant computational and storage requirements, primarily due to the quadratic computation complexity of softmax attention. To mitigate this issue, linear attention has been designed to reduce the quadratic space-time complexity that is inherent in standard transformers. In this work, we embarked on a comprehensive exploration of three key components that substantially impact the performance of the Gated Linear Attention module: feature maps, normalization, and the gating mechanism. We developed a feature mapping function to address some crucial issues that previous suggestions overlooked. Then we offered further rationale for the integration of normalization layers to stabilize the training process. Moreover, we explored the saturation phenomenon of the gating mechanism and augmented it with a refining module. We conducted extensive experiments and showed our architecture outperforms previous Gated Linear Attention mechanisms in extensive tasks including training from scratch and post-linearization with continual pre-training.
A linguistically-motivated evaluation methodology for unraveling model's abilities in reading comprehension tasks
Jan 29, 2025We introduce an evaluation methodology for reading comprehension tasks based on the intuition that certain examples, by the virtue of their linguistic complexity, consistently yield lower scores regardless of model size or architecture. We capitalize on semantic frame annotation for characterizing this complexity, and study seven complexity factors that may account for model's difficulty. We first deploy this methodology on a carefully annotated French reading comprehension benchmark showing that two of those complexity factors are indeed good predictors of models' failure, while others are less so. We further deploy our methodology on a well studied English benchmark by using Chat-GPT as a proxy for semantic annotation. Our study reveals that fine-grained linguisticallymotivated automatic evaluation of a reading comprehension task is not only possible, but helps understand models' abilities to handle specific linguistic characteristics of input examples. It also shows that current state-of-the-art models fail with some for those characteristics which suggests that adequately handling them requires more than merely increasing model size.
Part-Of-Speech Sensitivity of Routers in Mixture of Experts Models
Dec 22, 2024This study investigates the behavior of model-integrated routers in Mixture of Experts (MoE) models, focusing on how tokens are routed based on their linguistic features, specifically Part-of-Speech (POS) tags. The goal is to explore across different MoE architectures whether experts specialize in processing tokens with similar linguistic traits. By analyzing token trajectories across experts and layers, we aim to uncover how MoE models handle linguistic information. Findings from six popular MoE models reveal expert specialization for specific POS categories, with routing paths showing high predictive accuracy for POS, highlighting the value of routing paths in characterizing tokens.
$\textit{BenchIE}^{FL}$ : A Manually Re-Annotated Fact-Based Open Information Extraction Benchmark
Jul 23, 2024

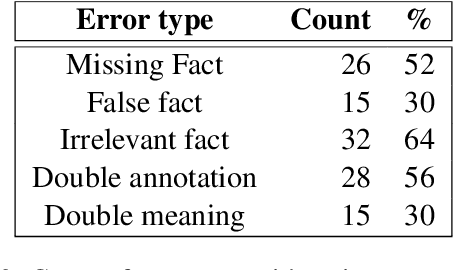
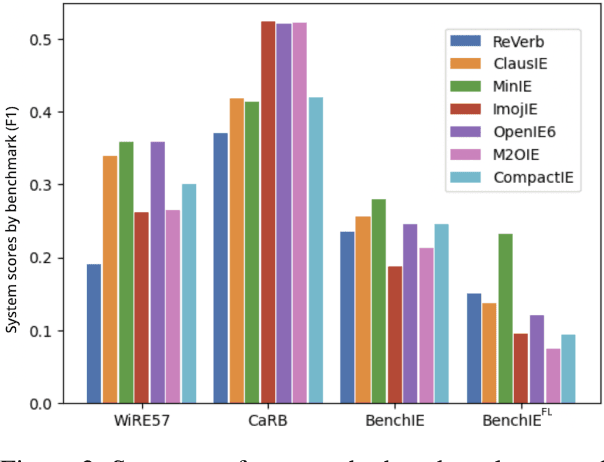
Open Information Extraction (OIE) is a field of natural language processing that aims to present textual information in a format that allows it to be organized, analyzed and reflected upon. Numerous OIE systems are developed, claiming ever-increasing performance, marking the need for objective benchmarks. BenchIE is the latest reference we know of. Despite being very well thought out, we noticed a number of issues we believe are limiting. Therefore, we propose $\textit{BenchIE}^{FL}$, a new OIE benchmark which fully enforces the principles of BenchIE while containing fewer errors, omissions and shortcomings when candidate facts are matched towards reference ones. $\textit{BenchIE}^{FL}$ allows insightful conclusions to be drawn on the actual performance of OIE extractors.
CHARP: Conversation History AwaReness Probing for Knowledge-grounded Dialogue Systems
May 24, 2024



In this work, we dive deep into one of the popular knowledge-grounded dialogue benchmarks that focus on faithfulness, FaithDial. We show that a significant portion of the FaithDial data contains annotation artifacts, which may bias models towards completely ignoring the conversation history. We therefore introduce CHARP, a diagnostic test set, designed for an improved evaluation of hallucinations in conversational model. CHARP not only measures hallucination but also the compliance of the models to the conversation task. Our extensive analysis reveals that models primarily exhibit poor performance on CHARP due to their inability to effectively attend to and reason over the conversation history. Furthermore, the evaluation methods of FaithDial fail to capture these shortcomings, neglecting the conversational history. Our findings indicate that there is substantial room for contribution in both dataset creation and hallucination evaluation for knowledge-grounded dialogue, and that CHARP can serve as a tool for monitoring the progress in this particular research area. CHARP is publicly available at https://huggingface.co/datasets/huawei-noah/CHARP
EUROPA: A Legal Multilingual Keyphrase Generation Dataset
Mar 01, 2024

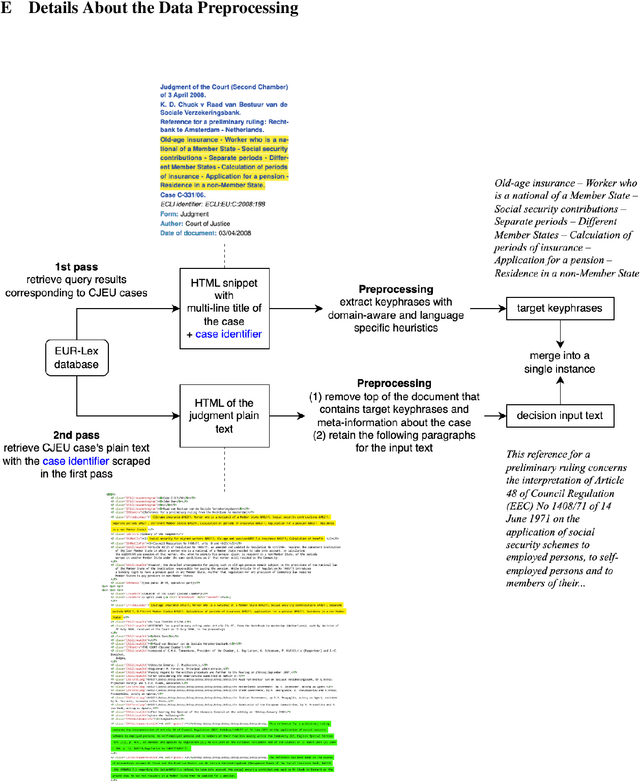
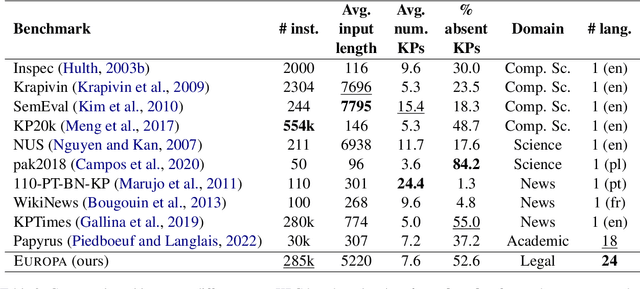
Keyphrase generation has primarily been explored within the context of academic research articles, with a particular focus on scientific domains and the English language. In this work, we present EUROPA, a dataset for multilingual keyphrase generation in the legal domain. It is derived from legal judgments from the Court of Justice of the European Union (EU), and contains instances in all 24 EU official languages. We run multilingual models on our corpus and analyze the results, showing room for improvement on a domain-specific multilingual corpus such as the one we present.
Data Augmentation is Dead, Long Live Data Augmentation
Feb 22, 2024Textual data augmentation (DA) is a prolific field of study where novel techniques to create artificial data are regularly proposed, and that has demonstrated great efficiency on small data settings, at least for text classification tasks. In this paper, we challenge those results, showing that classical data augmentation is simply a way of performing better fine-tuning, and that spending more time fine-tuning before applying data augmentation negates its effect. This is a significant contribution as it answers several questions that were left open in recent years, namely~: which DA technique performs best (all of them as long as they generate data close enough to the training set as to not impair training) and why did DA show positive results (facilitates training of network). We furthermore show that zero and few-shot data generation via conversational agents such as ChatGPT or LLama2 can increase performances, concluding that this form of data augmentation does still work, even if classical methods do not.
On the importance of Data Scale in Pretraining Arabic Language Models
Jan 15, 2024



Pretraining monolingual language models have been proven to be vital for performance in Arabic Natural Language Processing (NLP) tasks. In this paper, we conduct a comprehensive study on the role of data in Arabic Pretrained Language Models (PLMs). More precisely, we reassess the performance of a suite of state-of-the-art Arabic PLMs by retraining them on massive-scale, high-quality Arabic corpora. We have significantly improved the performance of the leading Arabic encoder-only BERT-base and encoder-decoder T5-base models on the ALUE and ORCA leaderboards, thereby reporting state-of-the-art results in their respective model categories. In addition, our analysis strongly suggests that pretraining data by far is the primary contributor to performance, surpassing other factors. Our models and source code are publicly available at https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/JABER-PyTorch.
LABO: Towards Learning Optimal Label Regularization via Bi-level Optimization
May 08, 2023



Regularization techniques are crucial to improving the generalization performance and training efficiency of deep neural networks. Many deep learning algorithms rely on weight decay, dropout, batch/layer normalization to converge faster and generalize. Label Smoothing (LS) is another simple, versatile and efficient regularization which can be applied to various supervised classification tasks. Conventional LS, however, regardless of the training instance assumes that each non-target class is equally likely. In this work, we present a general framework for training with label regularization, which includes conventional LS but can also model instance-specific variants. Based on this formulation, we propose an efficient way of learning LAbel regularization by devising a Bi-level Optimization (LABO) problem. We derive a deterministic and interpretable solution of the inner loop as the optimal label smoothing without the need to store the parameters or the output of a trained model. Finally, we conduct extensive experiments and demonstrate our LABO consistently yields improvement over conventional label regularization on various fields, including seven machine translation and three image classification tasks across various
Improving Generalization of Pre-trained Language Models via Stochastic Weight Averaging
Dec 16, 2022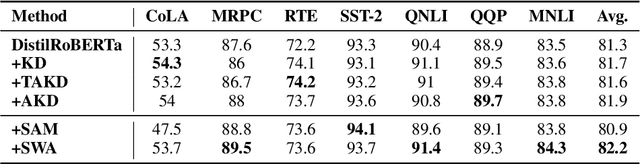
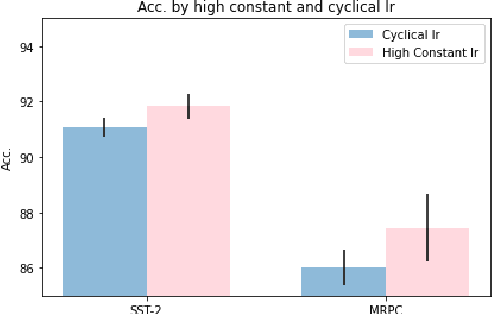
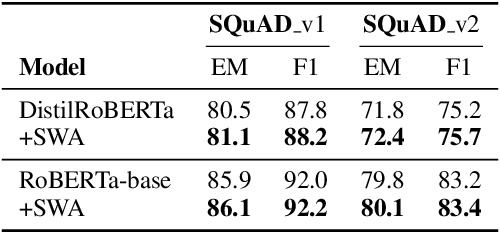
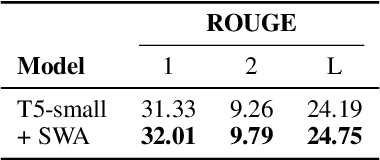
Knowledge Distillation (KD) is a commonly used technique for improving the generalization of compact Pre-trained Language Models (PLMs) on downstream tasks. However, such methods impose the additional burden of training a separate teacher model for every new dataset. Alternatively, one may directly work on the improvement of the optimization procedure of the compact model toward better generalization. Recent works observe that the flatness of the local minimum correlates well with better generalization. In this work, we adapt Stochastic Weight Averaging (SWA), a method encouraging convergence to a flatter minimum, to fine-tuning PLMs. We conduct extensive experiments on various NLP tasks (text classification, question answering, and generation) and different model architectures and demonstrate that our adaptation improves the generalization without extra computation cost. Moreover, we observe that this simple optimization technique is able to outperform the state-of-the-art KD methods for compact models.