 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEUROPA: A Legal Multilingual Keyphrase Generation Dataset
Mar 01, 2024

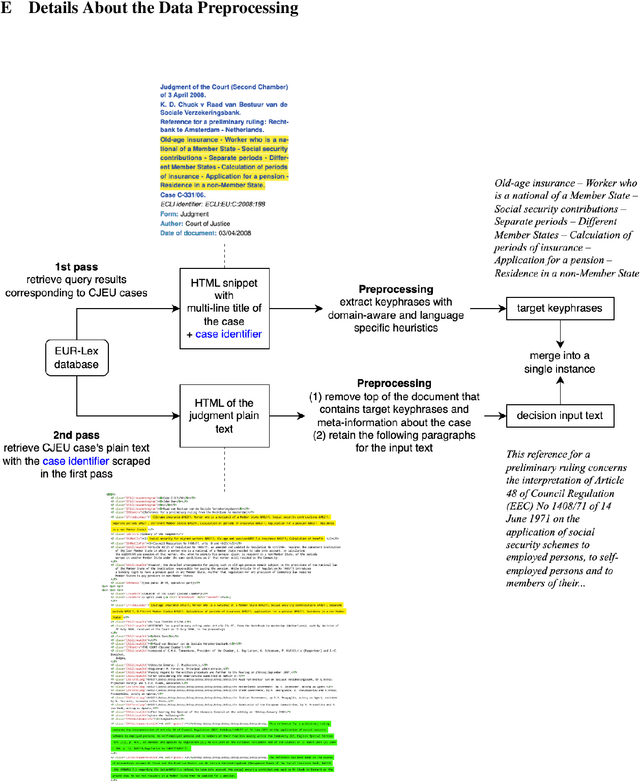
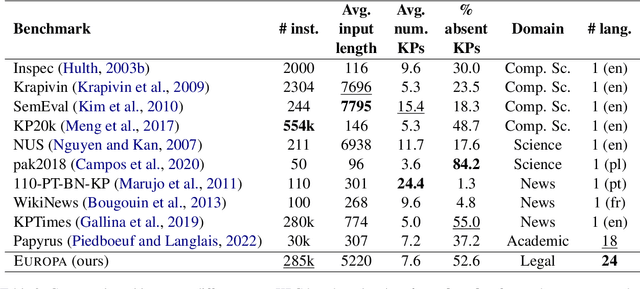
Keyphrase generation has primarily been explored within the context of academic research articles, with a particular focus on scientific domains and the English language. In this work, we present EUROPA, a dataset for multilingual keyphrase generation in the legal domain. It is derived from legal judgments from the Court of Justice of the European Union (EU), and contains instances in all 24 EU official languages. We run multilingual models on our corpus and analyze the results, showing room for improvement on a domain-specific multilingual corpus such as the one we present.
Data Augmentation is Dead, Long Live Data Augmentation
Feb 22, 2024Textual data augmentation (DA) is a prolific field of study where novel techniques to create artificial data are regularly proposed, and that has demonstrated great efficiency on small data settings, at least for text classification tasks. In this paper, we challenge those results, showing that classical data augmentation is simply a way of performing better fine-tuning, and that spending more time fine-tuning before applying data augmentation negates its effect. This is a significant contribution as it answers several questions that were left open in recent years, namely~: which DA technique performs best (all of them as long as they generate data close enough to the training set as to not impair training) and why did DA show positive results (facilitates training of network). We furthermore show that zero and few-shot data generation via conversational agents such as ChatGPT or LLama2 can increase performances, concluding that this form of data augmentation does still work, even if classical methods do not.