 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Deficiency for Task Inclusion Estimation
Mar 07, 2025Tasks are central in machine learning, as they are the most natural objects to assess the capabilities of current models. The trend is to build general models able to address any task. Even though transfer learning and multitask learning try to leverage the underlying task space, no well-founded tools are available to study its structure. This study proposes a theoretically grounded setup to define the notion of task and to compute the {\bf inclusion} between two tasks from a statistical deficiency point of view. We propose a tractable proxy as information sufficiency to estimate the degree of inclusion between tasks, show its soundness on synthetic data, and use it to reconstruct empirically the classic NLP pipeline.
A linguistically-motivated evaluation methodology for unraveling model's abilities in reading comprehension tasks
Jan 29, 2025We introduce an evaluation methodology for reading comprehension tasks based on the intuition that certain examples, by the virtue of their linguistic complexity, consistently yield lower scores regardless of model size or architecture. We capitalize on semantic frame annotation for characterizing this complexity, and study seven complexity factors that may account for model's difficulty. We first deploy this methodology on a carefully annotated French reading comprehension benchmark showing that two of those complexity factors are indeed good predictors of models' failure, while others are less so. We further deploy our methodology on a well studied English benchmark by using Chat-GPT as a proxy for semantic annotation. Our study reveals that fine-grained linguisticallymotivated automatic evaluation of a reading comprehension task is not only possible, but helps understand models' abilities to handle specific linguistic characteristics of input examples. It also shows that current state-of-the-art models fail with some for those characteristics which suggests that adequately handling them requires more than merely increasing model size.
TelcoLM: collecting data, adapting, and benchmarking language models for the telecommunication domain
Dec 20, 2024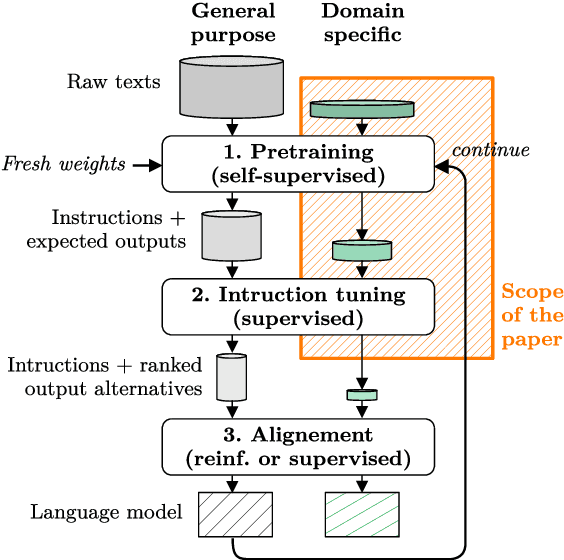

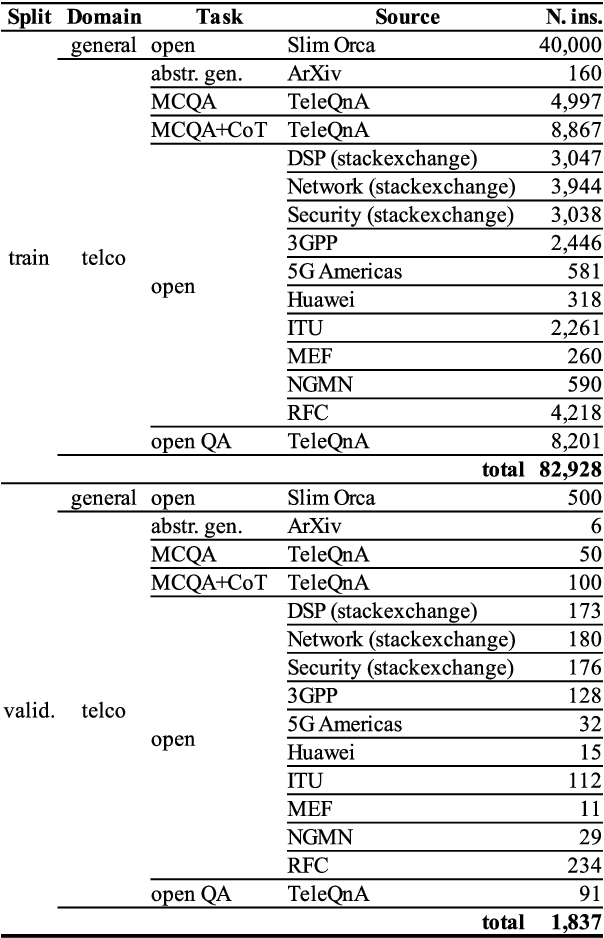

Despite outstanding processes in many tasks, Large Language Models (LLMs) still lack accuracy when dealing with highly technical domains. Especially, telecommunications (telco) is a particularly challenging domain due the large amount of lexical, semantic and conceptual peculiarities. Yet, this domain holds many valuable use cases, directly linked to industrial needs. Hence, this paper studies how LLMs can be adapted to the telco domain. It reports our effort to (i) collect a massive corpus of domain-specific data (800M tokens, 80K instructions), (ii) perform adaptation using various methodologies, and (iii) benchmark them against larger generalist models in downstream tasks that require extensive knowledge of telecommunications. Our experiments on Llama-2-7b show that domain-adapted models can challenge the large generalist models. They also suggest that adaptation can be restricted to a unique instruction-tuning step, dicarding the need for any fine-tuning on raw texts beforehand.
Spoken Conversational Search for General Knowledge
Sep 26, 2019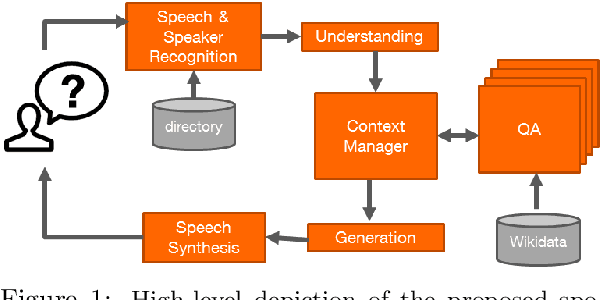

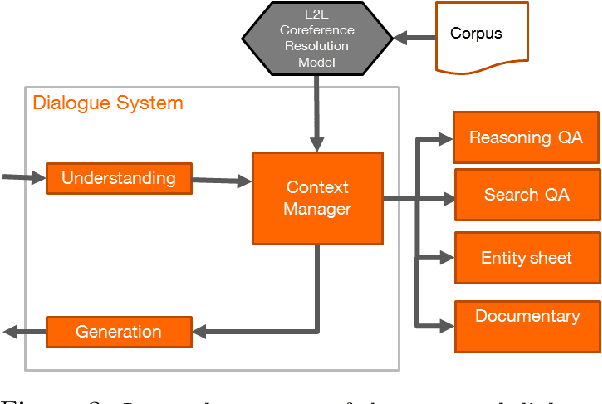
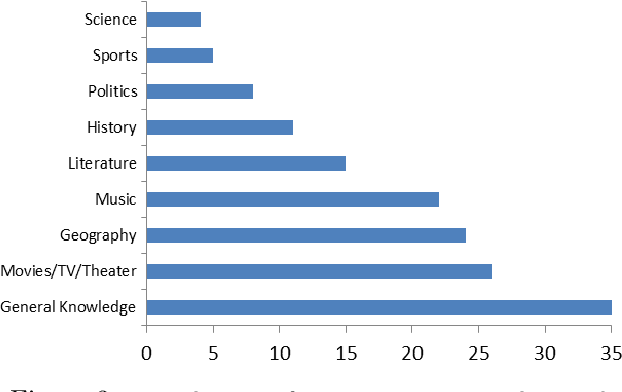
We present a spoken conversational question answering proof of concept that is able to answer questions about general knowledge from Wikidata. The dialogue component does not only orchestrate various components but also solve coreferences and ellipsis.
Sources of Complexity in Semantic Frame Parsing for Information Extraction
Dec 21, 2018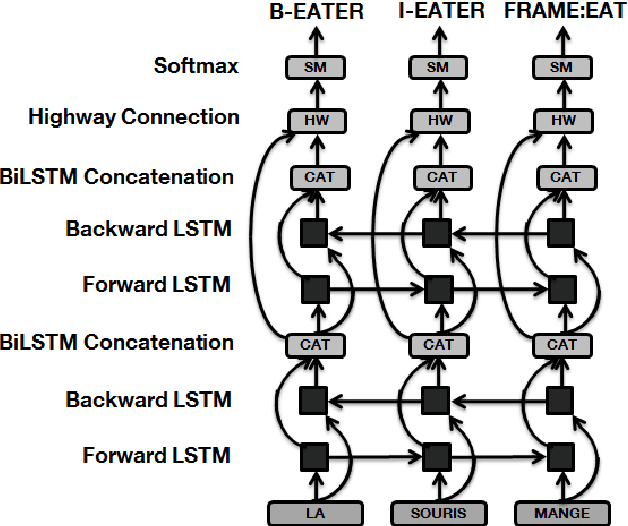

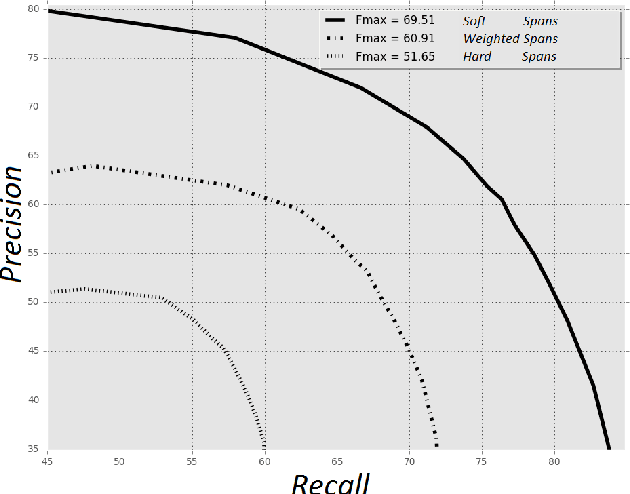
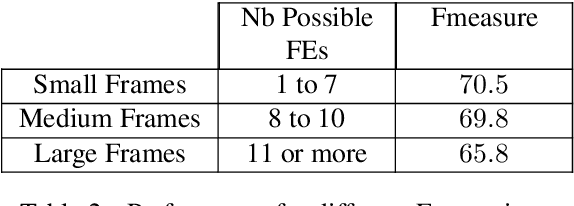
This paper describes a Semantic Frame parsing System based on sequence labeling methods, precisely BiLSTM models with highway connections, for performing information extraction on a corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The approach proposed in this study relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity, to highlight the factors that make Semantic Frame parsing a difficult task and to provide detailed evaluations of the performance on different types of frames and sentences.
FrameNet automatic analysis : a study on a French corpus of encyclopedic texts
Dec 19, 2018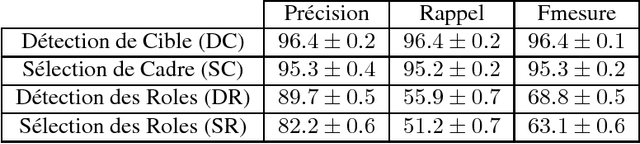



This article presents an automatic frame analysis system evaluated on a corpus of French encyclopedic history texts annotated according to the FrameNet formalism. The chosen approach relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity from several dimensions. Hence we provide detailed evaluations from a feature selection point of view and from the data point of view.
* in French
Semantic Frame Parsing for Information Extraction : the CALOR corpus
Dec 19, 2018


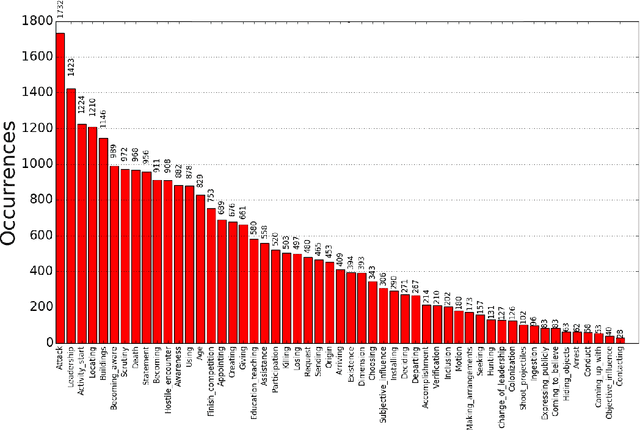
This paper presents a publicly available corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The main difference in our approach compared to previous works on semantic parsing with FrameNet is that we are not interested here in full text parsing but rather on partial parsing. The goal is to select from the FrameNet resources the minimal set of frames that are going to be useful for the applicative framework targeted, in our case Information Extraction from encyclopedic documents. Such an approach leverages the manual annotation of larger corpora than those obtained through full text parsing and therefore opens the door to alternative methods for Frame parsing than those used so far on the FrameNet 1.5 benchmark corpus. The approaches compared in this study rely on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The models compared are CRFs and multitasks bi-LSTMs.