 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models with Reasoning and Acting Meet the Needs of Task-Oriented Dialogue?
Dec 02, 2024



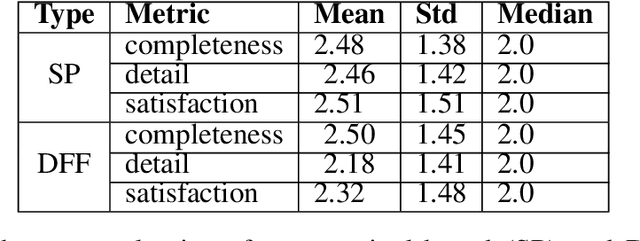
Large language models (LLMs) gained immense popularity due to their impressive capabilities in unstructured conversations. However, they underperform compared to previous approaches in task-oriented dialogue (TOD), wherein reasoning and accessing external information are crucial. Empowering LLMs with advanced prompting strategies such as reasoning and acting (ReAct) has shown promise in solving complex tasks traditionally requiring reinforcement learning. In this work, we apply the ReAct strategy to guide LLMs performing TOD. We evaluate ReAct-based LLMs (ReAct-LLMs) both in simulation and with real users. While ReAct-LLMs seem to underperform state-of-the-art approaches in simulation, human evaluation indicates higher user satisfaction rate compared to handcrafted systems despite having a lower success rate.
Talking to Machines: do you read me?
Jul 02, 2024
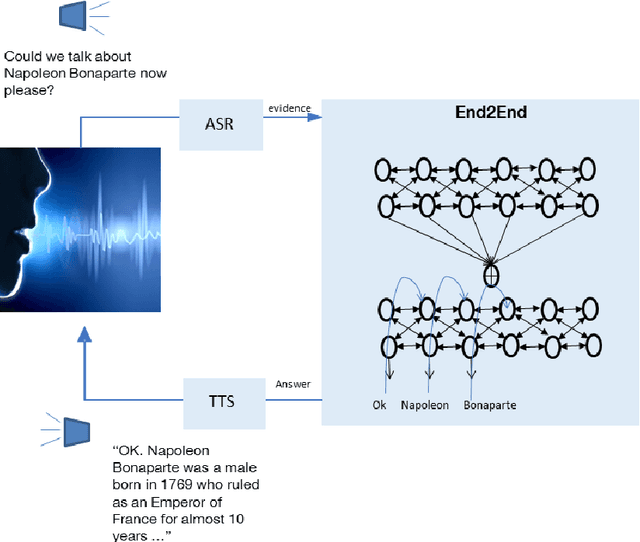
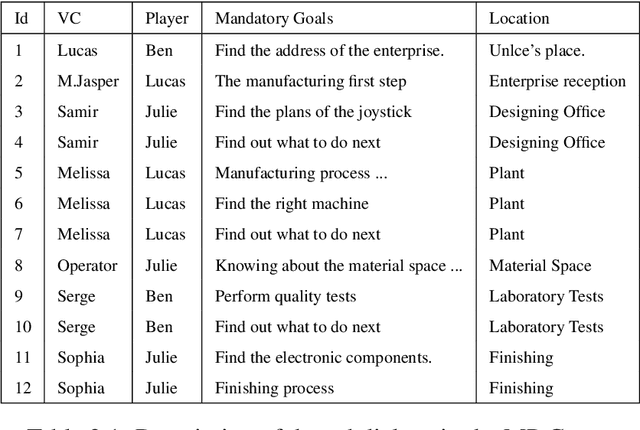

In this dissertation I would like to guide the reader to the research on dialogue but more precisely the research I have conducted during my career since my PhD thesis. Starting from modular architectures with machine learning/deep learning and reinforcement learning to end-to-end deep neural networks. Besides my work as research associate, I also present the work I have supervised in the last years. I review briefly the state of the art and highlight the open research problems on conversational agents. Afterwards, I present my contribution to Task-Oriented Dialogues (TOD), both as research associate and as the industrial supervisor of CIFRE theses. I discuss conversational QA. Particularly, I present the work of two PhD candidates Thibault Cordier and Sebastien Montella; as well as the work of the young researcher Quentin Brabant. Finally, I present the scientific project, where I discuss about Large Language Models (LLMs) for Task-Oriented Dialogue and Multimodal Task-Oriented Dialogue.
Question Generation in Knowledge-Driven Dialog: Explainability and Evaluation
Apr 11, 2024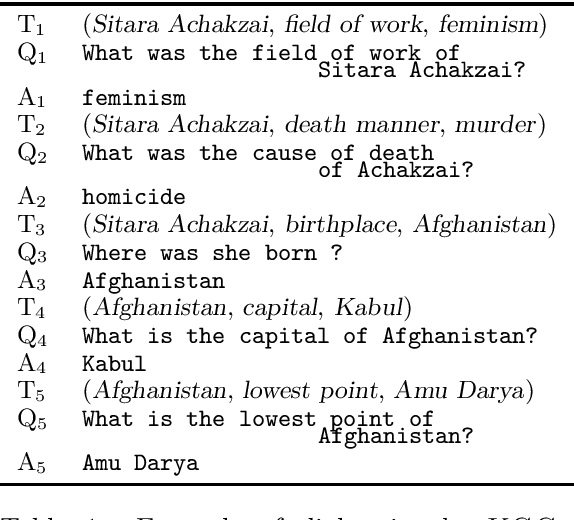



We explore question generation in the context of knowledge-grounded dialogs focusing on explainability and evaluation. Inspired by previous work on planning-based summarisation, we present a model which instead of directly generating a question, sequentially predicts first a fact then a question. We evaluate our approach on 37k test dialogs adapted from the KGConv dataset and we show that, although more demanding in terms of inference, our approach performs on par with a standard model which solely generates a question while allowing for a detailed referenceless evaluation of the model behaviour in terms of relevance, factuality and pronominalisation.
WEBDial, a Multi-domain, Multitask Statistical Dialogue Framework with RDF
Jan 08, 2024



Typically available dialogue frameworks have adopted a semantic representation based on dialogue-acts and slot-value pairs. Despite its simplicity, this representation has disadvantages such as the lack of expressivity, scalability and explainability. We present WEBDial: a dialogue framework that relies on a graph formalism by using RDF triples instead of slot-value pairs. We describe its overall architecture and the graph-based semantic representation. We show its applicability from simple to complex applications, by varying the complexity of domains and tasks: from single domain and tasks to multiple domains and complex tasks.
Unsupervised Auditory and Semantic Entrainment Models with Deep Neural Networks
Dec 22, 2023


Speakers tend to engage in adaptive behavior, known as entrainment, when they become similar to their interlocutor in various aspects of speaking. We present an unsupervised deep learning framework that derives meaningful representation from textual features for developing semantic entrainment. We investigate the model's performance by extracting features using different variations of the BERT model (DistilBERT and XLM-RoBERTa) and Google's universal sentence encoder (USE) embeddings on two human-human (HH) corpora (The Fisher Corpus English Part 1, Columbia games corpus) and one human-machine (HM) corpus (Voice Assistant Conversation Corpus (VACC)). In addition to semantic features we also trained DNN-based models utilizing two auditory embeddings (TRIpLet Loss network (TRILL) vectors, Low-level descriptors (LLD) features) and two units of analysis (Inter pausal unit and Turn). The results show that semantic entrainment can be assessed with our model, that models can distinguish between HH and HM interactions and that the two units of analysis for extracting acoustic features provide comparable findings.
KGConv, a Conversational Corpus grounded in Wikidata
Aug 29, 2023

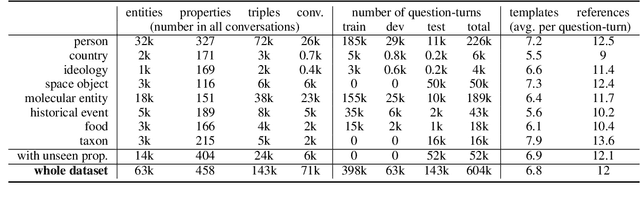

We present KGConv, a large, conversational corpus of 71k conversations where each question-answer pair is grounded in a Wikidata fact. Conversations contain on average 8.6 questions and for each Wikidata fact, we provide multiple variants (12 on average) of the corresponding question using templates, human annotations, hand-crafted rules and a question rewriting neural model. We provide baselines for the task of Knowledge-Based, Conversational Question Generation. KGConv can further be used for other generation and analysis tasks such as single-turn question generation from Wikidata triples, question rewriting, question answering from conversation or from knowledge graphs and quiz generation.
Interpreting Vision and Language Generative Models with Semantic Visual Priors
May 04, 2023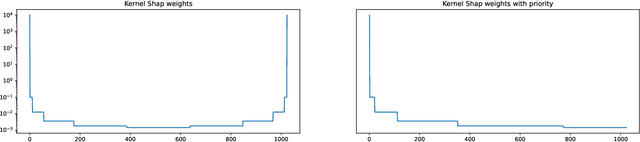

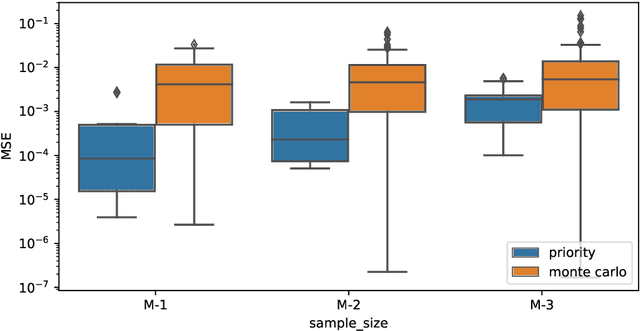
When applied to Image-to-text models, interpretability methods often provide token-by-token explanations namely, they compute a visual explanation for each token of the generated sequence. Those explanations are expensive to compute and unable to comprehensively explain the model's output. Therefore, these models often require some sort of approximation that eventually leads to misleading explanations. We develop a framework based on SHAP, that allows for generating comprehensive, meaningful explanations leveraging the meaning representation of the output sequence as a whole. Moreover, by exploiting semantic priors in the visual backbone, we extract an arbitrary number of features that allows the efficient computation of Shapley values on large-scale models, generating at the same time highly meaningful visual explanations. We demonstrate that our method generates semantically more expressive explanations than traditional methods at a lower compute cost and that it can be generalized over other explainability methods.
Few-Shot Structured Policy Learning for Multi-Domain and Multi-Task Dialogues
Feb 22, 2023



Reinforcement learning has been widely adopted to model dialogue managers in task-oriented dialogues. However, the user simulator provided by state-of-the-art dialogue frameworks are only rough approximations of human behaviour. The ability to learn from a small number of human interactions is hence crucial, especially on multi-domain and multi-task environments where the action space is large. We therefore propose to use structured policies to improve sample efficiency when learning on these kinds of environments. We also evaluate the impact of learning from human vs simulated experts. Among the different levels of structure that we tested, the graph neural networks (GNNs) show a remarkable superiority by reaching a success rate above 80% with only 50 dialogues, when learning from simulated experts. They also show superiority when learning from human experts, although a performance drop was observed, indicating a possible difficulty in capturing the variability of human strategies. We therefore suggest to concentrate future research efforts on bridging the gap between human data, simulators and automatic evaluators in dialogue frameworks.
Investigating the Effect of Relative Positional Embeddings on AMR-to-Text Generation with Structural Adapters
Feb 12, 2023



Text generation from Abstract Meaning Representation (AMR) has substantially benefited from the popularized Pretrained Language Models (PLMs). Myriad approaches have linearized the input graph as a sequence of tokens to fit the PLM tokenization requirements. Nevertheless, this transformation jeopardizes the structural integrity of the graph and is therefore detrimental to its resulting representation. To overcome this issue, Ribeiro et al. have recently proposed StructAdapt, a structure-aware adapter which injects the input graph connectivity within PLMs using Graph Neural Networks (GNNs). In this paper, we investigate the influence of Relative Position Embeddings (RPE) on AMR-to-Text, and, in parallel, we examine the robustness of StructAdapt. Through ablation studies, graph attack and link prediction, we reveal that RPE might be partially encoding input graphs. We suggest further research regarding the role of RPE will provide valuable insights for Graph-to-Text generation.
Graph Neural Network Policies and Imitation Learning for Multi-Domain Task-Oriented Dialogues
Oct 11, 2022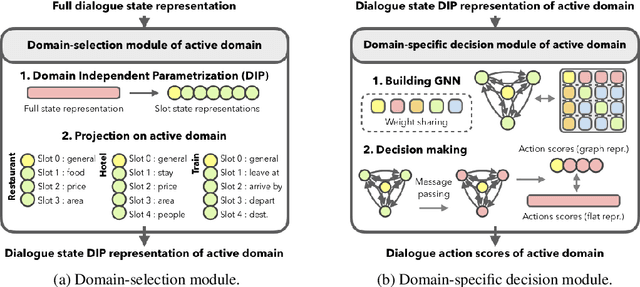

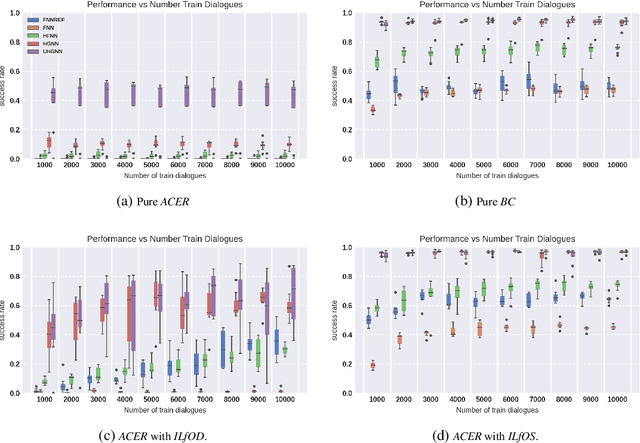
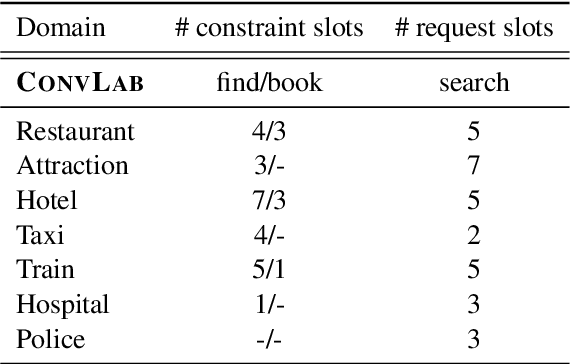
Task-oriented dialogue systems are designed to achieve specific goals while conversing with humans. In practice, they may have to handle simultaneously several domains and tasks. The dialogue manager must therefore be able to take into account domain changes and plan over different domains/tasks in order to deal with multidomain dialogues. However, learning with reinforcement in such context becomes difficult because the state-action dimension is larger while the reward signal remains scarce. Our experimental results suggest that structured policies based on graph neural networks combined with different degrees of imitation learning can effectively handle multi-domain dialogues. The reported experiments underline the benefit of structured policies over standard policies.