 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Temporal Factual Knowledge in Language Models
Feb 03, 2025This paper explores the temporal robustness of language models (LMs) in handling factual knowledge. While LMs can often complete simple factual statements, their ability to manage temporal facts (those valid only within specific timeframes) remains uncertain. We design a controlled experiment to test the robustness of temporal factual knowledge inside LMs, which we use to evaluate several pretrained and instruction-tuned models using prompts on popular Wikidata facts, assessing their performance across different temporal granularities (Day, Month, and Year). Our findings indicate that even very large state-of-the-art models, such as Llama-3.1-70B, vastly lack robust knowledge of temporal facts. In addition, they are incapable of generalizing their knowledge from one granularity to another. These results highlight the inherent limitations of using LMs as temporal knowledge bases. The source code and data to reproduce our experiments will be released.
WikiFactDiff: A Large, Realistic, and Temporally Adaptable Dataset for Atomic Factual Knowledge Update in Causal Language Models
Mar 21, 2024The factuality of large language model (LLMs) tends to decay over time since events posterior to their training are "unknown" to them. One way to keep models up-to-date could be factual update: the task of inserting, replacing, or removing certain simple (atomic) facts within the model. To study this task, we present WikiFactDiff, a dataset that describes the evolution of factual knowledge between two dates as a collection of simple facts divided into three categories: new, obsolete, and static. We describe several update scenarios arising from various combinations of these three types of basic update. The facts are represented by subject-relation-object triples; indeed, WikiFactDiff was constructed by comparing the state of the Wikidata knowledge base at 4 January 2021 and 27 February 2023. Those fact are accompanied by verbalization templates and cloze tests that enable running update algorithms and their evaluation metrics. Contrary to other datasets, such as zsRE and CounterFact, WikiFactDiff constitutes a realistic update setting that involves various update scenarios, including replacements, archival, and new entity insertions. We also present an evaluation of existing update algorithms on WikiFactDiff.
Investigating the Effect of Relative Positional Embeddings on AMR-to-Text Generation with Structural Adapters
Feb 12, 2023



Text generation from Abstract Meaning Representation (AMR) has substantially benefited from the popularized Pretrained Language Models (PLMs). Myriad approaches have linearized the input graph as a sequence of tokens to fit the PLM tokenization requirements. Nevertheless, this transformation jeopardizes the structural integrity of the graph and is therefore detrimental to its resulting representation. To overcome this issue, Ribeiro et al. have recently proposed StructAdapt, a structure-aware adapter which injects the input graph connectivity within PLMs using Graph Neural Networks (GNNs). In this paper, we investigate the influence of Relative Position Embeddings (RPE) on AMR-to-Text, and, in parallel, we examine the robustness of StructAdapt. Through ablation studies, graph attack and link prediction, we reveal that RPE might be partially encoding input graphs. We suggest further research regarding the role of RPE will provide valuable insights for Graph-to-Text generation.
Dependency Parsing with Backtracking using Deep Reinforcement Learning
Jun 28, 2022
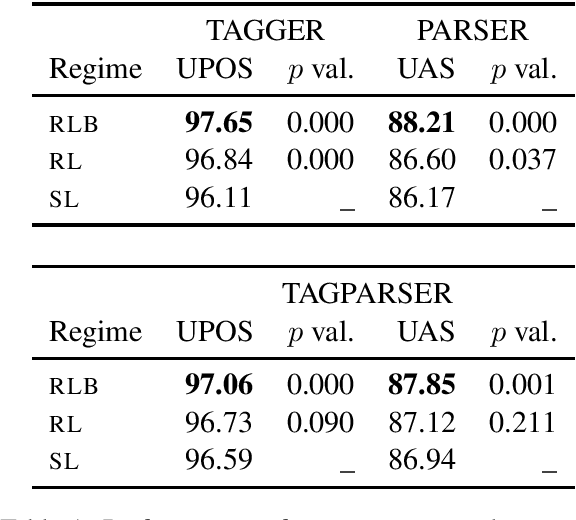
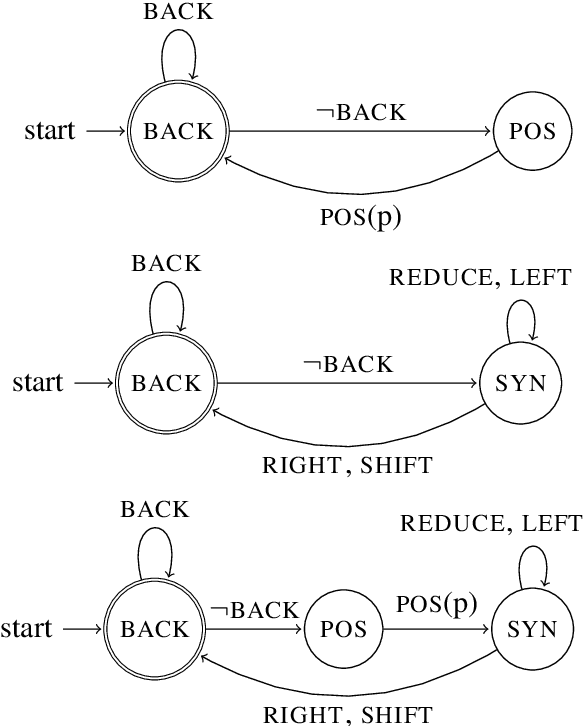
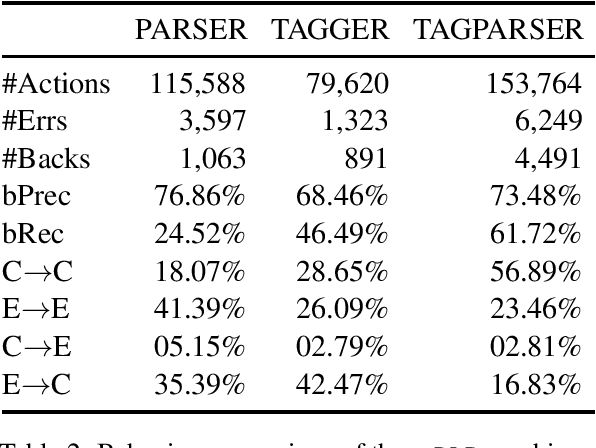
Greedy algorithms for NLP such as transition based parsing are prone to error propagation. One way to overcome this problem is to allow the algorithm to backtrack and explore an alternative solution in cases where new evidence contradicts the solution explored so far. In order to implement such a behavior, we use reinforcement learning and let the algorithm backtrack in cases where such an action gets a better reward than continuing to explore the current solution. We test this idea on both POS tagging and dependency parsing and show that backtracking is an effective means to fight against error propagation.
Genetic Neural Architecture Search for automatic assessment of human sperm images
Sep 20, 2019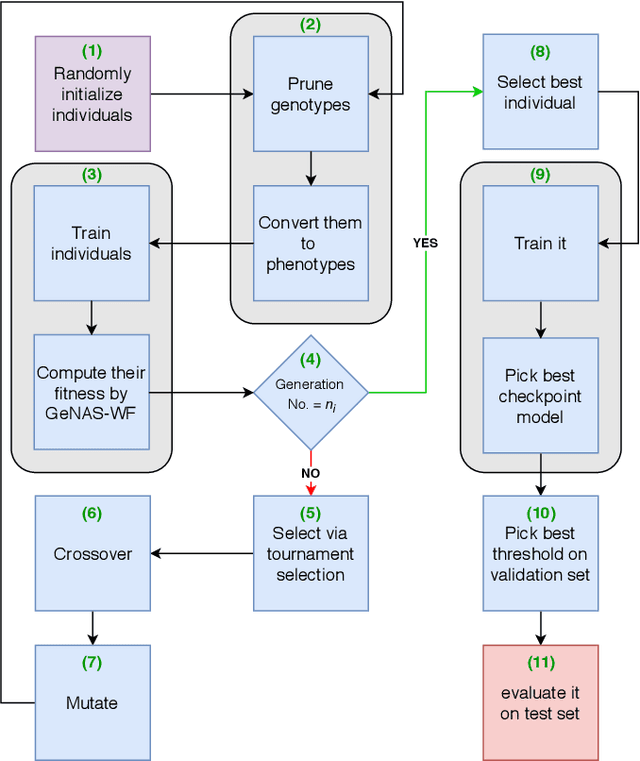
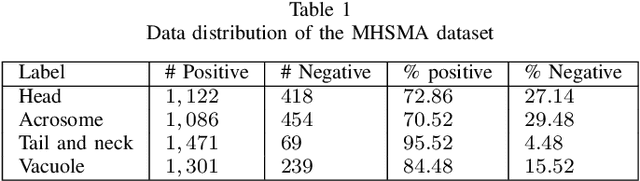
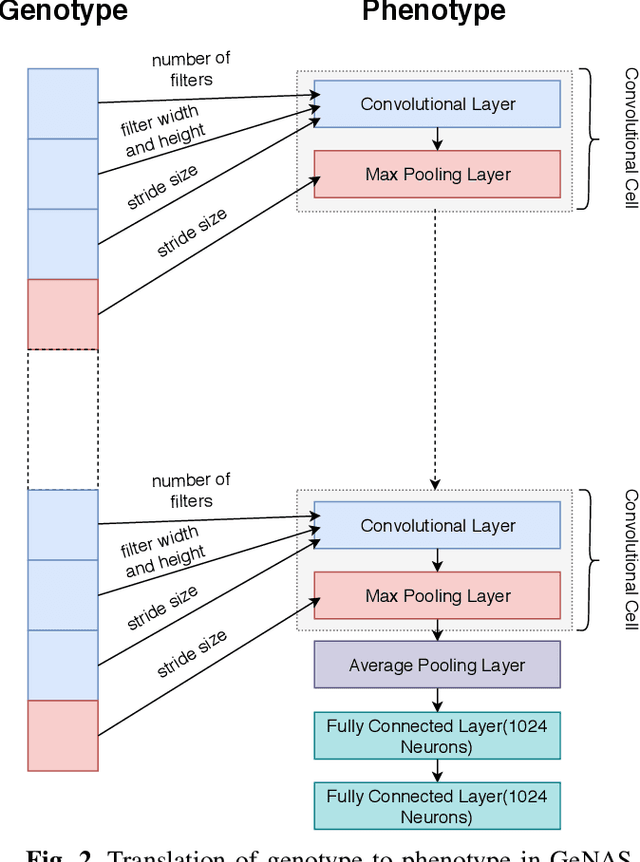
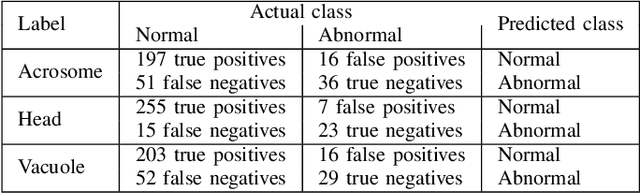
Male infertility is a disease which affects approximately 7% of men. Sperm morphology analysis (SMA) is one of the main diagnosis methods for this problem. Manual SMA is an inexact, subjective, non-reproducible, and hard to teach process. As a result, in this paper, we introduce a novel automatic SMA based on a neural architecture search algorithm termed Genetic Neural Architecture Search (GeNAS). For this purpose, we used a collection of images called MHSMA dataset contains 1,540 sperm images which have been collected from 235 patients with infertility problems. GeNAS is a genetic algorithm that acts as a meta-controller which explores the constrained search space of plain convolutional neural network architectures. Every individual of the genetic algorithm is a convolutional neural network trained to predict morphological deformities in different segments of human sperm (head, vacuole, and acrosome), and its fitness is calculated by a novel proposed method named GeNAS-WF especially designed for noisy, low resolution, and imbalanced datasets. Also, a hashing method is used to save each trained neural architecture fitness, so we could reuse them during fitness evaluation and speed up the algorithm. Besides, in terms of running time and computation power, our proposed architecture search method is far more efficient than most of the other existing neural architecture search algorithms. Additionally, other proposed methods have been evaluated on balanced datasets, whereas GeNAS is built specifically for noisy, low quality, and imbalanced datasets which are common in the field of medical imaging. In our experiments, the best neural architecture found by GeNAS has reached an accuracy of 92.66%, 77.33%, and 77.66% in the vacuole, head, and acrosome abnormality detection, respectively. In comparison to other proposed algorithms for MHSMA dataset, GeNAS achieved state-of-the-art results.
Sources of Complexity in Semantic Frame Parsing for Information Extraction
Dec 21, 2018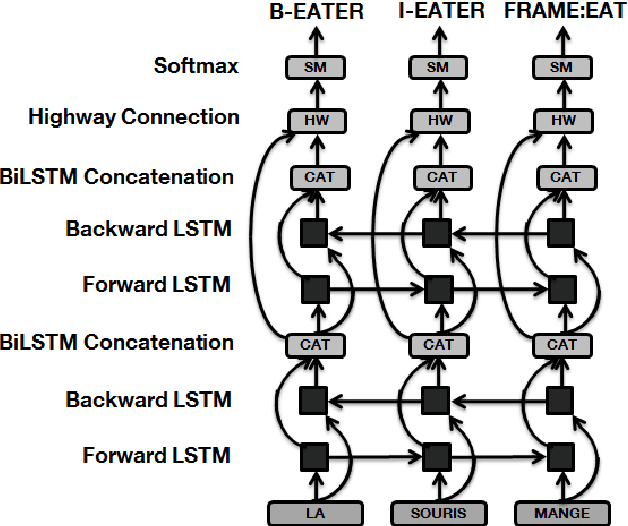

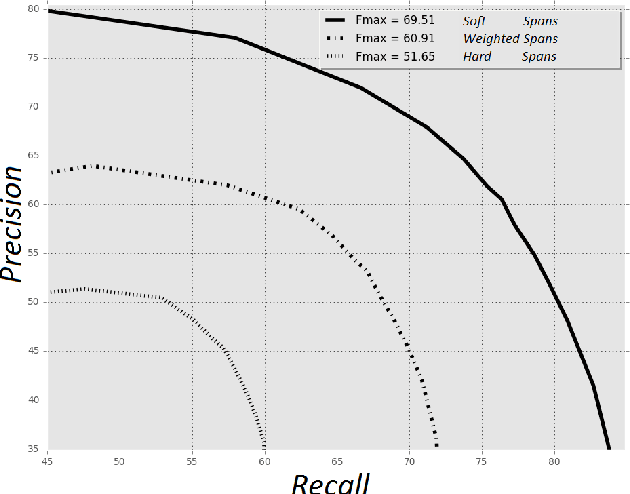
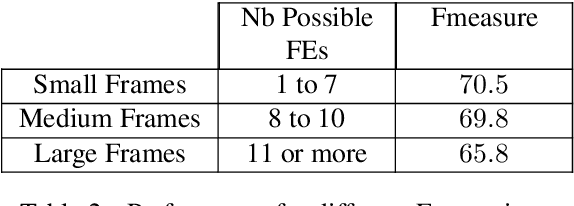
This paper describes a Semantic Frame parsing System based on sequence labeling methods, precisely BiLSTM models with highway connections, for performing information extraction on a corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The approach proposed in this study relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity, to highlight the factors that make Semantic Frame parsing a difficult task and to provide detailed evaluations of the performance on different types of frames and sentences.
Semantic Frame Parsing for Information Extraction : the CALOR corpus
Dec 19, 2018


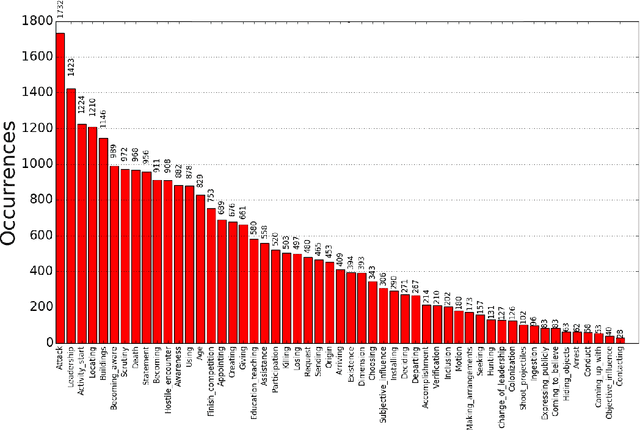
This paper presents a publicly available corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The main difference in our approach compared to previous works on semantic parsing with FrameNet is that we are not interested here in full text parsing but rather on partial parsing. The goal is to select from the FrameNet resources the minimal set of frames that are going to be useful for the applicative framework targeted, in our case Information Extraction from encyclopedic documents. Such an approach leverages the manual annotation of larger corpora than those obtained through full text parsing and therefore opens the door to alternative methods for Frame parsing than those used so far on the FrameNet 1.5 benchmark corpus. The approaches compared in this study rely on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The models compared are CRFs and multitasks bi-LSTMs.