 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Temporal Factual Knowledge in Language Models
Feb 03, 2025This paper explores the temporal robustness of language models (LMs) in handling factual knowledge. While LMs can often complete simple factual statements, their ability to manage temporal facts (those valid only within specific timeframes) remains uncertain. We design a controlled experiment to test the robustness of temporal factual knowledge inside LMs, which we use to evaluate several pretrained and instruction-tuned models using prompts on popular Wikidata facts, assessing their performance across different temporal granularities (Day, Month, and Year). Our findings indicate that even very large state-of-the-art models, such as Llama-3.1-70B, vastly lack robust knowledge of temporal facts. In addition, they are incapable of generalizing their knowledge from one granularity to another. These results highlight the inherent limitations of using LMs as temporal knowledge bases. The source code and data to reproduce our experiments will be released.
WikiFactDiff: A Large, Realistic, and Temporally Adaptable Dataset for Atomic Factual Knowledge Update in Causal Language Models
Mar 21, 2024The factuality of large language model (LLMs) tends to decay over time since events posterior to their training are "unknown" to them. One way to keep models up-to-date could be factual update: the task of inserting, replacing, or removing certain simple (atomic) facts within the model. To study this task, we present WikiFactDiff, a dataset that describes the evolution of factual knowledge between two dates as a collection of simple facts divided into three categories: new, obsolete, and static. We describe several update scenarios arising from various combinations of these three types of basic update. The facts are represented by subject-relation-object triples; indeed, WikiFactDiff was constructed by comparing the state of the Wikidata knowledge base at 4 January 2021 and 27 February 2023. Those fact are accompanied by verbalization templates and cloze tests that enable running update algorithms and their evaluation metrics. Contrary to other datasets, such as zsRE and CounterFact, WikiFactDiff constitutes a realistic update setting that involves various update scenarios, including replacements, archival, and new entity insertions. We also present an evaluation of existing update algorithms on WikiFactDiff.
Application of WGAN-GP in recommendation and Questioning the relevance of GAN-based approaches
Apr 28, 2022
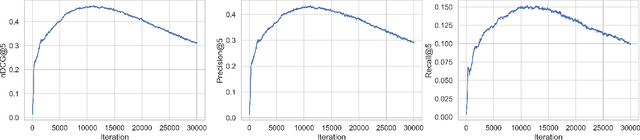
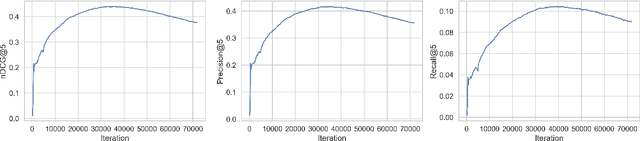
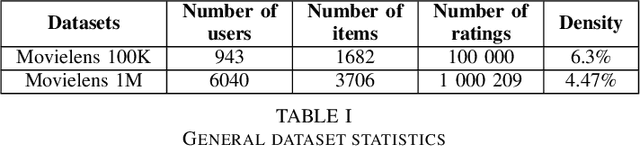
Many neural-based recommender systems were proposed in recent years and part of them used Generative Adversarial Networks (GAN) to model user-item interactions. However, the exploration of Wasserstein GAN with Gradient Penalty (WGAN-GP) on recommendation has received relatively less scrutiny. In this paper, we focus on two questions: 1- Can we successfully apply WGAN-GP on recommendation and does this approach give an advantage compared to the best GAN models? 2- Are GAN-based recommender systems relevant? To answer the first question, we propose a recommender system based on WGAN-GP called CFWGAN-GP which is founded on a previous model (CFGAN). We successfully applied our method on real-world datasets on the top-k recommendation task and the empirical results show that it is competitive with state-of-the-art GAN approaches, but we found no evidence of significant advantage of using WGAN-GP instead of the original GAN, at least from the accuracy point of view. As for the second question, we conduct a simple experiment in which we show that a well-tuned conceptually simpler method outperforms GAN-based models by a considerable margin, questioning the use of such models.