 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Deficiency for Task Inclusion Estimation
Mar 07, 2025Tasks are central in machine learning, as they are the most natural objects to assess the capabilities of current models. The trend is to build general models able to address any task. Even though transfer learning and multitask learning try to leverage the underlying task space, no well-founded tools are available to study its structure. This study proposes a theoretically grounded setup to define the notion of task and to compute the {\bf inclusion} between two tasks from a statistical deficiency point of view. We propose a tractable proxy as information sufficiency to estimate the degree of inclusion between tasks, show its soundness on synthetic data, and use it to reconstruct empirically the classic NLP pipeline.
On the Robustness of Temporal Factual Knowledge in Language Models
Feb 03, 2025This paper explores the temporal robustness of language models (LMs) in handling factual knowledge. While LMs can often complete simple factual statements, their ability to manage temporal facts (those valid only within specific timeframes) remains uncertain. We design a controlled experiment to test the robustness of temporal factual knowledge inside LMs, which we use to evaluate several pretrained and instruction-tuned models using prompts on popular Wikidata facts, assessing their performance across different temporal granularities (Day, Month, and Year). Our findings indicate that even very large state-of-the-art models, such as Llama-3.1-70B, vastly lack robust knowledge of temporal facts. In addition, they are incapable of generalizing their knowledge from one granularity to another. These results highlight the inherent limitations of using LMs as temporal knowledge bases. The source code and data to reproduce our experiments will be released.
TelcoLM: collecting data, adapting, and benchmarking language models for the telecommunication domain
Dec 20, 2024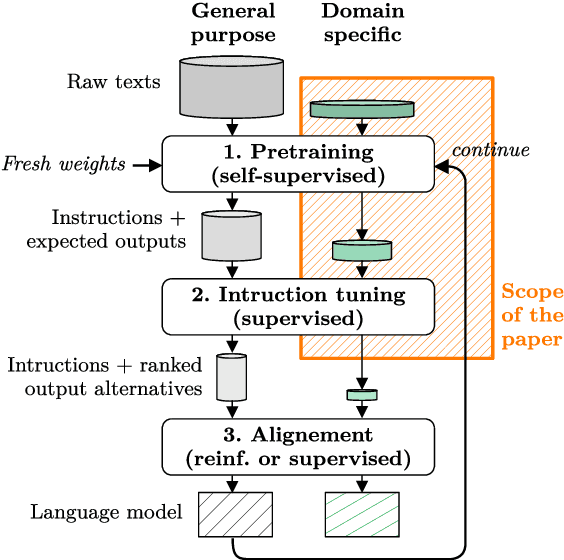

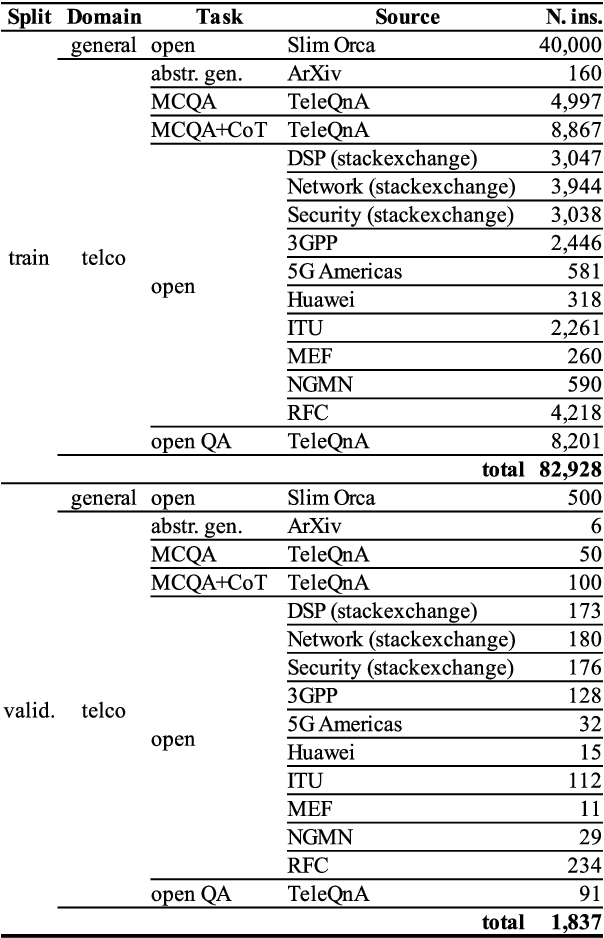

Despite outstanding processes in many tasks, Large Language Models (LLMs) still lack accuracy when dealing with highly technical domains. Especially, telecommunications (telco) is a particularly challenging domain due the large amount of lexical, semantic and conceptual peculiarities. Yet, this domain holds many valuable use cases, directly linked to industrial needs. Hence, this paper studies how LLMs can be adapted to the telco domain. It reports our effort to (i) collect a massive corpus of domain-specific data (800M tokens, 80K instructions), (ii) perform adaptation using various methodologies, and (iii) benchmark them against larger generalist models in downstream tasks that require extensive knowledge of telecommunications. Our experiments on Llama-2-7b show that domain-adapted models can challenge the large generalist models. They also suggest that adaptation can be restricted to a unique instruction-tuning step, dicarding the need for any fine-tuning on raw texts beforehand.
Emotion Identification for French in Written Texts: Considering their Modes of Expression as a Step Towards Text Complexity Analysis
May 23, 2024The objective of this paper is to predict (A) whether a sentence in a written text expresses an emotion, (B) the mode(s) in which it is expressed, (C) whether it is basic or complex, and (D) its emotional category. One of our major contributions, through a dataset and a model, is to integrate the fact that an emotion can be expressed in different modes: from a direct mode, essentially lexicalized, to a more indirect mode, where emotions will only be suggested, a mode that NLP approaches generally don't take into account. Another originality is that the scope is on written texts, as opposed usual work focusing on conversational (often multi-modal) data. In this context, modes of expression are seen as a factor towards the automatic analysis of complexity in texts. Experiments on French texts show acceptable results compared to the human annotators' agreement, and outperforming results compared to using a large language model with in-context learning (i.e. no fine-tuning).
WikiFactDiff: A Large, Realistic, and Temporally Adaptable Dataset for Atomic Factual Knowledge Update in Causal Language Models
Mar 21, 2024The factuality of large language model (LLMs) tends to decay over time since events posterior to their training are "unknown" to them. One way to keep models up-to-date could be factual update: the task of inserting, replacing, or removing certain simple (atomic) facts within the model. To study this task, we present WikiFactDiff, a dataset that describes the evolution of factual knowledge between two dates as a collection of simple facts divided into three categories: new, obsolete, and static. We describe several update scenarios arising from various combinations of these three types of basic update. The facts are represented by subject-relation-object triples; indeed, WikiFactDiff was constructed by comparing the state of the Wikidata knowledge base at 4 January 2021 and 27 February 2023. Those fact are accompanied by verbalization templates and cloze tests that enable running update algorithms and their evaluation metrics. Contrary to other datasets, such as zsRE and CounterFact, WikiFactDiff constitutes a realistic update setting that involves various update scenarios, including replacements, archival, and new entity insertions. We also present an evaluation of existing update algorithms on WikiFactDiff.
Age Recommendation from Texts and Sentences for Children
Aug 21, 2023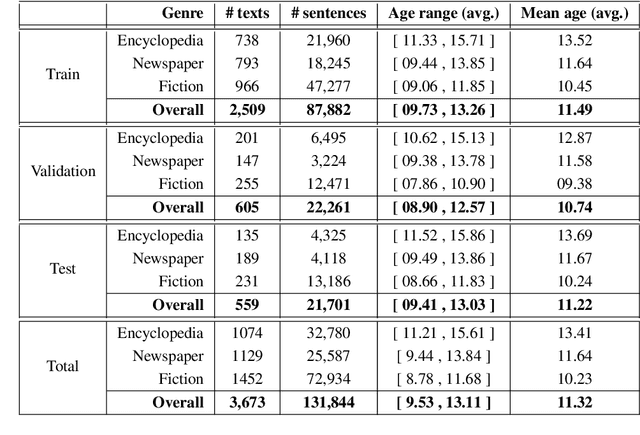
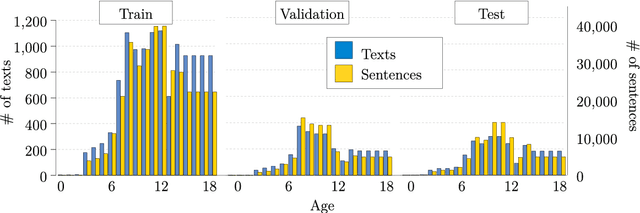

Children have less text understanding capability than adults. Moreover, this capability differs among the children of different ages. Hence, automatically predicting a recommended age based on texts or sentences would be a great benefit to propose adequate texts to children and to help authors writing in the most appropriate way. This paper presents our recent advances on the age recommendation task. We consider age recommendation as a regression task, and discuss the need for appropriate evaluation metrics, study the use of state-of-the-art machine learning model, namely Transformers, and compare it to different models coming from the literature. Our results are also compared with recommendations made by experts. Further, this paper deals with preliminary explainability of the age prediction model by analyzing various linguistic features. We conduct the experiments on a dataset of 3, 673 French texts (132K sentences, 2.5M words). To recommend age at the text level and sentence level, our best models achieve MAE scores of 0.98 and 1.83 respectively on the test set. Also, compared to the recommendations made by experts, our sentence-level recommendation model gets a similar score to the experts, while the text-level recommendation model outperforms the experts by an MAE score of 1.48.