 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning and Natural Language Processing in the Field of Construction
Jan 14, 2025This article presents a complete process to extract hypernym relationships in the field of construction using two main steps: terminology extraction and detection of hypernyms from these terms. We first describe the corpus analysis method to extract terminology from a collection of technical specifications in the field of construction. Using statistics and word n-grams analysis, we extract the domain's terminology and then perform pruning steps with linguistic patterns and internet queries to improve the quality of the final terminology. Second, we present a machine-learning approach based on various words embedding models and combinations to deal with the detection of hypernyms from the extracted terminology. Extracted terminology is evaluated using a manual evaluation carried out by 6 experts in the domain, and the hypernym identification method is evaluated with different datasets. The global approach provides relevant and promising results.
WikiNER-fr-gold: A Gold-Standard NER Corpus
Oct 29, 2024


We address in this article the the quality of the WikiNER corpus, a multilingual Named Entity Recognition corpus, and provide a consolidated version of it. The annotation of WikiNER was produced in a semi-supervised manner i.e. no manual verification has been carried out a posteriori. Such corpus is called silver-standard. In this paper we propose WikiNER-fr-gold which is a revised version of the French proportion of WikiNER. Our corpus consists of randomly sampled 20% of the original French sub-corpus (26,818 sentences with 700k tokens). We start by summarizing the entity types included in each category in order to define an annotation guideline, and then we proceed to revise the corpus. Finally we present an analysis of errors and inconsistency observed in the WikiNER-fr corpus, and we discuss potential future work directions.
Age Recommendation from Texts and Sentences for Children
Aug 21, 2023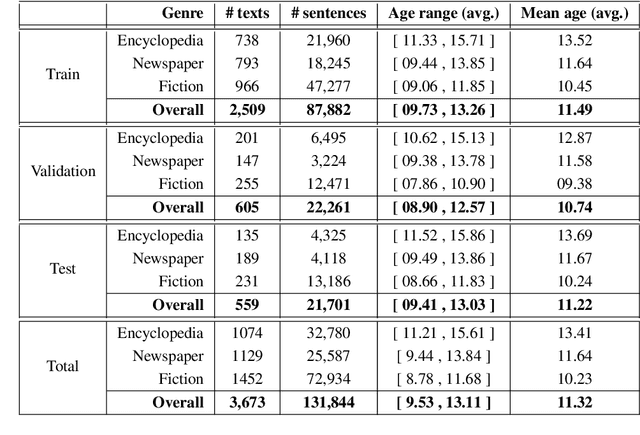
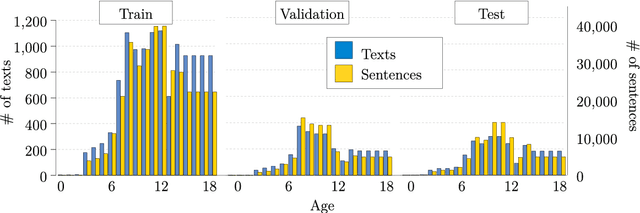

Children have less text understanding capability than adults. Moreover, this capability differs among the children of different ages. Hence, automatically predicting a recommended age based on texts or sentences would be a great benefit to propose adequate texts to children and to help authors writing in the most appropriate way. This paper presents our recent advances on the age recommendation task. We consider age recommendation as a regression task, and discuss the need for appropriate evaluation metrics, study the use of state-of-the-art machine learning model, namely Transformers, and compare it to different models coming from the literature. Our results are also compared with recommendations made by experts. Further, this paper deals with preliminary explainability of the age prediction model by analyzing various linguistic features. We conduct the experiments on a dataset of 3, 673 French texts (132K sentences, 2.5M words). To recommend age at the text level and sentence level, our best models achieve MAE scores of 0.98 and 1.83 respectively on the test set. Also, compared to the recommendations made by experts, our sentence-level recommendation model gets a similar score to the experts, while the text-level recommendation model outperforms the experts by an MAE score of 1.48.
Hybrid Isolation Forest - Application to Intrusion Detection
May 10, 2017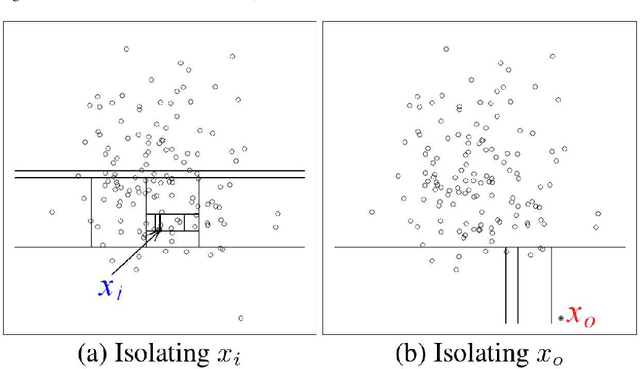
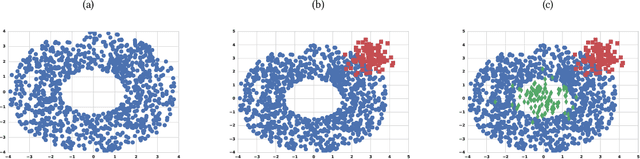
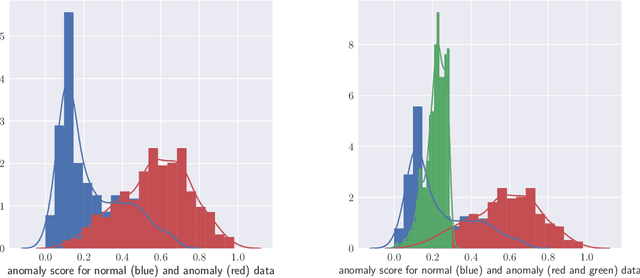
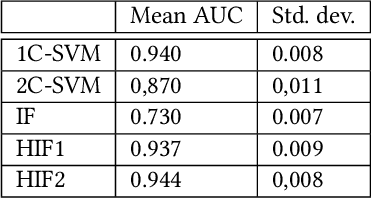
From the identification of a drawback in the Isolation Forest (IF) algorithm that limits its use in the scope of anomaly detection, we propose two extensions that allow to firstly overcome the previously mention limitation and secondly to provide it with some supervised learning capability. The resulting Hybrid Isolation Forest (HIF) that we propose is first evaluated on a synthetic dataset to analyze the effect of the new meta-parameters that are introduced and verify that the addressed limitation of the IF algorithm is effectively overcame. We hen compare the two algorithms on the ISCX benchmark dataset, in the context of a network intrusion detection application. Our experiments show that HIF outperforms IF, but also challenges the 1-class and 2-classes SVM baselines with computational efficiency.