 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute, Retrieve, Reflect, Repair: Self-Improving Agentic Framework for Visual Detection and Linguistic Reasoning in Medical Imaging
Jan 13, 2026Medical image analysis increasingly relies on large vision-language models (VLMs), yet most systems remain single-pass black boxes that offer limited control over reasoning, safety, and spatial grounding. We propose R^4, an agentic framework that decomposes medical imaging workflows into four coordinated agents: a Router that configures task- and specialization-aware prompts from the image, patient history, and metadata; a Retriever that uses exemplar memory and pass@k sampling to jointly generate free-text reports and bounding boxes; a Reflector that critiques each draft-box pair for key clinical error modes (negation, laterality, unsupported claims, contradictions, missing findings, and localization errors); and a Repairer that iteratively revises both narrative and spatial outputs under targeted constraints while curating high-quality exemplars for future cases. Instantiated on chest X-ray analysis with multiple modern VLM backbones and evaluated on report generation and weakly supervised detection, R^4 consistently boosts LLM-as-a-Judge scores by roughly +1.7-+2.5 points and mAP50 by +2.5-+3.5 absolute points over strong single-VLM baselines, without any gradient-based fine-tuning. These results show that agentic routing, reflection, and repair can turn strong but brittle VLMs into more reliable and better grounded tools for clinical image interpretation. Our code can be found at: https://github.com/faiyazabdullah/MultimodalMedAgent
Invisible Yet Detected: PelFANet with Attention-Guided Anatomical Fusion for Pelvic Fracture Diagnosis
Sep 17, 2025Pelvic fractures pose significant diagnostic challenges, particularly in cases where fracture signs are subtle or invisible on standard radiographs. To address this, we introduce PelFANet, a dual-stream attention network that fuses raw pelvic X-rays with segmented bone images to improve fracture classification. The network em-ploys Fused Attention Blocks (FABlocks) to iteratively exchange and refine fea-tures from both inputs, capturing global context and localized anatomical detail. Trained in a two-stage pipeline with a segmentation-guided approach, PelFANet demonstrates superior performance over conventional methods. On the AMERI dataset, it achieves 88.68% accuracy and 0.9334 AUC on visible fractures, while generalizing effectively to invisible fracture cases with 82.29% accuracy and 0.8688 AUC, despite not being trained on them. These results highlight the clini-cal potential of anatomy-aware dual-input architectures for robust fracture detec-tion, especially in scenarios with subtle radiographic presentations.
Age Recommendation from Texts and Sentences for Children
Aug 21, 2023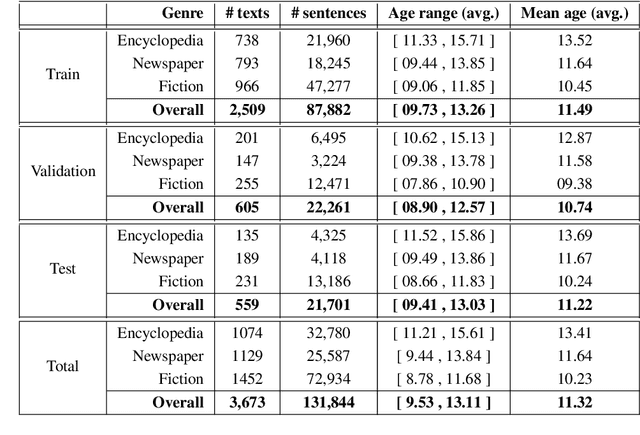
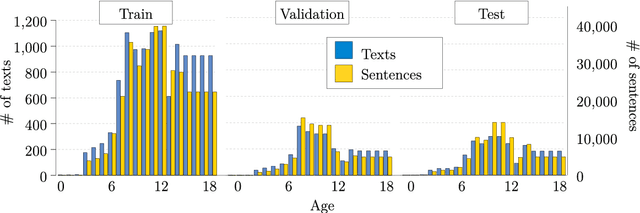

Children have less text understanding capability than adults. Moreover, this capability differs among the children of different ages. Hence, automatically predicting a recommended age based on texts or sentences would be a great benefit to propose adequate texts to children and to help authors writing in the most appropriate way. This paper presents our recent advances on the age recommendation task. We consider age recommendation as a regression task, and discuss the need for appropriate evaluation metrics, study the use of state-of-the-art machine learning model, namely Transformers, and compare it to different models coming from the literature. Our results are also compared with recommendations made by experts. Further, this paper deals with preliminary explainability of the age prediction model by analyzing various linguistic features. We conduct the experiments on a dataset of 3, 673 French texts (132K sentences, 2.5M words). To recommend age at the text level and sentence level, our best models achieve MAE scores of 0.98 and 1.83 respectively on the test set. Also, compared to the recommendations made by experts, our sentence-level recommendation model gets a similar score to the experts, while the text-level recommendation model outperforms the experts by an MAE score of 1.48.