 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute, Retrieve, Reflect, Repair: Self-Improving Agentic Framework for Visual Detection and Linguistic Reasoning in Medical Imaging
Jan 13, 2026Medical image analysis increasingly relies on large vision-language models (VLMs), yet most systems remain single-pass black boxes that offer limited control over reasoning, safety, and spatial grounding. We propose R^4, an agentic framework that decomposes medical imaging workflows into four coordinated agents: a Router that configures task- and specialization-aware prompts from the image, patient history, and metadata; a Retriever that uses exemplar memory and pass@k sampling to jointly generate free-text reports and bounding boxes; a Reflector that critiques each draft-box pair for key clinical error modes (negation, laterality, unsupported claims, contradictions, missing findings, and localization errors); and a Repairer that iteratively revises both narrative and spatial outputs under targeted constraints while curating high-quality exemplars for future cases. Instantiated on chest X-ray analysis with multiple modern VLM backbones and evaluated on report generation and weakly supervised detection, R^4 consistently boosts LLM-as-a-Judge scores by roughly +1.7-+2.5 points and mAP50 by +2.5-+3.5 absolute points over strong single-VLM baselines, without any gradient-based fine-tuning. These results show that agentic routing, reflection, and repair can turn strong but brittle VLMs into more reliable and better grounded tools for clinical image interpretation. Our code can be found at: https://github.com/faiyazabdullah/MultimodalMedAgent
Invisible Yet Detected: PelFANet with Attention-Guided Anatomical Fusion for Pelvic Fracture Diagnosis
Sep 17, 2025Pelvic fractures pose significant diagnostic challenges, particularly in cases where fracture signs are subtle or invisible on standard radiographs. To address this, we introduce PelFANet, a dual-stream attention network that fuses raw pelvic X-rays with segmented bone images to improve fracture classification. The network em-ploys Fused Attention Blocks (FABlocks) to iteratively exchange and refine fea-tures from both inputs, capturing global context and localized anatomical detail. Trained in a two-stage pipeline with a segmentation-guided approach, PelFANet demonstrates superior performance over conventional methods. On the AMERI dataset, it achieves 88.68% accuracy and 0.9334 AUC on visible fractures, while generalizing effectively to invisible fracture cases with 82.29% accuracy and 0.8688 AUC, despite not being trained on them. These results highlight the clini-cal potential of anatomy-aware dual-input architectures for robust fracture detec-tion, especially in scenarios with subtle radiographic presentations.
SceneCalib: Automatic Targetless Calibration of Cameras and Lidars in Autonomous Driving
Apr 11, 2023



Accurate camera-to-lidar calibration is a requirement for sensor data fusion in many 3D perception tasks. In this paper, we present SceneCalib, a novel method for simultaneous self-calibration of extrinsic and intrinsic parameters in a system containing multiple cameras and a lidar sensor. Existing methods typically require specially designed calibration targets and human operators, or they only attempt to solve for a subset of calibration parameters. We resolve these issues with a fully automatic method that requires no explicit correspondences between camera images and lidar point clouds, allowing for robustness to many outdoor environments. Furthermore, the full system is jointly calibrated with explicit cross-camera constraints to ensure that camera-to-camera and camera-to-lidar extrinsic parameters are consistent.
Self-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
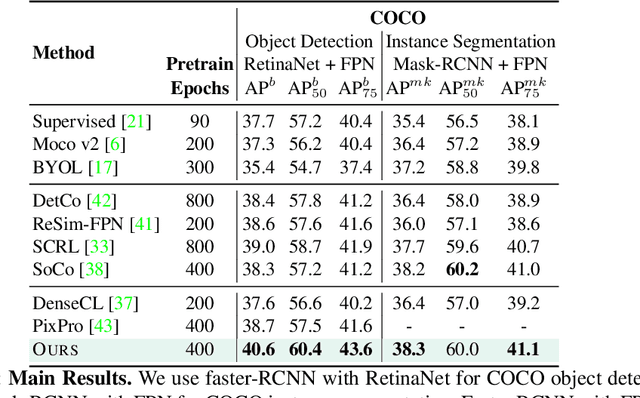
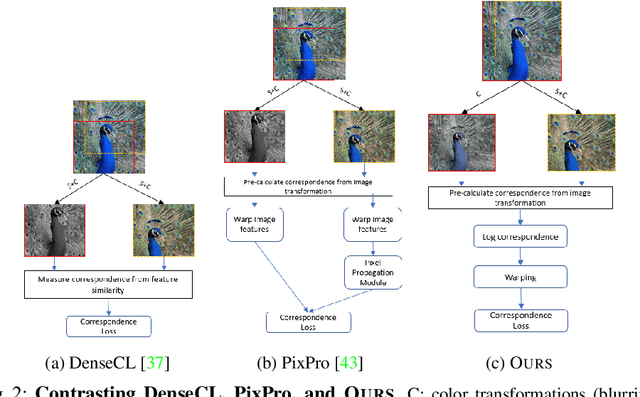
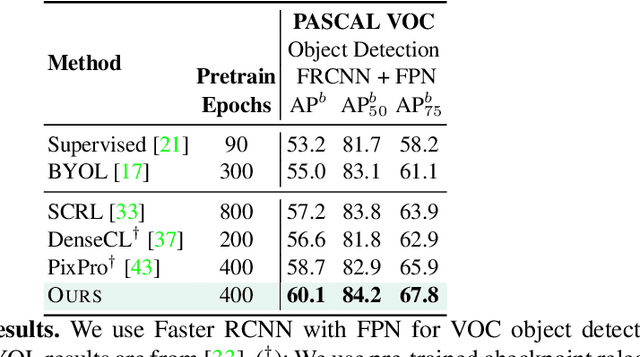
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
ConfLab: A Rich Multimodal Multisensor Dataset of Free-Standing Social Interactions In-the-Wild
May 10, 2022


We describe an instantiation of a new concept for multimodal multisensor data collection of real life in-the-wild free standing social interactions in the form of a Conference Living Lab (ConfLab). ConfLab contains high fidelity data of 49 people during a real-life professional networking event capturing a diverse mix of status, acquaintanceship, and networking motivations at an international conference. Recording such a dataset is challenging due to the delicate trade-off between participant privacy and fidelity of the data, and the technical and logistic challenges involved. We improve upon prior datasets in the fidelity of most of our modalities: 8-camera overhead setup, personal wearable sensors recording body motion (9-axis IMU), Bluetooth-based proximity, and low-frequency audio. Additionally, we use a state-of-the-art hardware synchronization solution and time-efficient continuous technique for annotating body keypoints and actions at high frequencies. We argue that our improvements are essential for a deeper study of interaction dynamics at finer time scales. Our research tasks showcase some of the open challenges related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton based no-audio speaker detection, and F-formation detection. With the ConfLab dataset, we aim to bridge the gap between traditional computer vision tasks and in-the-wild ecologically valid socially-motivated tasks.
Generating Cyber Threat Intelligence to Discover Potential Security Threats Using Classification and Topic Modeling
Aug 19, 2021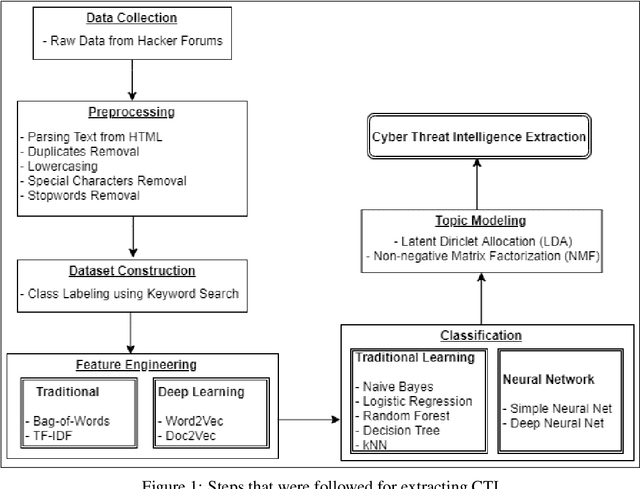

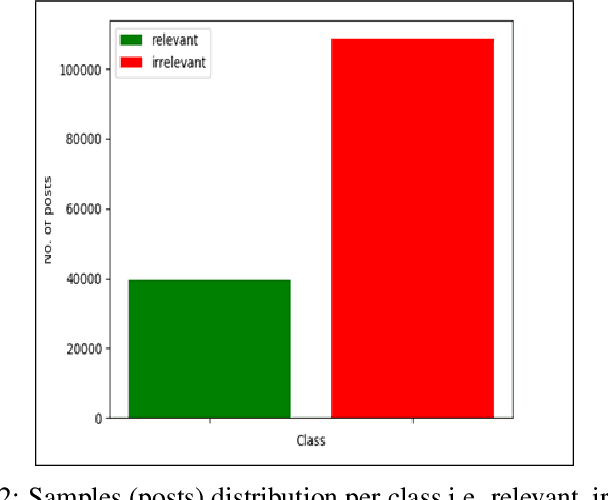

Due to the variety of cyber-attacks or threats, the cybersecurity community enhances the traditional security control mechanisms to an advanced level so that automated tools can encounter potential security threats. Very recently, Cyber Threat Intelligence (CTI) has been presented as one of the proactive and robust mechanisms because of its automated cybersecurity threat prediction. Generally, CTI collects and analyses data from various sources e.g., online security forums, social media where cyber enthusiasts, analysts, even cybercriminals discuss cyber or computer security-related topics and discovers potential threats based on the analysis. As the manual analysis of every such discussion (posts on online platforms) is time-consuming, inefficient, and susceptible to errors, CTI as an automated tool can perform uniquely to detect cyber threats. In this paper, we identify and explore relevant CTI from hacker forums utilizing different supervised (classification) and unsupervised learning (topic modeling) techniques. To this end, we collect data from a real hacker forum and constructed two datasets: a binary dataset and a multi-class dataset. We then apply several classifiers along with deep neural network-based classifiers and use them on the datasets to compare their performances. We also employ the classifiers on a labeled leaked dataset as our ground truth. We further explore the datasets using unsupervised techniques. For this purpose, we leverage two topic modeling algorithms namely Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF).
Dynamic Distillation Network for Cross-Domain Few-Shot Recognition with Unlabeled Data
Jun 14, 2021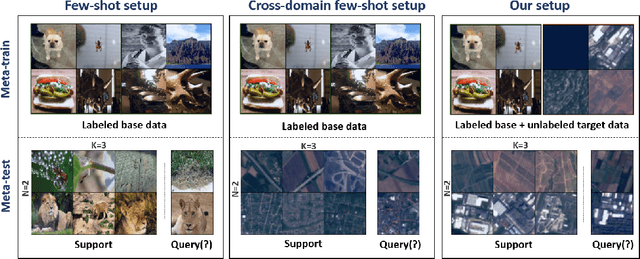
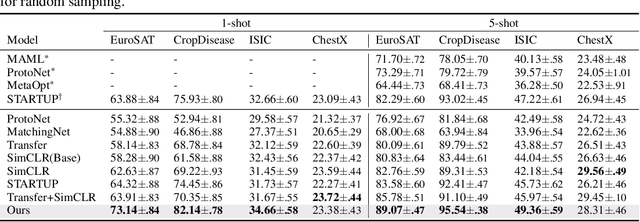


Most existing works in few-shot learning rely on meta-learning the network on a large base dataset which is typically from the same domain as the target dataset. We tackle the problem of cross-domain few-shot learning where there is a large shift between the base and target domain. The problem of cross-domain few-shot recognition with unlabeled target data is largely unaddressed in the literature. STARTUP was the first method that tackles this problem using self-training. However, it uses a fixed teacher pretrained on a labeled base dataset to create soft labels for the unlabeled target samples. As the base dataset and unlabeled dataset are from different domains, projecting the target images in the class-domain of the base dataset with a fixed pretrained model might be sub-optimal. We propose a simple dynamic distillation-based approach to facilitate unlabeled images from the novel/base dataset. We impose consistency regularization by calculating predictions from the weakly-augmented versions of the unlabeled images from a teacher network and matching it with the strongly augmented versions of the same images from a student network. The parameters of the teacher network are updated as exponential moving average of the parameters of the student network. We show that the proposed network learns representation that can be easily adapted to the target domain even though it has not been trained with target-specific classes during the pretraining phase. Our model outperforms the current state-of-the art method by 4.4% for 1-shot and 3.6% for 5-shot classification in the BSCD-FSL benchmark, and also shows competitive performance on traditional in-domain few-shot learning task. Our code will be available at: https://github.com/asrafulashiq/dynamic-cdfsl.
A Broad Study on the Transferability of Visual Representations with Contrastive Learning
Apr 01, 2021
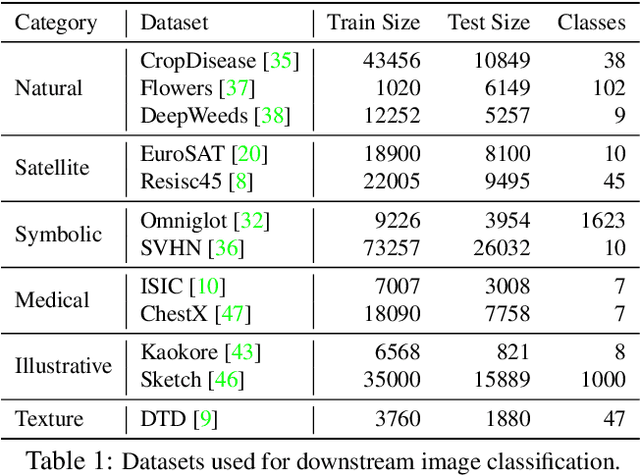

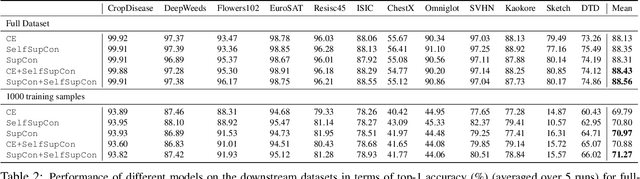
Tremendous progress has been made in visual representation learning, notably with the recent success of self-supervised contrastive learning methods. Supervised contrastive learning has also been shown to outperform its cross-entropy counterparts by leveraging labels for choosing where to contrast. However, there has been little work to explore the transfer capability of contrastive learning to a different domain. In this paper, we conduct a comprehensive study on the transferability of learned representations of different contrastive approaches for linear evaluation, full-network transfer, and few-shot recognition on 12 downstream datasets from different domains, and object detection tasks on MSCOCO and VOC0712. The results show that the contrastive approaches learn representations that are easily transferable to a different downstream task. We further observe that the joint objective of self-supervised contrastive loss with cross-entropy/supervised-contrastive loss leads to better transferability of these models over their supervised counterparts. Our analysis reveals that the representations learned from the contrastive approaches contain more low/mid-level semantics than cross-entropy models, which enables them to quickly adapt to a new task. Our codes and models will be publicly available to facilitate future research on transferability of visual representations.
A Hybrid Attention Mechanism for Weakly-Supervised Temporal Action Localization
Jan 11, 2021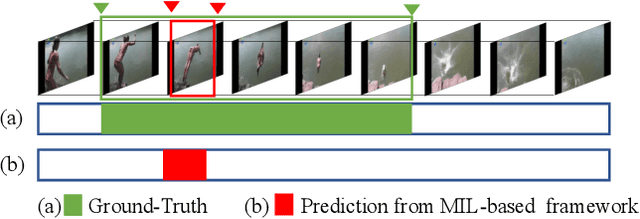

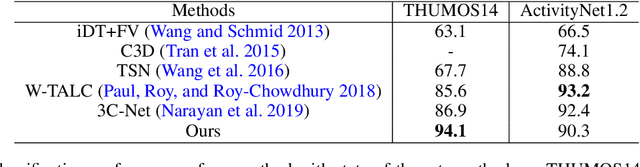

Weakly supervised temporal action localization is a challenging vision task due to the absence of ground-truth temporal locations of actions in the training videos. With only video-level supervision during training, most existing methods rely on a Multiple Instance Learning (MIL) framework to predict the start and end frame of each action category in a video. However, the existing MIL-based approach has a major limitation of only capturing the most discriminative frames of an action, ignoring the full extent of an activity. Moreover, these methods cannot model background activity effectively, which plays an important role in localizing foreground activities. In this paper, we present a novel framework named HAM-Net with a hybrid attention mechanism which includes temporal soft, semi-soft and hard attentions to address these issues. Our temporal soft attention module, guided by an auxiliary background class in the classification module, models the background activity by introducing an "action-ness" score for each video snippet. Moreover, our temporal semi-soft and hard attention modules, calculating two attention scores for each video snippet, help to focus on the less discriminative frames of an action to capture the full action boundary. Our proposed approach outperforms recent state-of-the-art methods by at least 2.2% mAP at IoU threshold 0.5 on the THUMOS14 dataset, and by at least 1.3% mAP at IoU threshold 0.75 on the ActivityNet1.2 dataset. Code can be found at: https://github.com/asrafulashiq/hamnet.
Weakly Supervised Temporal Action Localization Using Deep Metric Learning
Jan 21, 2020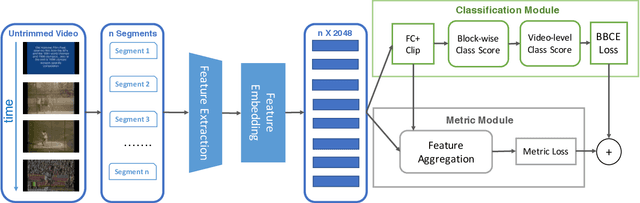
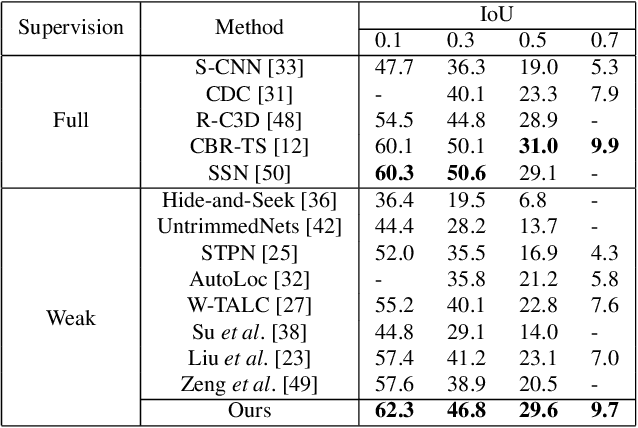

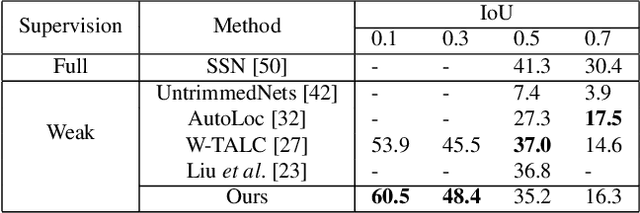
Temporal action localization is an important step towards video understanding. Most current action localization methods depend on untrimmed videos with full temporal annotations of action instances. However, it is expensive and time-consuming to annotate both action labels and temporal boundaries of videos. To this end, we propose a weakly supervised temporal action localization method that only requires video-level action instances as supervision during training. We propose a classification module to generate action labels for each segment in the video, and a deep metric learning module to learn the similarity between different action instances. We jointly optimize a balanced binary cross-entropy loss and a metric loss using a standard backpropagation algorithm. Extensive experiments demonstrate the effectiveness of both of these components in temporal localization. We evaluate our algorithm on two challenging untrimmed video datasets: THUMOS14 and ActivityNet1.2. Our approach improves the current state-of-the-art result for THUMOS14 by 6.5% mAP at IoU threshold 0.5, and achieves competitive performance for ActivityNet1.2.