 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCalib: Automatic Targetless Calibration of Cameras and Lidars in Autonomous Driving
Apr 11, 2023



Accurate camera-to-lidar calibration is a requirement for sensor data fusion in many 3D perception tasks. In this paper, we present SceneCalib, a novel method for simultaneous self-calibration of extrinsic and intrinsic parameters in a system containing multiple cameras and a lidar sensor. Existing methods typically require specially designed calibration targets and human operators, or they only attempt to solve for a subset of calibration parameters. We resolve these issues with a fully automatic method that requires no explicit correspondences between camera images and lidar point clouds, allowing for robustness to many outdoor environments. Furthermore, the full system is jointly calibrated with explicit cross-camera constraints to ensure that camera-to-camera and camera-to-lidar extrinsic parameters are consistent.
EVIMO2: An Event Camera Dataset for Motion Segmentation, Optical Flow, Structure from Motion, and Visual Inertial Odometry in Indoor Scenes with Monocular or Stereo Algorithms
May 06, 2022
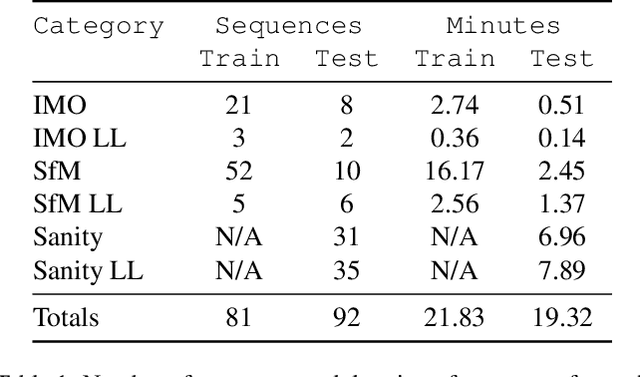


A new event camera dataset, EVIMO2, is introduced that improves on the popular EVIMO dataset by providing more data, from better cameras, in more complex scenarios. As with its predecessor, EVIMO2 provides labels in the form of per-pixel ground truth depth and segmentation as well as camera and object poses. All sequences use data from physical cameras and many sequences feature multiple independently moving objects. Typically, such labeled data is unavailable in physical event camera datasets. Thus, EVIMO2 will serve as a challenging benchmark for existing algorithms and rich training set for the development of new algorithms. In particular, EVIMO2 is suited for supporting research in motion and object segmentation, optical flow, structure from motion, and visual (inertial) odometry in both monocular or stereo configurations. EVIMO2 consists of 41 minutes of data from three 640$\times$480 event cameras, one 2080$\times$1552 classical color camera, inertial measurements from two six axis inertial measurement units, and millimeter accurate object poses from a Vicon motion capture system. The dataset's 173 sequences are arranged into three categories. 3.75 minutes of independently moving household objects, 22.55 minutes of static scenes, and 14.85 minutes of basic motions in shallow scenes. Some sequences were recorded in low-light conditions where conventional cameras fail. Depth and segmentation are provided at 60 Hz for the event cameras and 30 Hz for the classical camera. The masks can be regenerated using open-source code up to rates as high as 200 Hz. This technical report briefly describes EVIMO2. The full documentation is available online. Videos of individual sequences can be sampled on the download page.
Network Deconvolution
May 28, 2019
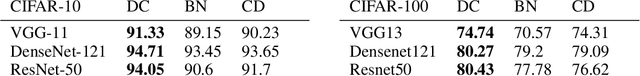
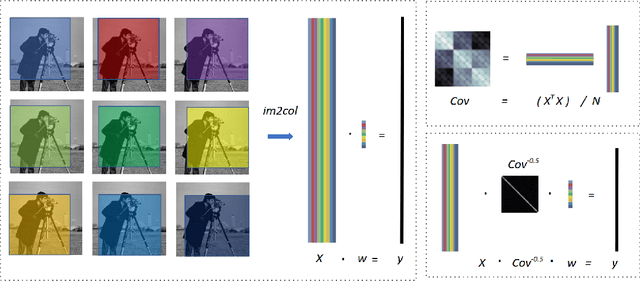

Convolution is a central operation in Convolutional Neural Networks (CNNs), which applies a kernel or mask to overlapping regions shifted across the image. In this work we show that the underlying kernels are trained with highly correlated data, which leads to co-adaptation of model weights. To address this issue we propose what we call network deconvolution, a procedure that aims to remove pixel-wise and channel-wise correlations before the data is fed into each layer. We show that by removing this correlation we are able to achieve better convergence rates during model training with superior results without the use of batch normalization on the CIFAR-10, CIFAR-100, MNIST, Fashion-MNIST datasets, as well as against reference models from "model zoo" on the ImageNet standard benchmark.
EV-IMO: Motion Segmentation Dataset and Learning Pipeline for Event Cameras
Mar 18, 2019
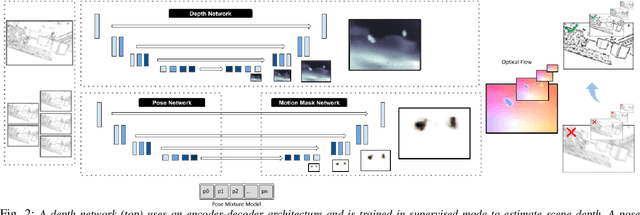
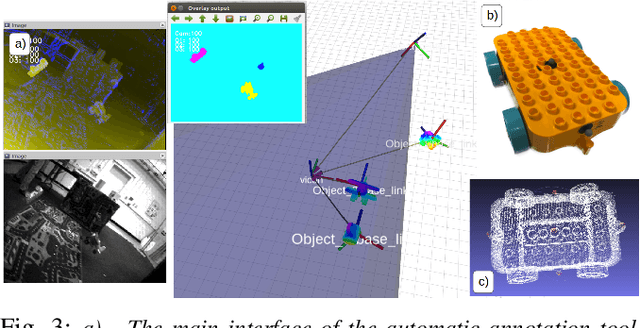

We present the first event-based learning approach for motion segmentation in indoor scenes and the first event-based dataset - EV-IMO - which includes accurate pixel-wise motion masks, egomotion and ground truth depth. Our approach is based on an efficient implementation of the SfM learning pipeline using a low parameter neural network architecture on event data. In addition to camera egomotion and a dense depth map, the network estimates pixel-wise independently moving object segmentation and computes per-object 3D translational velocities for moving objects. We also train a shallow network with just 40k parameters, which is able to compute depth and egomotion. Our EV-IMO dataset features 32 minutes of indoor recording with up to 3 fast moving objects simultaneously in the camera field of view. The objects and the camera are tracked by the VICON motion capture system. By 3D scanning the room and the objects, accurate depth map ground truth and pixel-wise object masks are obtained, which are reliable even in poor lighting conditions and during fast motion. We then train and evaluate our learning pipeline on EV-IMO and demonstrate that our approach far surpasses its rivals and is well suited for scene constrained robotics applications.
Unsupervised Learning of Dense Optical Flow, Depth and Egomotion from Sparse Event Data
Feb 25, 2019


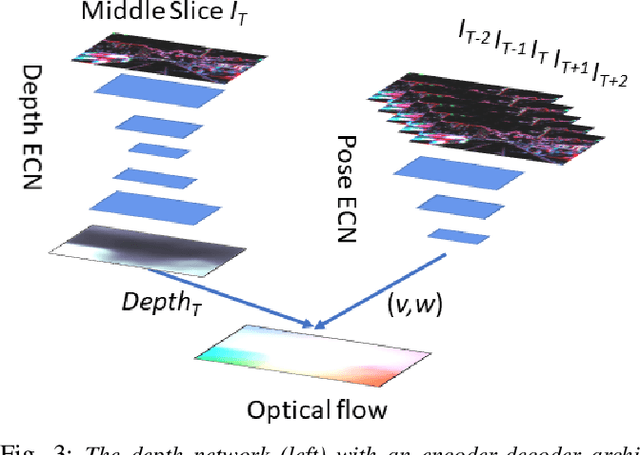
In this work we present a lightweight, unsupervised learning pipeline for \textit{dense} depth, optical flow and egomotion estimation from sparse event output of the Dynamic Vision Sensor (DVS). To tackle this low level vision task, we use a novel encoder-decoder neural network architecture - ECN. Our work is the first monocular pipeline that generates dense depth and optical flow from sparse event data only. The network works in self-supervised mode and has just 150k parameters. We evaluate our pipeline on the MVSEC self driving dataset and present results for depth, optical flow and and egomotion estimation. Due to the lightweight design, the inference part of the network runs at 250 FPS on a single GPU, making the pipeline ready for realtime robotics applications. Our experiments demonstrate significant improvements upon previous works that used deep learning on event data, as well as the ability of our pipeline to perform well during both day and night.
Event-based Moving Object Detection and Tracking
Jul 23, 2018
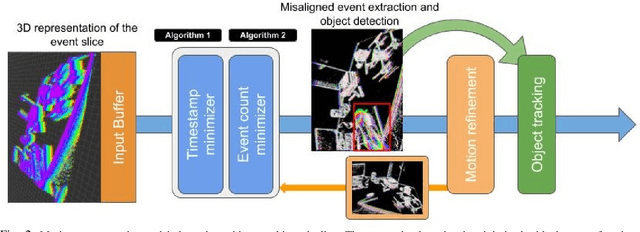


Event-based vision sensors, such as the Dynamic Vision Sensor (DVS), are ideally suited for real-time motion analysis. The unique properties encompassed in the readings of such sensors provide high temporal resolution, superior sensitivity to light and low latency. These properties provide the grounds to estimate motion extremely reliably in the most sophisticated scenarios but they come at a price - modern event-based vision sensors have extremely low resolution and produce a lot of noise. Moreover, the asynchronous nature of the event stream calls for novel algorithms. This paper presents a new, efficient approach to object tracking with asynchronous cameras. We present a novel event stream representation which enables us to utilize information about the dynamic (temporal) component of the event stream, and not only the spatial component, at every moment of time. This is done by approximating the 3D geometry of the event stream with a parametric model; as a result, the algorithm is capable of producing the motion-compensated event stream (effectively approximating egomotion), and without using any form of external sensors in extremely low-light and noisy conditions without any form of feature tracking or explicit optical flow computation. We demonstrate our framework on the task of independent motion detection and tracking, where we use the temporal model inconsistencies to locate differently moving objects in challenging situations of very fast motion.