 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-speed Imaging through Turbulence with Event-based Light Fields
Mar 14, 2026This work introduces and demonstrates the first system capable of imaging fast-moving extended non-rigid objects through strong atmospheric turbulence at high frame rate. Event cameras are a novel sensing architecture capable of estimating high-speed imagery at thousands of frames per second. However, on their own event cameras are unable to disambiguate scene motion from turbulence. In this work, we overcome this limitation using event-based light field cameras: By simultaneously capturing multiple views of a scene, event-based light field cameras and machine learning-based reconstruction algorithms are able to disambiguate motion-induced dynamics, which produce events that are strongly correlated across views, from turbulence-induced dynamics, which produce events that are weakly correlated across view. Tabletop experiments demonstrate event-based light field can overcome strong turbulence while imaging high-speed objects traveling at up to 16,000 pixels per second.
Learning Normal Flow Directly From Event Neighborhoods
Dec 15, 2024



Event-based motion field estimation is an important task. However, current optical flow methods face challenges: learning-based approaches, often frame-based and relying on CNNs, lack cross-domain transferability, while model-based methods, though more robust, are less accurate. To address the limitations of optical flow estimation, recent works have focused on normal flow, which can be more reliably measured in regions with limited texture or strong edges. However, existing normal flow estimators are predominantly model-based and suffer from high errors. In this paper, we propose a novel supervised point-based method for normal flow estimation that overcomes the limitations of existing event learning-based approaches. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, offering multiple unique advantages: 1) It produces temporally and spatially sharp predictions. 2) It supports more diverse data augmentation, such as random rotation, to improve robustness across various domains. 3) It naturally supports uncertainty quantification via ensemble inference, which benefits downstream tasks. 4) It enables training and inference on undistorted data in normalized camera coordinates, improving transferability across cameras. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets. Leveraging this transferability, we train our model on the union of datasets and release it for public use. Finally, we introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Dec 10, 2024



Video Frame Interpolation aims to recover realistic missing frames between observed frames, generating a high-frame-rate video from a low-frame-rate video. However, without additional guidance, the large motion between frames makes this problem ill-posed. Event-based Video Frame Interpolation (EVFI) addresses this challenge by using sparse, high-temporal-resolution event measurements as motion guidance. This guidance allows EVFI methods to significantly outperform frame-only methods. However, to date, EVFI methods have relied on a limited set of paired event-frame training data, severely limiting their performance and generalization capabilities. In this work, we overcome the limited data challenge by adapting pre-trained video diffusion models trained on internet-scale datasets to EVFI. We experimentally validate our approach on real-world EVFI datasets, including a new one that we introduce. Our method outperforms existing methods and generalizes across cameras far better than existing approaches.
Extremum Seeking Controlled Wiggling for Tactile Insertion
Oct 03, 2024
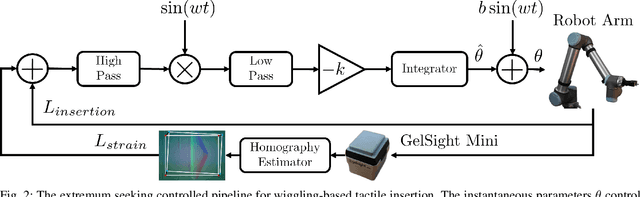


When humans perform insertion tasks such as inserting a cup into a cupboard, routing a cable, or key insertion, they wiggle the object and observe the process through tactile and proprioceptive feedback. While recent advances in tactile sensors have resulted in tactile-based approaches, there has not been a generalized formulation based on wiggling similar to human behavior. Thus, we propose an extremum-seeking control law that can insert four keys into four types of locks without control parameter tuning despite significant variation in lock type. The resulting model-free formulation wiggles the end effector pose to maximize insertion depth while minimizing strain as measured by a GelSight Mini tactile sensor that grasps a key. The algorithm achieves a 71\% success rate over 120 randomly initialized trials with uncertainty in both translation and orientation. Over 240 deterministically initialized trials, where only one translation or rotation parameter is perturbed, 84\% of trials succeeded. Given tactile feedback at 13 Hz, the mean insertion time for these groups of trials are 262 and 147 seconds respectively.
EVIMO2: An Event Camera Dataset for Motion Segmentation, Optical Flow, Structure from Motion, and Visual Inertial Odometry in Indoor Scenes with Monocular or Stereo Algorithms
May 06, 2022
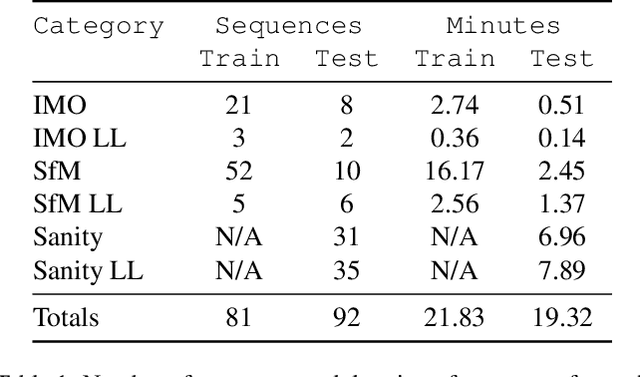


A new event camera dataset, EVIMO2, is introduced that improves on the popular EVIMO dataset by providing more data, from better cameras, in more complex scenarios. As with its predecessor, EVIMO2 provides labels in the form of per-pixel ground truth depth and segmentation as well as camera and object poses. All sequences use data from physical cameras and many sequences feature multiple independently moving objects. Typically, such labeled data is unavailable in physical event camera datasets. Thus, EVIMO2 will serve as a challenging benchmark for existing algorithms and rich training set for the development of new algorithms. In particular, EVIMO2 is suited for supporting research in motion and object segmentation, optical flow, structure from motion, and visual (inertial) odometry in both monocular or stereo configurations. EVIMO2 consists of 41 minutes of data from three 640$\times$480 event cameras, one 2080$\times$1552 classical color camera, inertial measurements from two six axis inertial measurement units, and millimeter accurate object poses from a Vicon motion capture system. The dataset's 173 sequences are arranged into three categories. 3.75 minutes of independently moving household objects, 22.55 minutes of static scenes, and 14.85 minutes of basic motions in shallow scenes. Some sequences were recorded in low-light conditions where conventional cameras fail. Depth and segmentation are provided at 60 Hz for the event cameras and 30 Hz for the classical camera. The masks can be regenerated using open-source code up to rates as high as 200 Hz. This technical report briefly describes EVIMO2. The full documentation is available online. Videos of individual sequences can be sampled on the download page.
Fast Active Monocular Distance Estimation from Time-to-Contact
Mar 14, 2022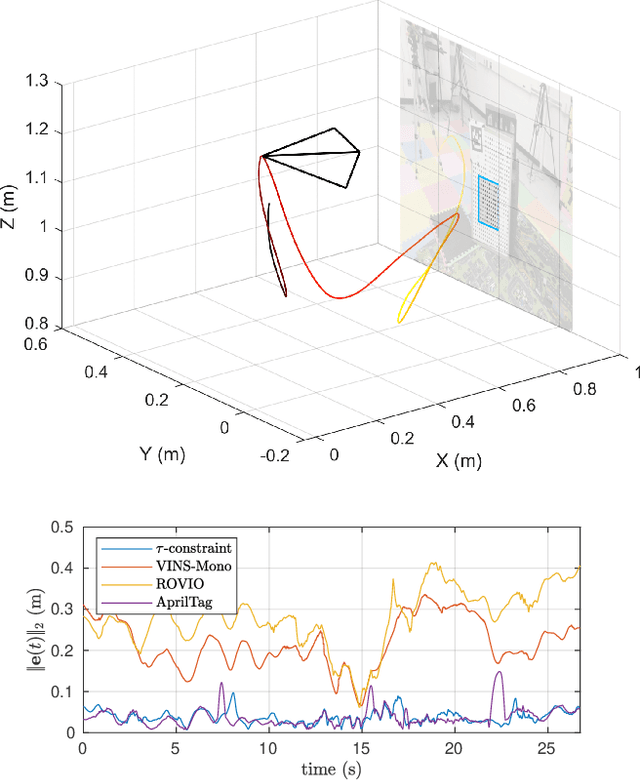
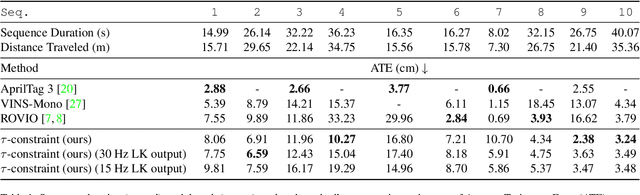
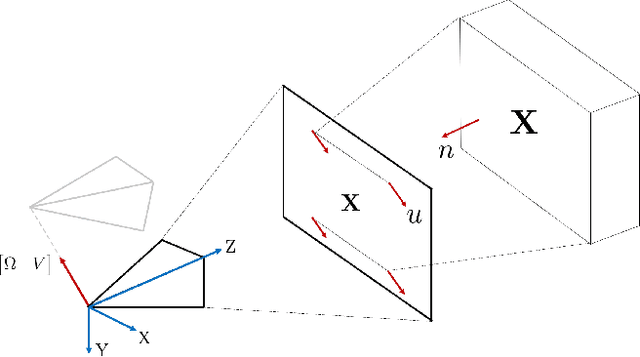
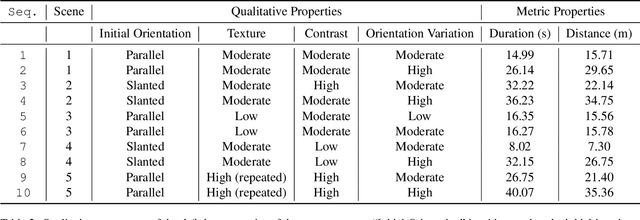
Distance estimation is fundamental for a variety of robotic applications including navigation, manipulation and planning. Inspired by the mammal's visual system, which gazes at specific objects (active fixation), and estimates when the object will reach it (time-to-contact), we develop a novel constraint between time-to-contact, acceleration, and distance that we call the $\tau$-constraint. It allows an active monocular camera to estimate depth using time-to-contact and inertial measurements (linear accelerations and angular velocities) within a window of time. Our work differs from other approaches by focusing on patches instead of feature points. This is, because the change in the patch area determines the time-to-contact directly. The result enables efficient estimation of distance while using only a small portion of the image, leading to a large speedup. We successfully validate the proposed $\tau$-constraint in the application of estimating camera position with a monocular grayscale camera and an Inertial Measurement Unit (IMU). Specifically, we test our method on different real-world planar objects over trajectories 8-40 seconds in duration and 7-35 meters long. Our method achieves 8.5 cm Average Trajectory Error (ATE) while the popular Visual-Inertial Odometry methods VINS-Mono and ROVIO achieve 12.2 and 16.9 cm ATE respectively. Additionally, our implementation runs 27$\times$ faster than VINS-Mono's and 6.8$\times$ faster than ROVIO's. We believe these results indicate the $\tau$-constraints potential to be the basis of robust, sophisticated algorithms for a multitude of applications involving an active camera and an IMU.