 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
Learning Normal Flow Directly From Event Neighborhoods
Dec 15, 2024



Event-based motion field estimation is an important task. However, current optical flow methods face challenges: learning-based approaches, often frame-based and relying on CNNs, lack cross-domain transferability, while model-based methods, though more robust, are less accurate. To address the limitations of optical flow estimation, recent works have focused on normal flow, which can be more reliably measured in regions with limited texture or strong edges. However, existing normal flow estimators are predominantly model-based and suffer from high errors. In this paper, we propose a novel supervised point-based method for normal flow estimation that overcomes the limitations of existing event learning-based approaches. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, offering multiple unique advantages: 1) It produces temporally and spatially sharp predictions. 2) It supports more diverse data augmentation, such as random rotation, to improve robustness across various domains. 3) It naturally supports uncertainty quantification via ensemble inference, which benefits downstream tasks. 4) It enables training and inference on undistorted data in normalized camera coordinates, improving transferability across cameras. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets. Leveraging this transferability, we train our model on the union of datasets and release it for public use. Finally, we introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Dec 10, 2024



Video Frame Interpolation aims to recover realistic missing frames between observed frames, generating a high-frame-rate video from a low-frame-rate video. However, without additional guidance, the large motion between frames makes this problem ill-posed. Event-based Video Frame Interpolation (EVFI) addresses this challenge by using sparse, high-temporal-resolution event measurements as motion guidance. This guidance allows EVFI methods to significantly outperform frame-only methods. However, to date, EVFI methods have relied on a limited set of paired event-frame training data, severely limiting their performance and generalization capabilities. In this work, we overcome the limited data challenge by adapting pre-trained video diffusion models trained on internet-scale datasets to EVFI. We experimentally validate our approach on real-world EVFI datasets, including a new one that we introduce. Our method outperforms existing methods and generalizes across cameras far better than existing approaches.
Active Human Pose Estimation via an Autonomous UAV Agent
Jul 01, 2024



One of the core activities of an active observer involves moving to secure a "better" view of the scene, where the definition of "better" is task-dependent. This paper focuses on the task of human pose estimation from videos capturing a person's activity. Self-occlusions within the scene can complicate or even prevent accurate human pose estimation. To address this, relocating the camera to a new vantage point is necessary to clarify the view, thereby improving 2D human pose estimation. This paper formalizes the process of achieving an improved viewpoint. Our proposed solution to this challenge comprises three main components: a NeRF-based Drone-View Data Generation Framework, an On-Drone Network for Camera View Error Estimation, and a Combined Planner for devising a feasible motion plan to reposition the camera based on the predicted errors for camera views. The Data Generation Framework utilizes NeRF-based methods to generate a comprehensive dataset of human poses and activities, enhancing the drone's adaptability in various scenarios. The Camera View Error Estimation Network is designed to evaluate the current human pose and identify the most promising next viewing angles for the drone, ensuring a reliable and precise pose estimation from those angles. Finally, the combined planner incorporates these angles while considering the drone's physical and environmental limitations, employing efficient algorithms to navigate safe and effective flight paths. This system represents a significant advancement in active 2D human pose estimation for an autonomous UAV agent, offering substantial potential for applications in aerial cinematography by improving the performance of autonomous human pose estimation and maintaining the operational safety and efficiency of UAVs.
CodedEvents: Optimal Point-Spread-Function Engineering for 3D-Tracking with Event Cameras
Jun 13, 2024
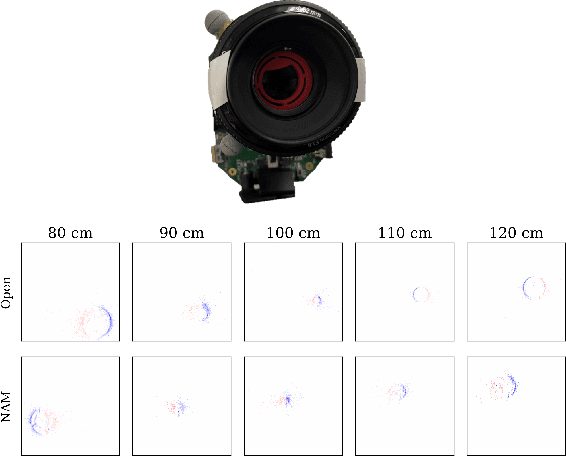

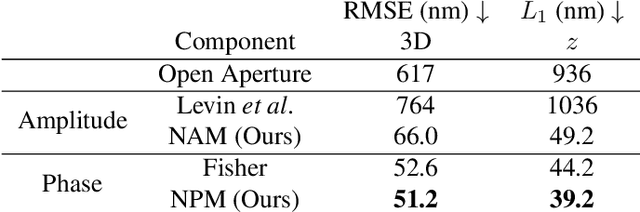
Point-spread-function (PSF) engineering is a well-established computational imaging technique that uses phase masks and other optical elements to embed extra information (e.g., depth) into the images captured by conventional CMOS image sensors. To date, however, PSF-engineering has not been applied to neuromorphic event cameras; a powerful new image sensing technology that responds to changes in the log-intensity of light. This paper establishes theoretical limits (Cram\'er Rao bounds) on 3D point localization and tracking with PSF-engineered event cameras. Using these bounds, we first demonstrate that existing Fisher phase masks are already near-optimal for localizing static flashing point sources (e.g., blinking fluorescent molecules). We then demonstrate that existing designs are sub-optimal for tracking moving point sources and proceed to use our theory to design optimal phase masks and binary amplitude masks for this task. To overcome the non-convexity of the design problem, we leverage novel implicit neural representation based parameterizations of the phase and amplitude masks. We demonstrate the efficacy of our designs through extensive simulations. We also validate our method with a simple prototype.
Microsaccade-inspired Event Camera for Robotics
May 28, 2024Neuromorphic vision sensors or event cameras have made the visual perception of extremely low reaction time possible, opening new avenues for high-dynamic robotics applications. These event cameras' output is dependent on both motion and texture. However, the event camera fails to capture object edges that are parallel to the camera motion. This is a problem intrinsic to the sensor and therefore challenging to solve algorithmically. Human vision deals with perceptual fading using the active mechanism of small involuntary eye movements, the most prominent ones called microsaccades. By moving the eyes constantly and slightly during fixation, microsaccades can substantially maintain texture stability and persistence. Inspired by microsaccades, we designed an event-based perception system capable of simultaneously maintaining low reaction time and stable texture. In this design, a rotating wedge prism was mounted in front of the aperture of an event camera to redirect light and trigger events. The geometrical optics of the rotating wedge prism allows for algorithmic compensation of the additional rotational motion, resulting in a stable texture appearance and high informational output independent of external motion. The hardware device and software solution are integrated into a system, which we call Artificial MIcrosaccade-enhanced EVent camera (AMI-EV). Benchmark comparisons validate the superior data quality of AMI-EV recordings in scenarios where both standard cameras and event cameras fail to deliver. Various real-world experiments demonstrate the potential of the system to facilitate robotics perception both for low-level and high-level vision tasks.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024



This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
ConVRT: Consistent Video Restoration Through Turbulence with Test-time Optimization of Neural Video Representations
Dec 07, 2023



tmospheric turbulence presents a significant challenge in long-range imaging. Current restoration algorithms often struggle with temporal inconsistency, as well as limited generalization ability across varying turbulence levels and scene content different than the training data. To tackle these issues, we introduce a self-supervised method, Consistent Video Restoration through Turbulence (ConVRT) a test-time optimization method featuring a neural video representation designed to enhance temporal consistency in restoration. A key innovation of ConVRT is the integration of a pretrained vision-language model (CLIP) for semantic-oriented supervision, which steers the restoration towards sharp, photorealistic images in the CLIP latent space. We further develop a principled selection strategy of text prompts, based on their statistical correlation with a perceptual metric. ConVRT's test-time optimization allows it to adapt to a wide range of real-world turbulence conditions, effectively leveraging the insights gained from pre-trained models on simulated data. ConVRT offers a comprehensive and effective solution for mitigating real-world turbulence in dynamic videos.
ProxMaP: Proximal Occupancy Map Prediction for Efficient Indoor Robot Navigation
May 10, 2023In a typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited due to occlusions. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly predict what its surroundings and occluded regions look like, the robot may be more efficient in navigation. In this work, we focus on predicting occupancy within the reachable distance of the robot to enable faster navigation and present a self-supervised proximity occupancy map prediction method, named ProxMaP. We show that ProxMaP generalizes well across realistic and real domains, and improves the robot navigation efficiency in simulation by \textbf{$12.40\%$} against the traditional navigation method. We share our findings on our project webpage (see https://raaslab.org/projects/ProxMaP ).
Occupancy Map Prediction for Improved Indoor Robot Navigation
Mar 08, 2022

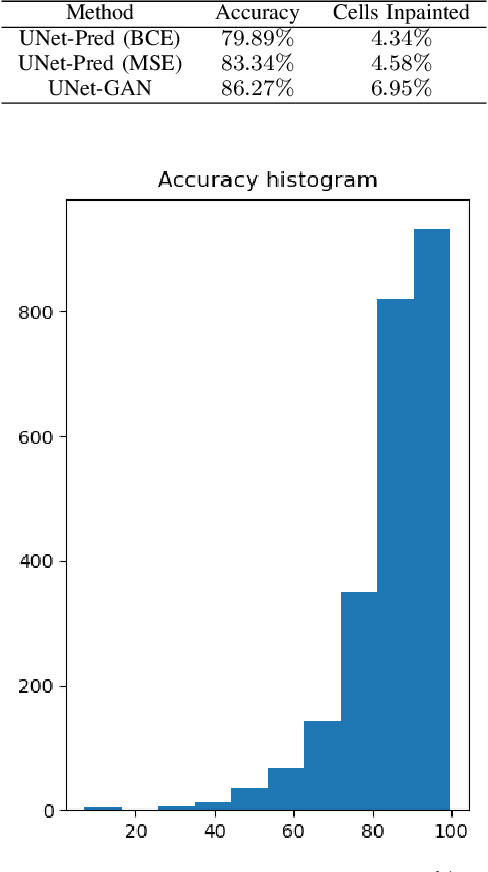
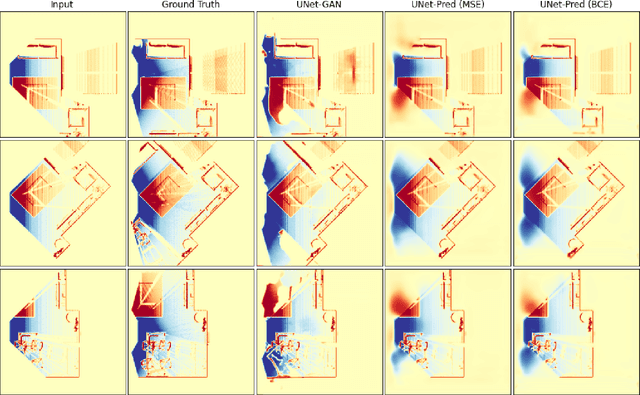
In the typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited by the occlusions in its surroundings. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly infer what its surroundings and occluded regions look like, the navigation can be further optimized. In this work, we propose an approach using pix2pix and UNet to infer the occupancy grid in unseen areas near the robot as an image-to-image translation task. Our approach simplifies the task of occupancy map prediction for the deep learning network and reduces the amount of data required compared to similar existing methods. We show that the predicted map improves the navigation time in simulations over the existing approaches.