 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-based Adversarial Imitation Learning Framework for Reliable & Realtime Fleet Scheduling in Urban Air Mobility
Jul 16, 2024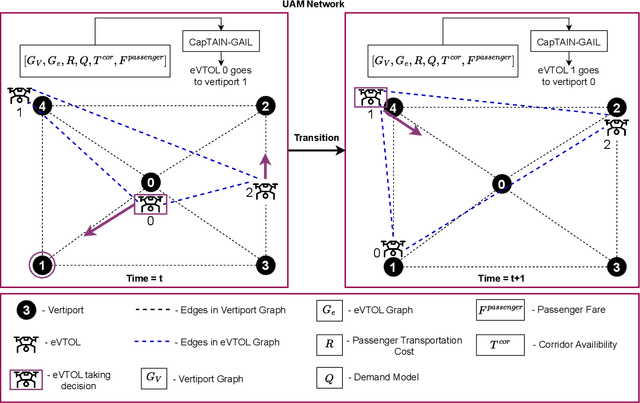
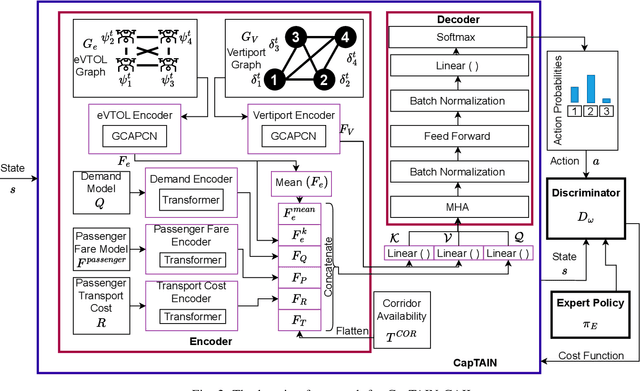
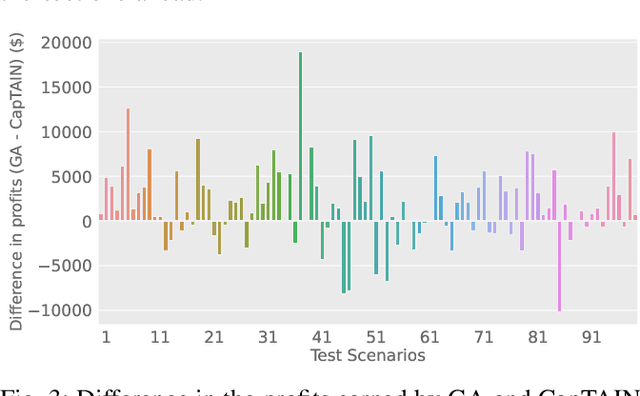
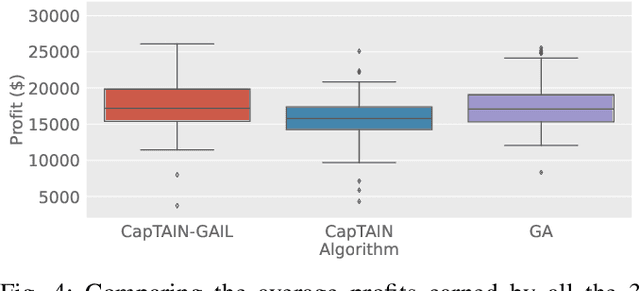
The advent of Urban Air Mobility (UAM) presents the scope for a transformative shift in the domain of urban transportation. However, its widespread adoption and economic viability depends in part on the ability to optimally schedule the fleet of aircraft across vertiports in a UAM network, under uncertainties attributed to airspace congestion, changing weather conditions, and varying demands. This paper presents a comprehensive optimization formulation of the fleet scheduling problem, while also identifying the need for alternate solution approaches, since directly solving the resulting integer nonlinear programming problem is computationally prohibitive for daily fleet scheduling. Previous work has shown the effectiveness of using (graph) reinforcement learning (RL) approaches to train real-time executable policy models for fleet scheduling. However, such policies can often be brittle on out-of-distribution scenarios or edge cases. Moreover, training performance also deteriorates as the complexity (e.g., number of constraints) of the problem increases. To address these issues, this paper presents an imitation learning approach where the RL-based policy exploits expert demonstrations yielded by solving the exact optimization using a Genetic Algorithm. The policy model comprises Graph Neural Network (GNN) based encoders that embed the space of vertiports and aircraft, Transformer networks to encode demand, passenger fare, and transport cost profiles, and a Multi-head attention (MHA) based decoder. Expert demonstrations are used through the Generative Adversarial Imitation Learning (GAIL) algorithm. Interfaced with a UAM simulation environment involving 8 vertiports and 40 aircrafts, in terms of the daily profits earned reward, the new imitative approach achieves better mean performance and remarkable improvement in the case of unseen worst-case scenarios, compared to pure RL results.
RE-MOVE: An Adaptive Policy Design Approach for Dynamic Environments via Language-Based Feedback
Mar 14, 2023Reinforcement learning-based policies for continuous control robotic navigation tasks often fail to adapt to changes in the environment during real-time deployment, which may result in catastrophic failures. To address this limitation, we propose a novel approach called RE-MOVE (\textbf{RE}quest help and \textbf{MOVE} on), which uses language-based feedback to adjust trained policies to real-time changes in the environment. In this work, we enable the trained policy to decide \emph{when to ask for feedback} and \emph{how to incorporate feedback into trained policies}. RE-MOVE incorporates epistemic uncertainty to determine the optimal time to request feedback from humans and uses language-based feedback for real-time adaptation. We perform extensive synthetic and real-world evaluations to demonstrate the benefits of our proposed approach in several test-time dynamic navigation scenarios. Our approach enable robots to learn from human feedback and adapt to previously unseen adversarial situations.
A Model-free Deep Reinforcement Learning Approach To Maneuver A Quadrotor Despite Single Rotor Failure
Sep 22, 2021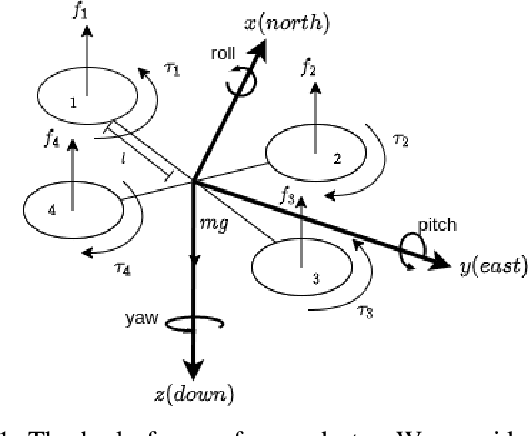
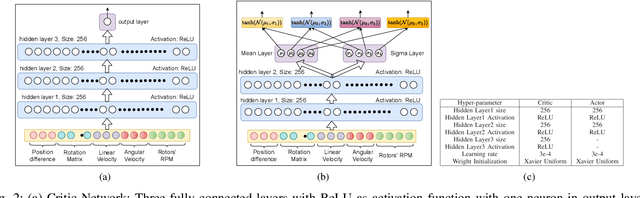
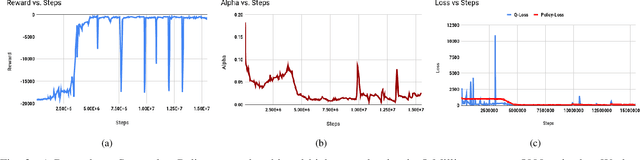
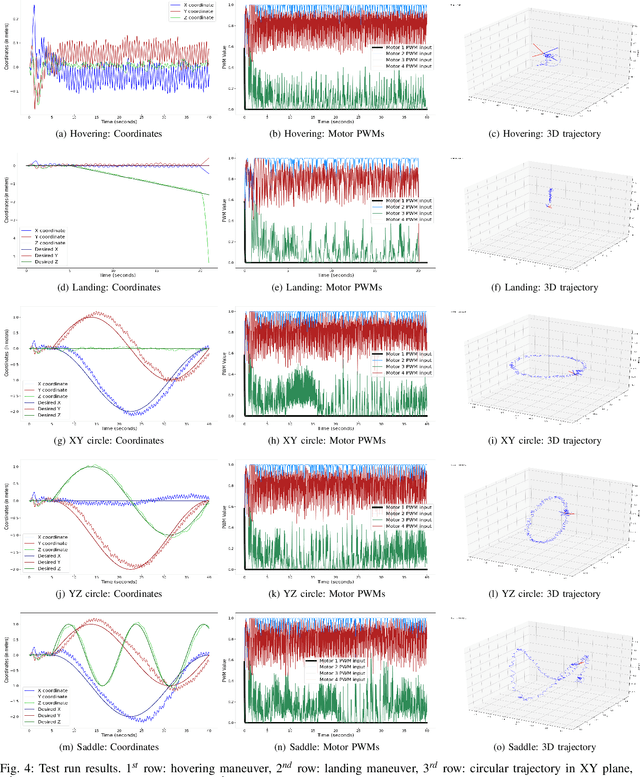
Ability to recover from faults and continue mission is desirable for many quadrotor applications. The quadrotor's rotor may fail while performing a mission and it is essential to develop recovery strategies so that the vehicle is not damaged. In this paper, we develop a model-free deep reinforcement learning approach for a quadrotor to recover from a single rotor failure. The approach is based on Soft-actor-critic that enables the vehicle to hover, land, and perform complex maneuvers. Simulation results are presented to validate the proposed approach using a custom simulator. The results show that the proposed approach achieves hover, landing, and path following in 2D and 3D. We also show that the proposed approach is robust to wind disturbances.
GALOPP: Multi-Agent Deep Reinforcement Learning For Persistent Monitoring With Localization Constraints
Sep 22, 2021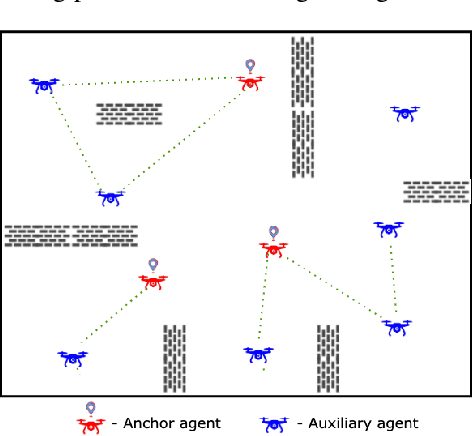
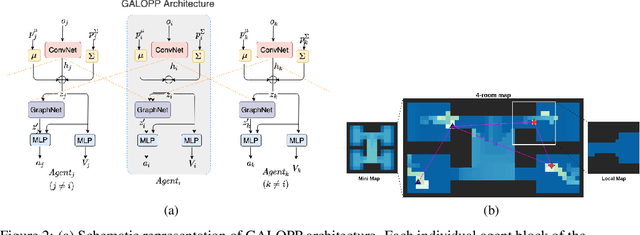
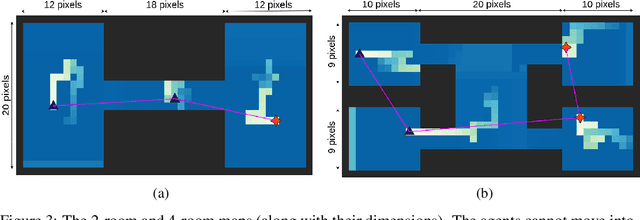
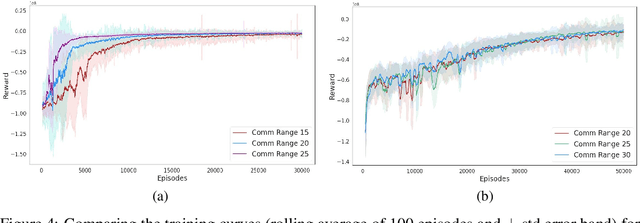
Persistently monitoring a region under localization and communication constraints is a challenging problem. In this paper, we consider a heterogenous robotic system consisting of two types of agents -- anchor agents that have accurate localization capability, and auxiliary agents that have low localization accuracy. The auxiliary agents must be within the communication range of an {anchor}, directly or indirectly to localize itself. The objective of the robotic team is to minimize the uncertainty in the environment through persistent monitoring. We propose a multi-agent deep reinforcement learning (MADRL) based architecture with graph attention called Graph Localized Proximal Policy Optimization (GALLOP), which incorporates the localization and communication constraints of the agents along with persistent monitoring objective to determine motion policies for each agent. We evaluate the performance of GALLOP on three different custom-built environments. The results show the agents are able to learn a stable policy and outperform greedy and random search baseline approaches.