 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlood Risk Follows Valleys, Not Grids: Graph Neural Networks for Flash Flood Susceptibility Mapping in Himachal Pradesh with Conformal Uncertainty Quantification
Mar 15, 2026Flash floods are the most destructive natural hazard in Himachal Pradesh (HP), India, causing over 400 fatalities and $1.2 billion in losses in the 2023 monsoon season alone. Existing risk maps treat every pixel independently, ignoring the basic fact that flooding upstream raises risk downstream. We address this with a Graph Neural Network (GraphSAGE) trained on a watershed connectivity graph (460 sub-watersheds, 1,700 directed edges), built from a six-year Sentinel-1 SAR flood inventory (2018-2023, 3,000 events) and 12 environmental variables at 30 m resolution. Four pixel-based ML models (RF, XGBoost, LightGBM, stacking ensemble) serve as baselines. All models are evaluated with leave-one-basin-out spatial cross-validation to avoid the 5-15% AUC inflation of random splits. Conformal prediction produces the first HP susceptibility maps with statistically guaranteed 90% coverage intervals. The GNN achieved AUC = 0.978 +/- 0.017, outperforming the best baseline (AUC = 0.881) and the published HP benchmark (AUC = 0.88). The +0.097 gain confirms that river connectivity carries predictive signal that pixel-based models miss. High-susceptibility zones overlap 1,457 km of highways (including 217 km of the Manali-Leh corridor), 2,759 bridges, and 4 major hydroelectric installations. Conformal intervals achieved 82.9% empirical coverage on the held-out 2023 test set; lower coverage in high-risk zones (45-59%) points to SAR label noise as a target for future work.
Hybrid LLM-Embedded Dialogue Agents for Learner Reflection: Designing Responsive and Theory-Driven Interactions
Feb 24, 2026Dialogue systems have long supported learner reflections, with theoretically grounded, rule-based designs offering structured scaffolding but often struggling to respond to shifts in engagement. Large Language Models (LLMs), in contrast, can generate context-sensitive responses but are not informed by decades of research on how learning interactions should be structured, raising questions about their alignment with pedagogical theories. This paper presents a hybrid dialogue system that embeds LLM responsiveness within a theory-aligned, rule-based framework to support learner reflections in a culturally responsive robotics summer camp. The rule-based structure grounds dialogue in self-regulated learning theory, while the LLM decides when and how to prompt deeper reflections, responding to evolving conversation context. We analyze themes across dialogues to explore how our hybrid system shaped learner reflections. Our findings indicate that LLM-embedded dialogues supported richer learner reflections on goals and activities, but also introduced challenges due to repetitiveness and misalignment in prompts, reducing engagement.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025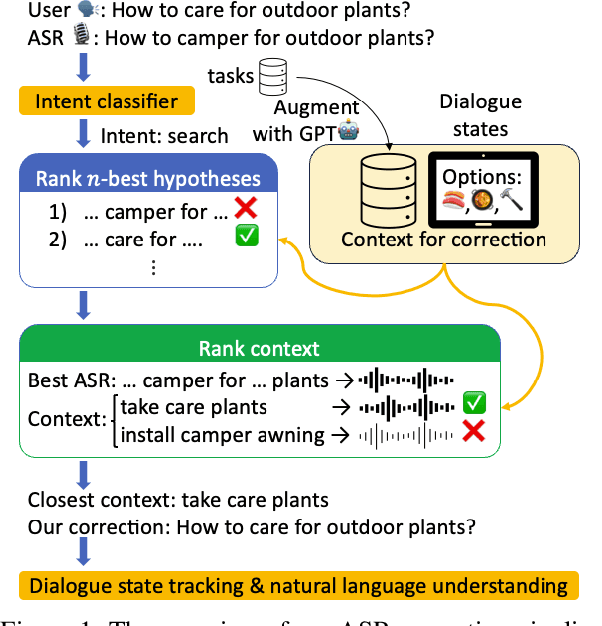
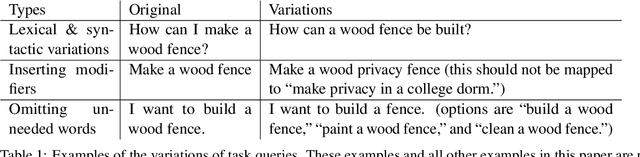


General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
A Model-free Deep Reinforcement Learning Approach To Maneuver A Quadrotor Despite Single Rotor Failure
Sep 22, 2021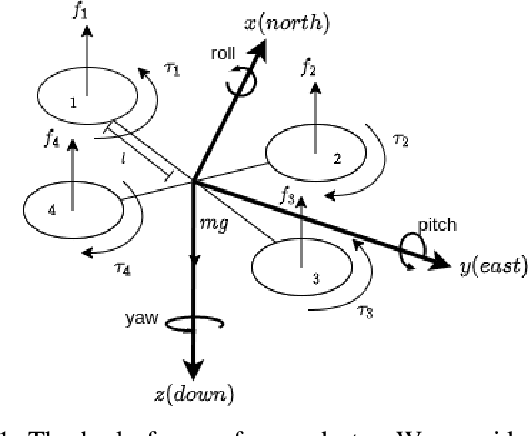
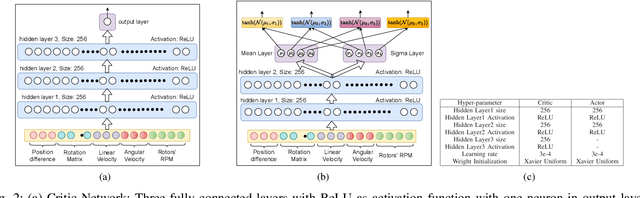
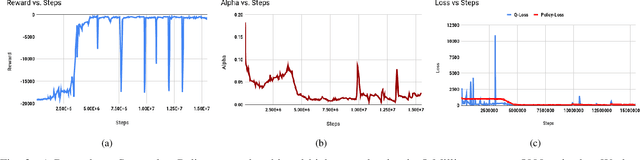
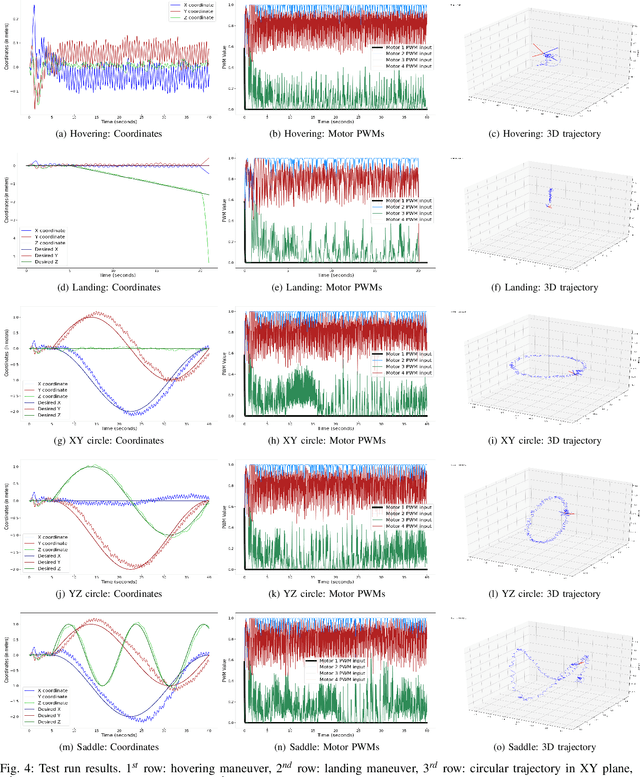
Ability to recover from faults and continue mission is desirable for many quadrotor applications. The quadrotor's rotor may fail while performing a mission and it is essential to develop recovery strategies so that the vehicle is not damaged. In this paper, we develop a model-free deep reinforcement learning approach for a quadrotor to recover from a single rotor failure. The approach is based on Soft-actor-critic that enables the vehicle to hover, land, and perform complex maneuvers. Simulation results are presented to validate the proposed approach using a custom simulator. The results show that the proposed approach achieves hover, landing, and path following in 2D and 3D. We also show that the proposed approach is robust to wind disturbances.