 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonworks Lunara Aesthetic II: An Image Variation Dataset
Feb 03, 2026We introduce Lunara Aesthetic II, a publicly released, ethically sourced image dataset designed to support controlled evaluation and learning of contextual consistency in modern image generation and editing systems. The dataset comprises 2,854 anchor-linked variation pairs derived from original art and photographs created by Moonworks. Each variation pair applies contextual transformations, such as illumination, weather, viewpoint, scene composition, color tone, or mood; while preserving a stable underlying identity. Lunara Aesthetic II operationalizes identity-preserving contextual variation as a supervision signal while also retaining Lunara's signature high aesthetic scores. Results show high identity stability, strong target attribute realization, and a robust aesthetic profile that exceeds large-scale web datasets. Released under the Apache 2.0 license, Lunara Aesthetic II is intended for benchmarking, fine-tuning, and analysis of contextual generalization, identity preservation, and edit robustness in image generation and image-to-image systems with interpretable, relational supervision. The dataset is publicly available at: https://huggingface.co/datasets/moonworks/lunara-aesthetic-image-variations.
Moonworks Lunara Aesthetic Dataset
Jan 12, 2026The dataset spans diverse artistic styles, including regionally grounded aesthetics from the Middle East, Northern Europe, East Asia, and South Asia, alongside general categories such as sketch and oil painting. All images are generated using the Moonworks Lunara model and intentionally crafted to embody distinct, high-quality aesthetic styles, yielding a first-of-its-kind dataset with substantially higher aesthetic scores, exceeding even aesthetics-focused datasets, and general-purpose datasets by a larger margin. Each image is accompanied by a human-refined prompt and structured annotations that jointly describe salient objects, attributes, relationships, and stylistic cues. Unlike large-scale web-derived datasets that emphasize breadth over precision, the Lunara Aesthetic Dataset prioritizes aesthetic quality, stylistic diversity, and licensing transparency, and is released under the Apache 2.0 license to support research and unrestricted academic and commercial use.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025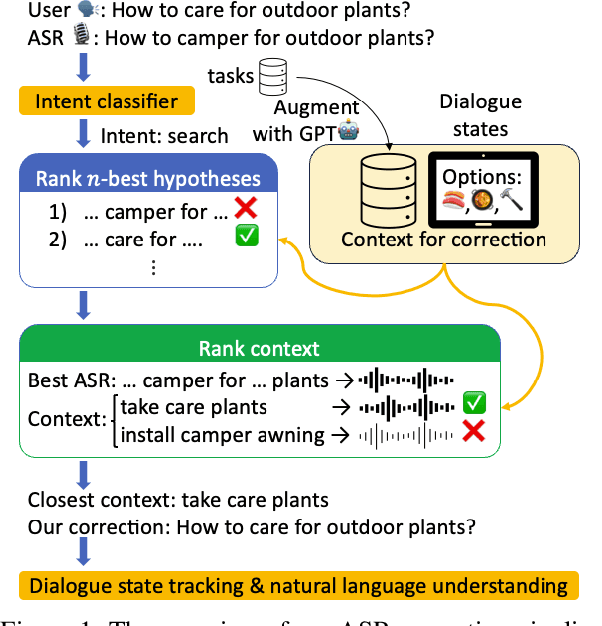
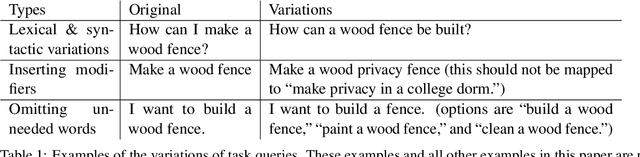


General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
Coherence-Driven Multimodal Safety Dialogue with Active Learning for Embodied Agents
Oct 18, 2024

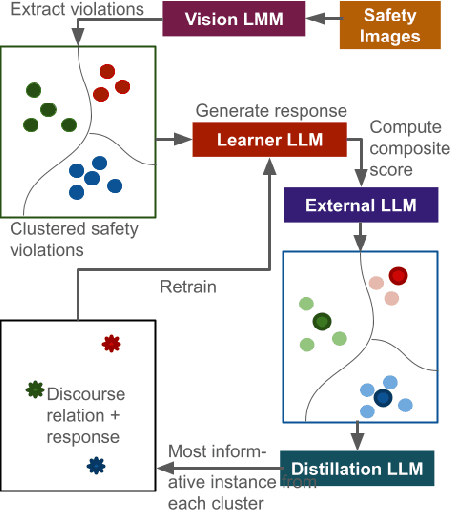
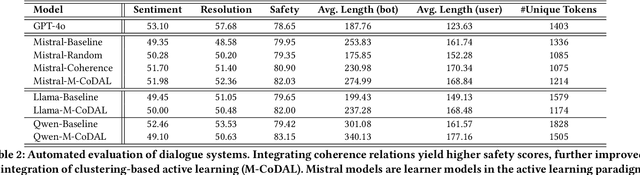
When assisting people in daily tasks, robots need to accurately interpret visual cues and respond effectively in diverse safety-critical situations, such as sharp objects on the floor. In this context, we present M-CoDAL, a multimodal-dialogue system specifically designed for embodied agents to better understand and communicate in safety-critical situations. The system leverages discourse coherence relations to enhance its contextual understanding and communication abilities. To train this system, we introduce a novel clustering-based active learning mechanism that utilizes an external Large Language Model (LLM) to identify informative instances. Our approach is evaluated using a newly created multimodal dataset comprising 1K safety violations extracted from 2K Reddit images. These violations are annotated using a Large Multimodal Model (LMM) and verified by human annotators. Results with this dataset demonstrate that our approach improves resolution of safety situations, user sentiment, as well as safety of the conversation. Next, we deploy our dialogue system on a Hello Robot Stretch robot and conduct a within-subject user study with real-world participants. In the study, participants role-play two safety scenarios with different levels of severity with the robot and receive interventions from our model and a baseline system powered by OpenAI's ChatGPT. The study results corroborate and extend the findings from automated evaluation, showing that our proposed system is more persuasive and competent in a real-world embodied agent setting.
An Active Learning Framework for Inclusive Generation by Large Language Models
Oct 17, 2024Ensuring that Large Language Models (LLMs) generate text representative of diverse sub-populations is essential, particularly when key concepts related to under-represented groups are scarce in the training data. We address this challenge with a novel clustering-based active learning framework, enhanced with knowledge distillation. The proposed framework transforms the intermediate outputs of the learner model, enabling effective active learning for generative tasks for the first time. Integration of clustering and knowledge distillation yields more representative models without prior knowledge of underlying data distribution and overbearing human efforts. We validate our approach in practice through case studies in counter-narration and style transfer. We construct two new datasets in tandem with model training, showing a performance improvement of 2%-10% over baseline models. Our results also show more consistent performance across various data subgroups and increased lexical diversity, underscoring our model's resilience to skewness in available data. Further, our results show that the data acquired via our approach improves the performance of secondary models not involved in the learning loop, showcasing practical utility of the framework.
Active Learning for Robust and Representative LLM Generation in Safety-Critical Scenarios
Oct 14, 2024Ensuring robust safety measures across a wide range of scenarios is crucial for user-facing systems. While Large Language Models (LLMs) can generate valuable data for safety measures, they often exhibit distributional biases, focusing on common scenarios and neglecting rare but critical cases. This can undermine the effectiveness of safety protocols developed using such data. To address this, we propose a novel framework that integrates active learning with clustering to guide LLM generation, enhancing their representativeness and robustness in safety scenarios. We demonstrate the effectiveness of our approach by constructing a dataset of 5.4K potential safety violations through an iterative process involving LLM generation and an active learner model's feedback. Our results show that the proposed framework produces a more representative set of safety scenarios without requiring prior knowledge of the underlying data distribution. Additionally, data acquired through our method improves the accuracy and F1 score of both the active learner model as well models outside the scope of active learning process, highlighting its broad applicability.
DisCGen: A Framework for Discourse-Informed Counterspeech Generation
Nov 29, 2023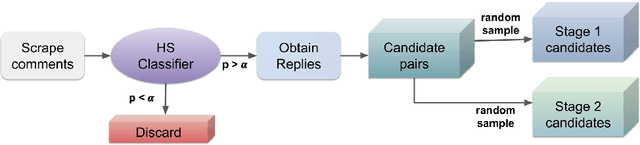
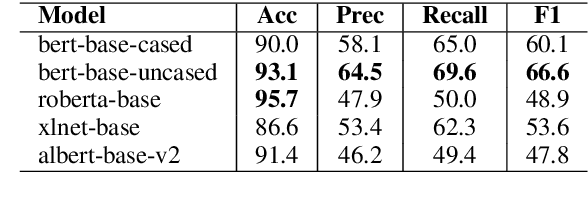
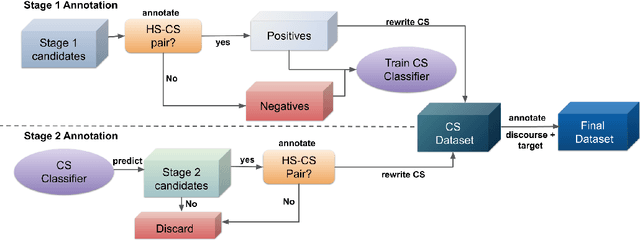
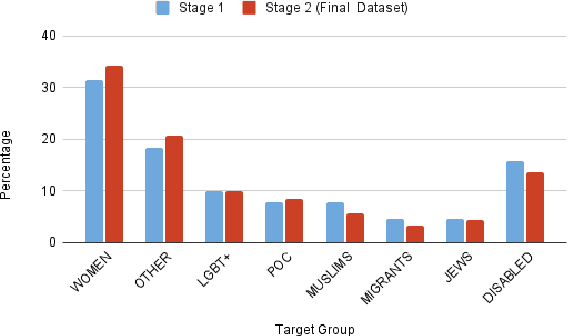
Counterspeech can be an effective method for battling hateful content on social media. Automated counterspeech generation can aid in this process. Generated counterspeech, however, can be viable only when grounded in the context of topic, audience and sensitivity as these factors influence both the efficacy and appropriateness. In this work, we propose a novel framework based on theories of discourse to study the inferential links that connect counter speeches to the hateful comment. Within this framework, we propose: i) a taxonomy of counterspeech derived from discourse frameworks, and ii) discourse-informed prompting strategies for generating contextually-grounded counterspeech. To construct and validate this framework, we present a process for collecting an in-the-wild dataset of counterspeech from Reddit. Using this process, we manually annotate a dataset of 3.9k Reddit comment pairs for the presence of hatespeech and counterspeech. The positive pairs are annotated for 10 classes in our proposed taxonomy. We annotate these pairs with paraphrased counterparts to remove offensiveness and first-person references. We show that by using our dataset and framework, large language models can generate contextually-grounded counterspeech informed by theories of discourse. According to our human evaluation, our approaches can act as a safeguard against critical failures of discourse-agnostic models.
MedNgage: A Dataset for Understanding Engagement in Patient-Nurse Conversations
May 31, 2023
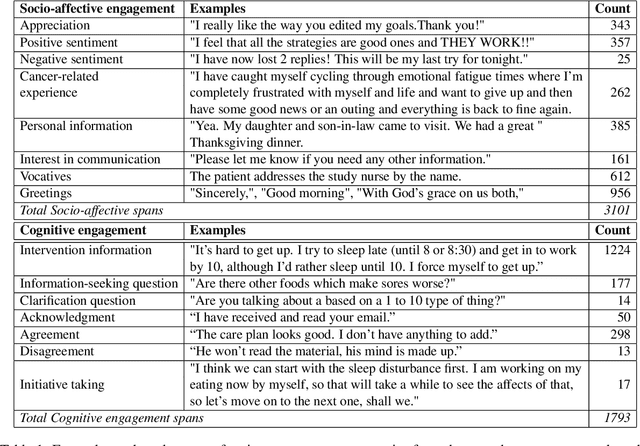
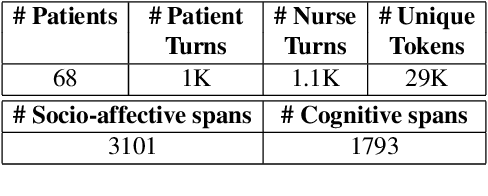
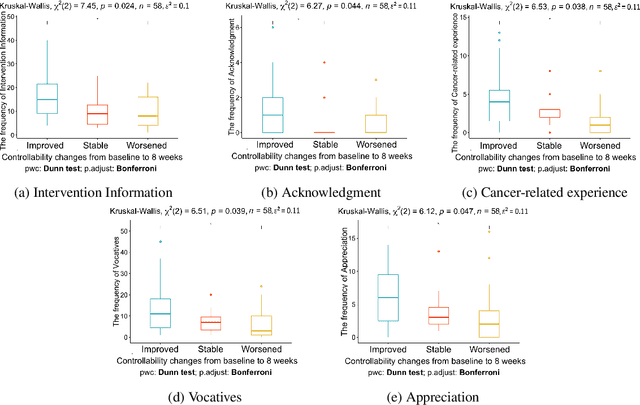
Patients who effectively manage their symptoms often demonstrate higher levels of engagement in conversations and interventions with healthcare practitioners. This engagement is multifaceted, encompassing cognitive and socio-affective dimensions. Consequently, it is crucial for AI systems to understand the engagement in natural conversations between patients and practitioners to better contribute toward patient care. In this paper, we present a novel dataset (MedNgage), which consists of patient-nurse conversations about cancer symptom management. We manually annotate the dataset with a novel framework of categories of patient engagement from two different angles, namely: i) socio-affective engagement (3.1K spans), and ii) cognitive engagement (1.8K spans). Through statistical analysis of the data that is annotated using our framework, we show a positive correlation between patient symptom management outcomes and their engagement in conversations. Additionally, we demonstrate that pre-trained transformer models fine-tuned on our dataset can reliably predict engagement categories in patient-nurse conversations. Lastly, we use LIME (Ribeiro et al., 2016) to analyze the underlying challenges of the tasks that state-of-the-art transformer models encounter. The de-identified data is available for research purposes upon request.
D-CALM: A Dynamic Clustering-based Active Learning Approach for Mitigating Bias
May 26, 2023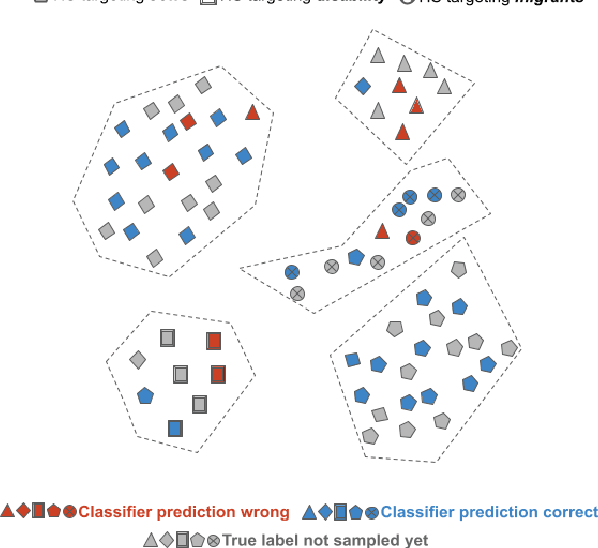
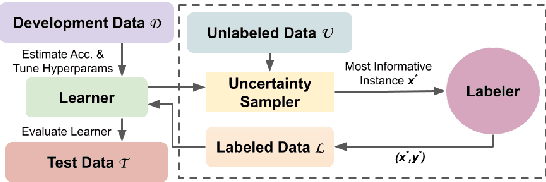
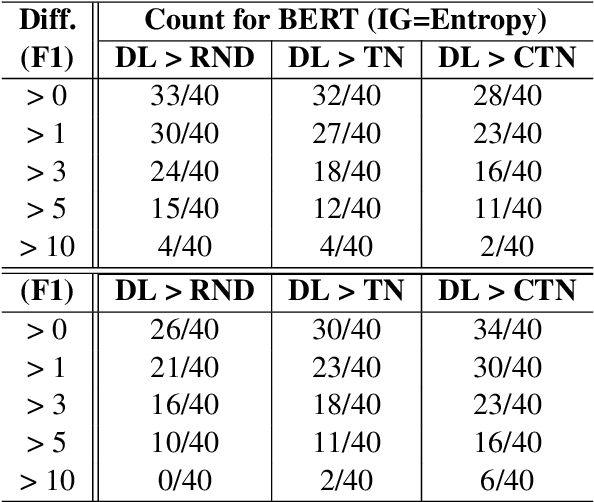
Despite recent advancements, NLP models continue to be vulnerable to bias. This bias often originates from the uneven distribution of real-world data and can propagate through the annotation process. Escalated integration of these models in our lives calls for methods to mitigate bias without overbearing annotation costs. While active learning (AL) has shown promise in training models with a small amount of annotated data, AL's reliance on the model's behavior for selective sampling can lead to an accumulation of unwanted bias rather than bias mitigation. However, infusing clustering with AL can overcome the bias issue of both AL and traditional annotation methods while exploiting AL's annotation efficiency. In this paper, we propose a novel adaptive clustering-based active learning algorithm, D-CALM, that dynamically adjusts clustering and annotation efforts in response to an estimated classifier error-rate. Experiments on eight datasets for a diverse set of text classification tasks, including emotion, hatespeech, dialog act, and book type detection, demonstrate that our proposed algorithm significantly outperforms baseline AL approaches with both pretrained transformers and traditional Support Vector Machines. D-CALM showcases robustness against different measures of information gain and, as evident from our analysis of label and error distribution, can significantly reduce unwanted model bias.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023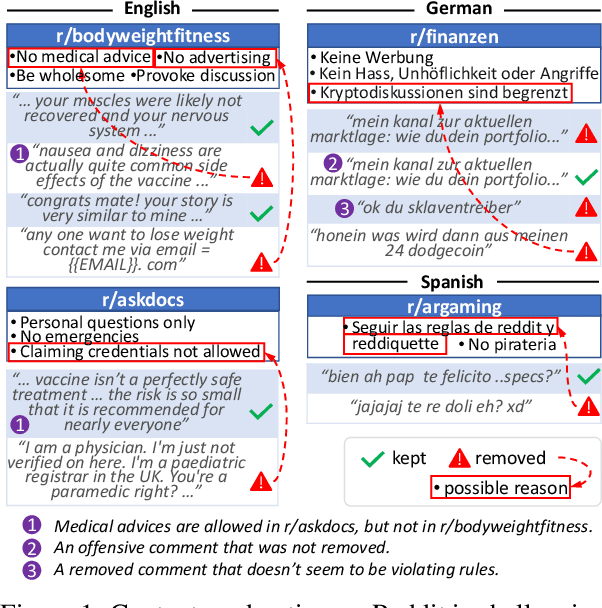
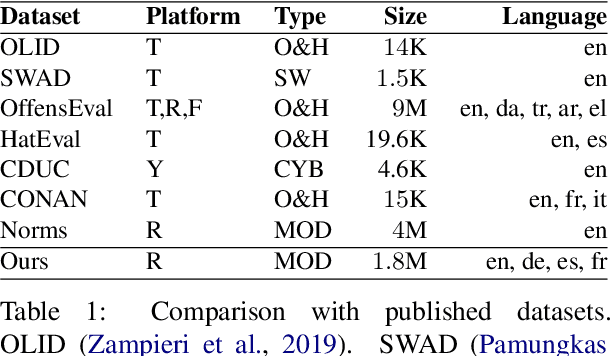
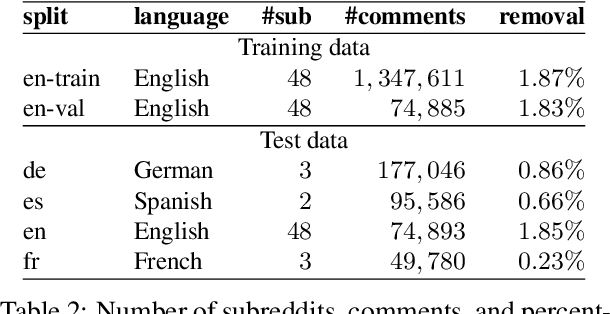
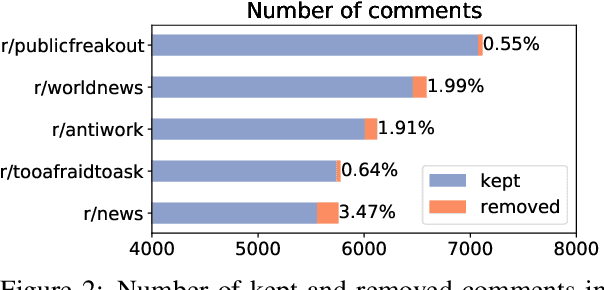
Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.