 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCGen: A Framework for Discourse-Informed Counterspeech Generation
Paper and Code
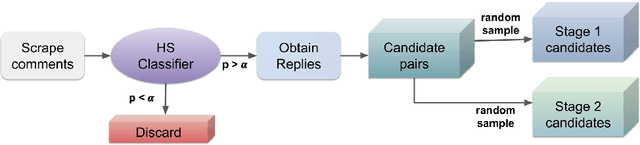
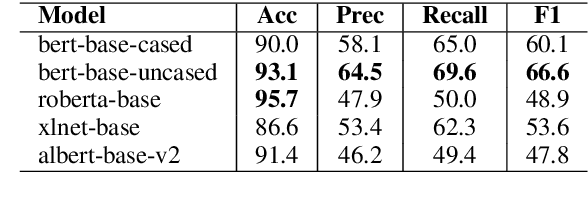
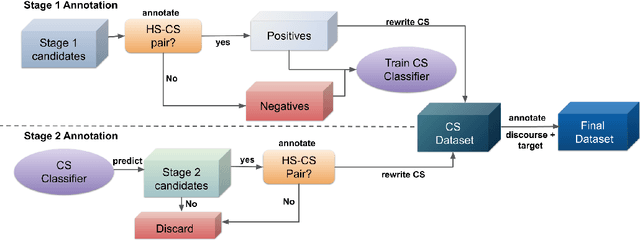
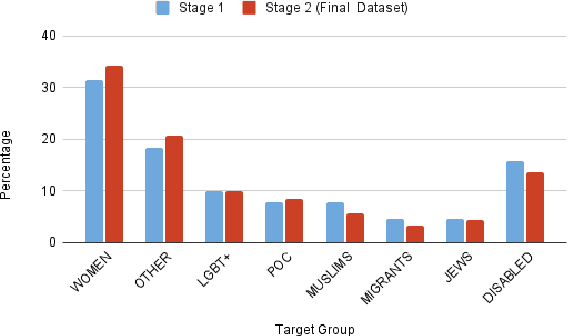
Counterspeech can be an effective method for battling hateful content on social media. Automated counterspeech generation can aid in this process. Generated counterspeech, however, can be viable only when grounded in the context of topic, audience and sensitivity as these factors influence both the efficacy and appropriateness. In this work, we propose a novel framework based on theories of discourse to study the inferential links that connect counter speeches to the hateful comment. Within this framework, we propose: i) a taxonomy of counterspeech derived from discourse frameworks, and ii) discourse-informed prompting strategies for generating contextually-grounded counterspeech. To construct and validate this framework, we present a process for collecting an in-the-wild dataset of counterspeech from Reddit. Using this process, we manually annotate a dataset of 3.9k Reddit comment pairs for the presence of hatespeech and counterspeech. The positive pairs are annotated for 10 classes in our proposed taxonomy. We annotate these pairs with paraphrased counterparts to remove offensiveness and first-person references. We show that by using our dataset and framework, large language models can generate contextually-grounded counterspeech informed by theories of discourse. According to our human evaluation, our approaches can act as a safeguard against critical failures of discourse-agnostic models.