 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntention-Adaptive LLM Fine-Tuning for Text Revision Generation
Jan 31, 2026Large Language Models (LLMs) have achieved impressive capabilities in various context-based text generation tasks, such as summarization and reasoning; however, their applications in intention-based generation tasks remain underexplored. One such example is revision generation, which requires the generated text to explicitly reflect the writer's actual intentions. Identifying intentions and generating desirable revisions are challenging due to their complex and diverse nature. Although prior work has employed LLMs to generate revisions with few-shot learning, they struggle with handling entangled multi-intent scenarios. While fine-tuning LLMs using intention-based instructions appears promising, it demands large amounts of annotated data, which is expensive and scarce in the revision community. To address these challenges, we propose Intention-Tuning, an intention-adaptive layer-wise LLM fine-tuning framework that dynamically selects a subset of LLM layers to learn the intentions and subsequently transfers their representations to revision generation. Experimental results suggest that Intention-Tuning is effective and efficient on small revision corpora, outperforming several PEFT baselines.
ARC: Argument Representation and Coverage Analysis for Zero-Shot Long Document Summarization with Instruction Following LLMs
May 29, 2025Integrating structured information has long improved the quality of abstractive summarization, particularly in retaining salient content. In this work, we focus on a specific form of structure: argument roles, which are crucial for summarizing documents in high-stakes domains such as law. We investigate whether instruction-tuned large language models (LLMs) adequately preserve this information. To this end, we introduce Argument Representation Coverage (ARC), a framework for measuring how well LLM-generated summaries capture salient arguments. Using ARC, we analyze summaries produced by three open-weight LLMs in two domains where argument roles are central: long legal opinions and scientific articles. Our results show that while LLMs cover salient argument roles to some extent, critical information is often omitted in generated summaries, particularly when arguments are sparsely distributed throughout the input. Further, we use ARC to uncover behavioral patterns -- specifically, how the positional bias of LLM context windows and role-specific preferences impact the coverage of key arguments in generated summaries, emphasizing the need for more argument-aware summarization strategies.
Discourse-Driven Evaluation: Unveiling Factual Inconsistency in Long Document Summarization
Feb 10, 2025Detecting factual inconsistency for long document summarization remains challenging, given the complex structure of the source article and long summary length. In this work, we study factual inconsistency errors and connect them with a line of discourse analysis. We find that errors are more common in complex sentences and are associated with several discourse features. We propose a framework that decomposes long texts into discourse-inspired chunks and utilizes discourse information to better aggregate sentence-level scores predicted by natural language inference models. Our approach shows improved performance on top of different model baselines over several evaluation benchmarks, covering rich domains of texts, focusing on long document summarization. This underscores the significance of incorporating discourse features in developing models for scoring summaries for long document factual inconsistency.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025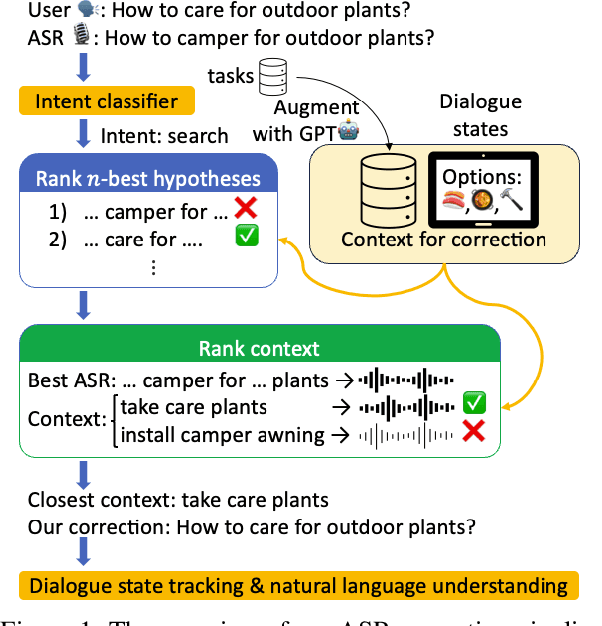
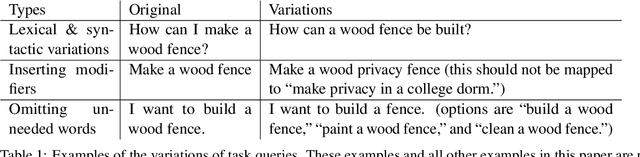


General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
eRevise+RF: A Writing Evaluation System for Assessing Student Essay Revisions and Providing Formative Feedback
Jan 01, 2025



The ability to revise essays in response to feedback is important for students' writing success. An automated writing evaluation (AWE) system that supports students in revising their essays is thus essential. We present eRevise+RF, an enhanced AWE system for assessing student essay revisions (e.g., changes made to an essay to improve its quality in response to essay feedback) and providing revision feedback. We deployed the system with 6 teachers and 406 students across 3 schools in Pennsylvania and Louisiana. The results confirmed its effectiveness in (1) assessing student essays in terms of evidence usage, (2) extracting evidence and reasoning revisions across essays, and (3) determining revision success in responding to feedback. The evaluation also suggested eRevise+RF is a helpful system for young students to improve their argumentative writing skills through revision and formative feedback.
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Jun 20, 2024Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
Analyzing Large Language Models for Classroom Discussion Assessment
Jun 12, 2024

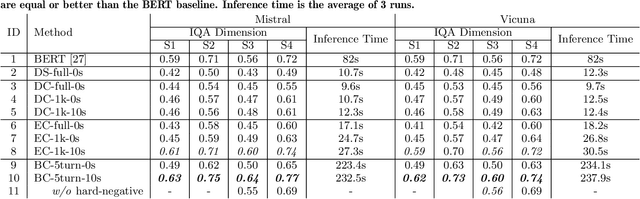
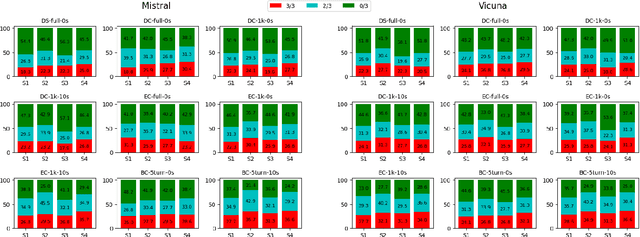
Automatically assessing classroom discussion quality is becoming increasingly feasible with the help of new NLP advancements such as large language models (LLMs). In this work, we examine how the assessment performance of 2 LLMs interacts with 3 factors that may affect performance: task formulation, context length, and few-shot examples. We also explore the computational efficiency and predictive consistency of the 2 LLMs. Our results suggest that the 3 aforementioned factors do affect the performance of the tested LLMs and there is a relation between consistency and performance. We recommend a LLM-based assessment approach that has a good balance in terms of predictive performance, computational efficiency, and consistency.
What metrics of participation balance predict outcomes of collaborative learning with a robot?
May 17, 2024

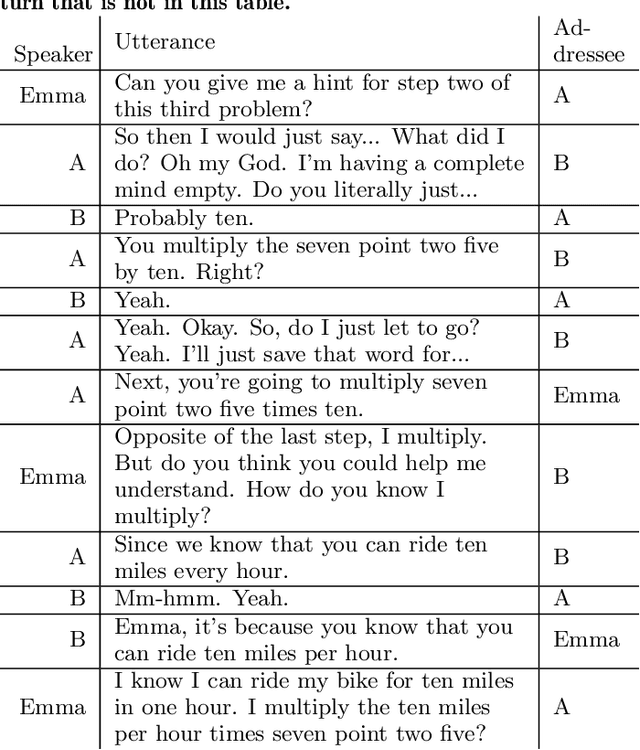
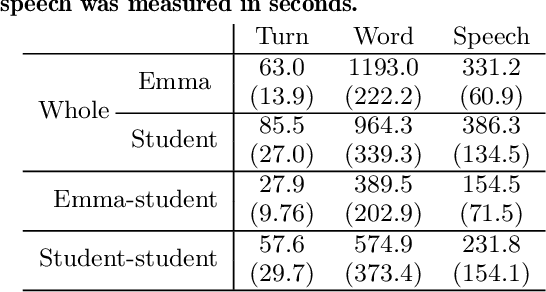
One of the keys to the success of collaborative learning is balanced participation by all learners, but this does not always happen naturally. Pedagogical robots have the potential to facilitate balance. However, it remains unclear what participation balance robots should aim at; various metrics have been proposed, but it is still an open question whether we should balance human participation in human-human interactions (HHI) or human-robot interactions (HRI) and whether we should consider robots' participation in collaborative learning involving multiple humans and a robot. This paper examines collaborative learning between a pair of students and a teachable robot that acts as a peer tutee to answer the aforementioned question. Through an exploratory study, we hypothesize which balance metrics in the literature and which portions of dialogues (including vs. excluding robots' participation and human participation in HHI vs. HRI) will better predict learning as a group. We test the hypotheses with another study and replicate them with automatically obtained units of participation to simulate the information available to robots when they adaptively fix imbalances in real-time. Finally, we discuss recommendations on which metrics learning science researchers should choose when trying to understand how to facilitate collaboration.
Enhancing Knowledge Retrieval with Topic Modeling for Knowledge-Grounded Dialogue
May 07, 2024Knowledge retrieval is one of the major challenges in building a knowledge-grounded dialogue system. A common method is to use a neural retriever with a distributed approximate nearest-neighbor database to quickly find the relevant knowledge sentences. In this work, we propose an approach that utilizes topic modeling on the knowledge base to further improve retrieval accuracy and as a result, improve response generation. Additionally, we experiment with a large language model, ChatGPT, to take advantage of the improved retrieval performance to further improve the generation results. Experimental results on two datasets show that our approach can increase retrieval and generation performance. The results also indicate that ChatGPT is a better response generator for knowledge-grounded dialogue when relevant knowledge is provided.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024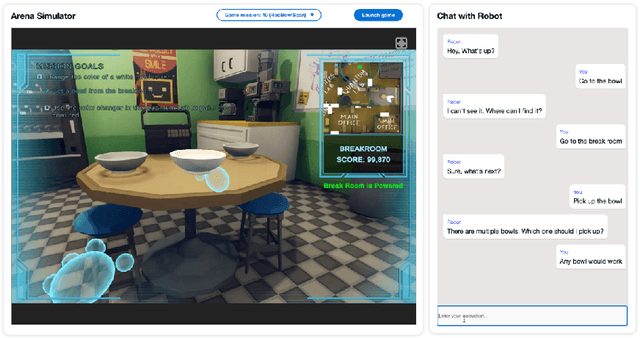
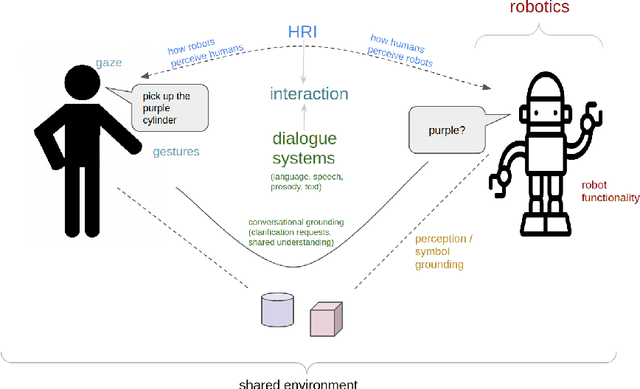
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.