 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Large Language Models for Classroom Discussion Assessment
Jun 12, 2024

Automatically assessing classroom discussion quality is becoming increasingly feasible with the help of new NLP advancements such as large language models (LLMs). In this work, we examine how the assessment performance of 2 LLMs interacts with 3 factors that may affect performance: task formulation, context length, and few-shot examples. We also explore the computational efficiency and predictive consistency of the 2 LLMs. Our results suggest that the 3 aforementioned factors do affect the performance of the tested LLMs and there is a relation between consistency and performance. We recommend a LLM-based assessment approach that has a good balance in terms of predictive performance, computational efficiency, and consistency.
Enhancing Knowledge Retrieval with Topic Modeling for Knowledge-Grounded Dialogue
May 07, 2024Knowledge retrieval is one of the major challenges in building a knowledge-grounded dialogue system. A common method is to use a neural retriever with a distributed approximate nearest-neighbor database to quickly find the relevant knowledge sentences. In this work, we propose an approach that utilizes topic modeling on the knowledge base to further improve retrieval accuracy and as a result, improve response generation. Additionally, we experiment with a large language model, ChatGPT, to take advantage of the improved retrieval performance to further improve the generation results. Experimental results on two datasets show that our approach can increase retrieval and generation performance. The results also indicate that ChatGPT is a better response generator for knowledge-grounded dialogue when relevant knowledge is provided.
Utilizing Natural Language Processing for Automated Assessment of Classroom Discussion
Jun 21, 2023


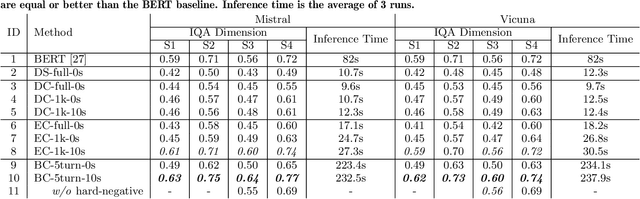
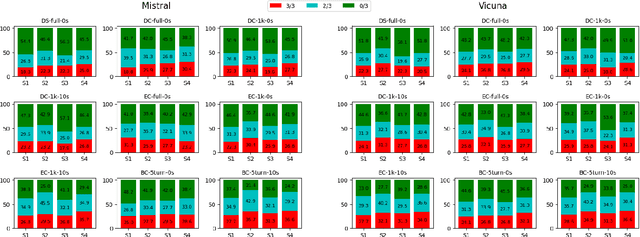
Rigorous and interactive class discussions that support students to engage in high-level thinking and reasoning are essential to learning and are a central component of most teaching interventions. However, formally assessing discussion quality 'at scale' is expensive and infeasible for most researchers. In this work, we experimented with various modern natural language processing (NLP) techniques to automatically generate rubric scores for individual dimensions of classroom text discussion quality. Specifically, we worked on a dataset of 90 classroom discussion transcripts consisting of over 18000 turns annotated with fine-grained Analyzing Teaching Moves (ATM) codes and focused on four Instructional Quality Assessment (IQA) rubrics. Despite the limited amount of data, our work shows encouraging results in some of the rubrics while suggesting that there is room for improvement in the others. We also found that certain NLP approaches work better for certain rubrics.
Layer-stacked Attention for Heterogeneous Network Embedding
Sep 17, 2020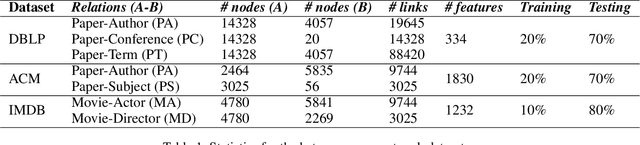
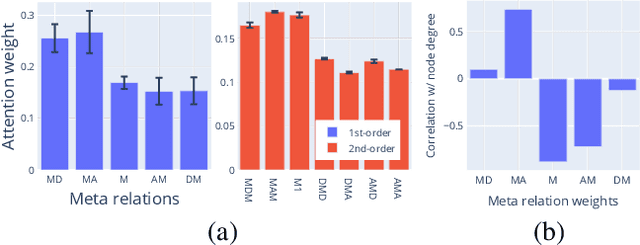
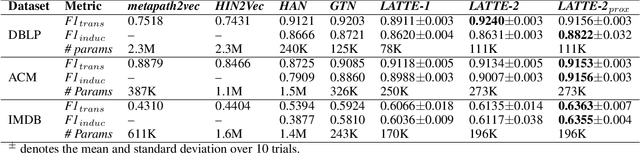
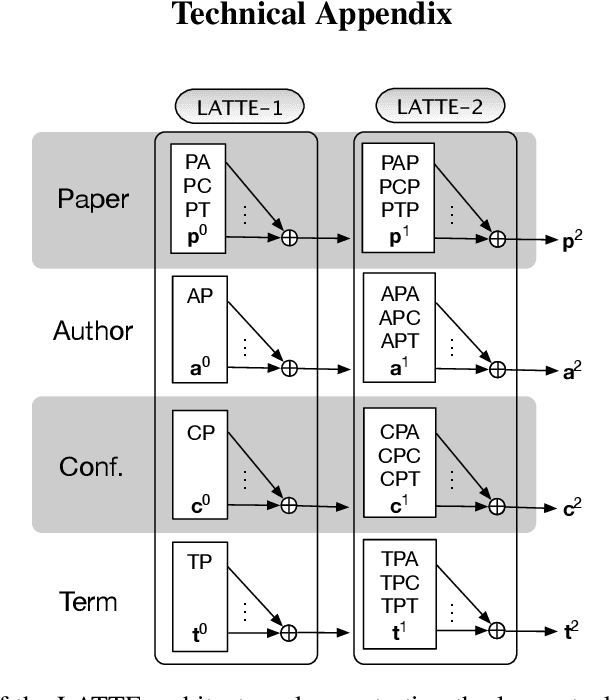
The heterogeneous network is a robust data abstraction that can model entities of different types interacting in various ways. Such heterogeneity brings rich semantic information but presents nontrivial challenges in aggregating the heterogeneous relationships between objects - especially those of higher-order indirect relations. Recent graph neural network approaches for representation learning on heterogeneous networks typically employ the attention mechanism, which is often only optimized for predictions based on direct links. Furthermore, even though most deep learning methods can aggregate higher-order information by building deeper models, such a scheme can diminish the degree of interpretability. To overcome these challenges, we explore an architecture - Layer-stacked ATTention Embedding (LATTE) - that automatically decomposes higher-order meta relations at each layer to extract the relevant heterogeneous neighborhood structures for each node. Additionally, by successively stacking layer representations, the learned node embedding offers a more interpretable aggregation scheme for nodes of different types at different neighborhood ranges. We conducted experiments on several benchmark heterogeneous network datasets. In both transductive and inductive node classification tasks, LATTE can achieve state-of-the-art performance compared to existing approaches, all while offering a lightweight model. With extensive experimental analyses and visualizations, the framework can demonstrate the ability to extract informative insights on heterogeneous networks.
Functional Representation of Large-Scale Heterogeneous RNA Sequences with Integration of Diverse Multi-omics, Interactions, and Annotations Data
Aug 07, 2019
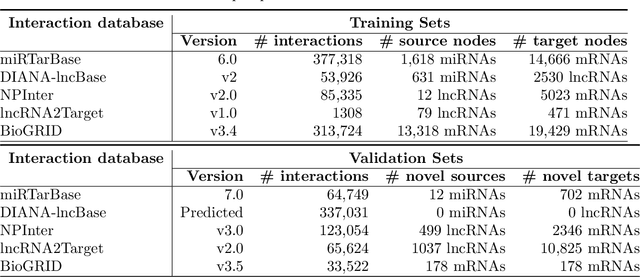

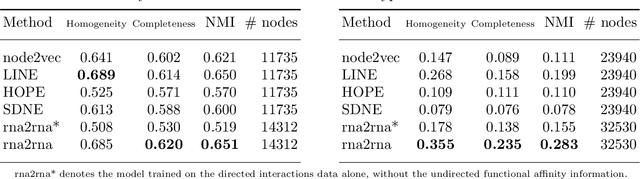
Long non-coding RNA, microRNA, and messenger RNA enable key regulations of various biological processes through a variety of diverse interaction mechanisms. Identifying the interactions and cross-talk between these heterogeneous RNA classes is essential in order to uncover the functional role of individual RNA transcripts, especially for unannotated and newly-discovered RNA sequences with no known interactions. Recently, sequence-based deep learning and network embedding methods are becoming promising approaches that can either predict RNA-RNA interactions from a sequence or infer missing interactions from patterns that may exist in the network topology. However, the majority of these methods have several limitations, eg, the inability to perform inductive predictions, to distinguish the directionality of interactions, or to integrate various sequence, interaction, and annotation biological datasets. We proposed a novel deep learning-based framework, rna2rna, which learns from RNA sequences to produce a low-dimensional embedding that preserves the proximities in both the interactions topology and the functional affinity topology. In this proposed embedding space, we have designated a two-part" source and target contexts" to capture the targeting and receptive fields of each RNA transcript, while encapsulating the heterogenous cross-talk interactions between lncRNAs and miRNAs. From experimental results, our method exhibits superior performance in AUPR rates compared to state-of-art approaches at predicting missing interactions in different RNA-RNA interaction databases and was shown to accurately perform link predictions to novel RNA sequences not seen at training time, even without any prior information. Additional results suggest that our proposed framework can capture a manifold for heterogeneous RNA sequences to discover novel functional annotations.