 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Oct 10, 2025Establishing shared goals is a fundamental step in human-AI communication. However, ambiguities can lead to outputs that seem correct but fail to reflect the speaker's intent. In this paper, we explore this issue with a focus on the data visualization domain, where ambiguities in natural language impact the generation of code that visualizes data. The availability of multiple views on the contextual (e.g., the intended plot and the code rendering the plot) allows for a unique and comprehensive analysis of diverse ambiguity types. We develop a taxonomy of types of ambiguity that arise in this task and propose metrics to quantify them. Using Matplotlib problems from the DS-1000 dataset, we demonstrate that our ambiguity metrics better correlate with human annotations than uncertainty baselines. Our work also explores how multi-turn dialogue can reduce ambiguity, therefore, improve code accuracy by better matching user goals. We evaluate three pragmatic models to inform our dialogue strategies: Gricean Cooperativity, Discourse Representation Theory, and Questions under Discussion. A simulated user study reveals how pragmatic dialogues reduce ambiguity and enhance code accuracy, highlighting the value of multi-turn exchanges in code generation.
SiLVERScore: Semantically-Aware Embeddings for Sign Language Generation Evaluation
Sep 04, 2025Evaluating sign language generation is often done through back-translation, where generated signs are first recognized back to text and then compared to a reference using text-based metrics. However, this two-step evaluation pipeline introduces ambiguity: it not only fails to capture the multimodal nature of sign language-such as facial expressions, spatial grammar, and prosody-but also makes it hard to pinpoint whether evaluation errors come from sign generation model or the translation system used to assess it. In this work, we propose SiLVERScore, a novel semantically-aware embedding-based evaluation metric that assesses sign language generation in a joint embedding space. Our contributions include: (1) identifying limitations of existing metrics, (2) introducing SiLVERScore for semantically-aware evaluation, (3) demonstrating its robustness to semantic and prosodic variations, and (4) exploring generalization challenges across datasets. On PHOENIX-14T and CSL-Daily datasets, SiLVERScore achieves near-perfect discrimination between correct and random pairs (ROC AUC = 0.99, overlap < 7%), substantially outperforming traditional metrics.
Measuring How (Not Just Whether) VLMs Build Common Ground
Sep 04, 2025Large vision language models (VLMs) increasingly claim reasoning skills, yet current benchmarks evaluate them in single-turn or question answering settings. However, grounding is an interactive process in which people gradually develop shared understanding through ongoing communication. We introduce a four-metric suite (grounding efficiency, content alignment, lexical adaptation, and human-likeness) to systematically evaluate VLM performance in interactive grounding contexts. We deploy the suite on 150 self-play sessions of interactive referential games between three proprietary VLMs and compare them with human dyads. All three models diverge from human patterns on at least three metrics, while GPT4o-mini is the closest overall. We find that (i) task success scores do not indicate successful grounding and (ii) high image-utterance alignment does not necessarily predict task success. Our metric suite and findings offer a framework for future research on VLM grounding.
Quantifying Sycophancy as Deviations from Bayesian Rationality in LLMs
Aug 23, 2025Sycophancy, or overly agreeable or flattering behavior, is a documented issue in large language models (LLMs), and is critical to understand in the context of human/AI collaboration. Prior works typically quantify sycophancy by measuring shifts in behavior or impacts on accuracy, but neither metric characterizes shifts in rationality, and accuracy measures can only be used in scenarios with a known ground truth. In this work, we utilize a Bayesian framework to quantify sycophancy as deviations from rational behavior when presented with user perspectives, thus distinguishing between rational and irrational updates based on the introduction of user perspectives. In comparison to other methods, this approach allows us to characterize excessive behavioral shifts, even for tasks that involve inherent uncertainty or do not have a ground truth. We study sycophancy for 3 different tasks, a combination of open-source and closed LLMs, and two different methods for probing sycophancy. We also experiment with multiple methods for eliciting probability judgments from LLMs. We hypothesize that probing LLMs for sycophancy will cause deviations in LLMs' predicted posteriors that will lead to increased Bayesian error. Our findings indicate that: 1) LLMs are not Bayesian rational, 2) probing for sycophancy results in significant increases to the predicted posterior in favor of the steered outcome, 3) sycophancy sometimes results in increased Bayesian error, and in a small number of cases actually decreases error, and 4) changes in Bayesian error due to sycophancy are not strongly correlated in Brier score, suggesting that studying the impact of sycophancy on ground truth alone does not fully capture errors in reasoning due to sycophancy.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025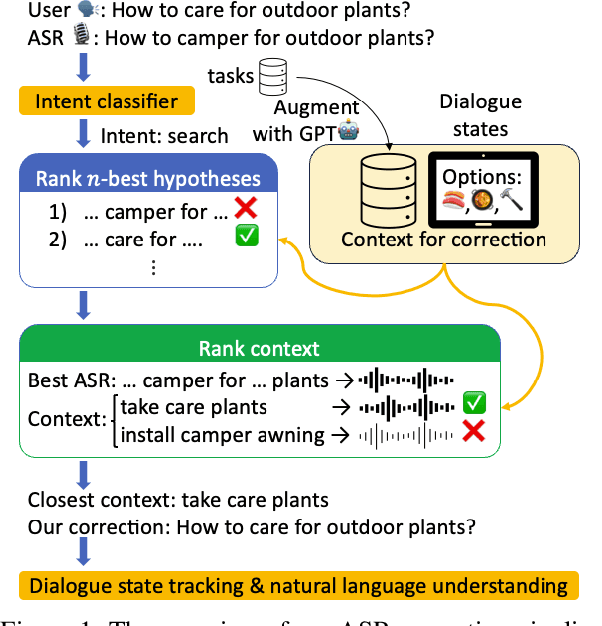
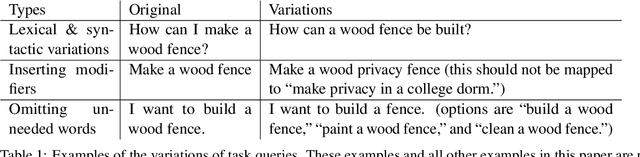


General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
Generating Signed Language Instructions in Large-Scale Dialogue Systems
Oct 17, 2024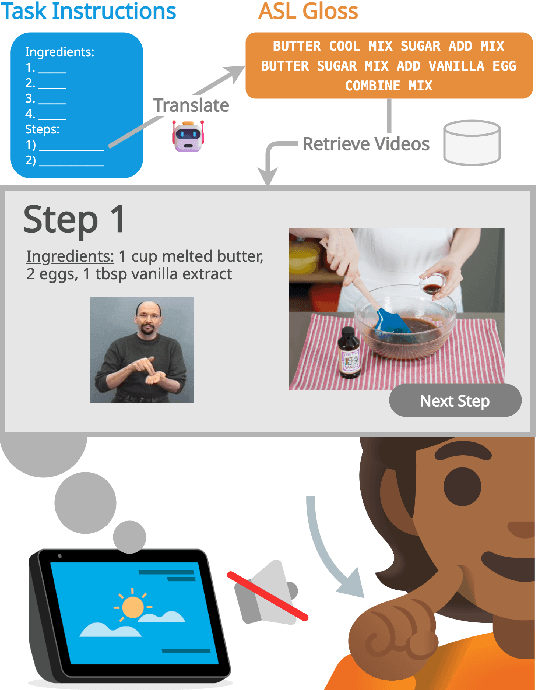
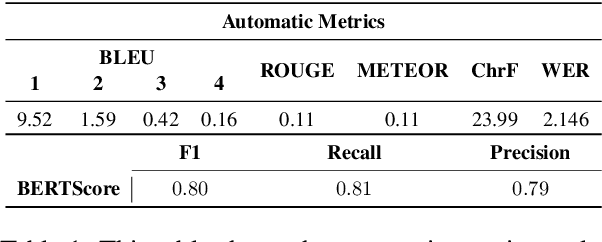
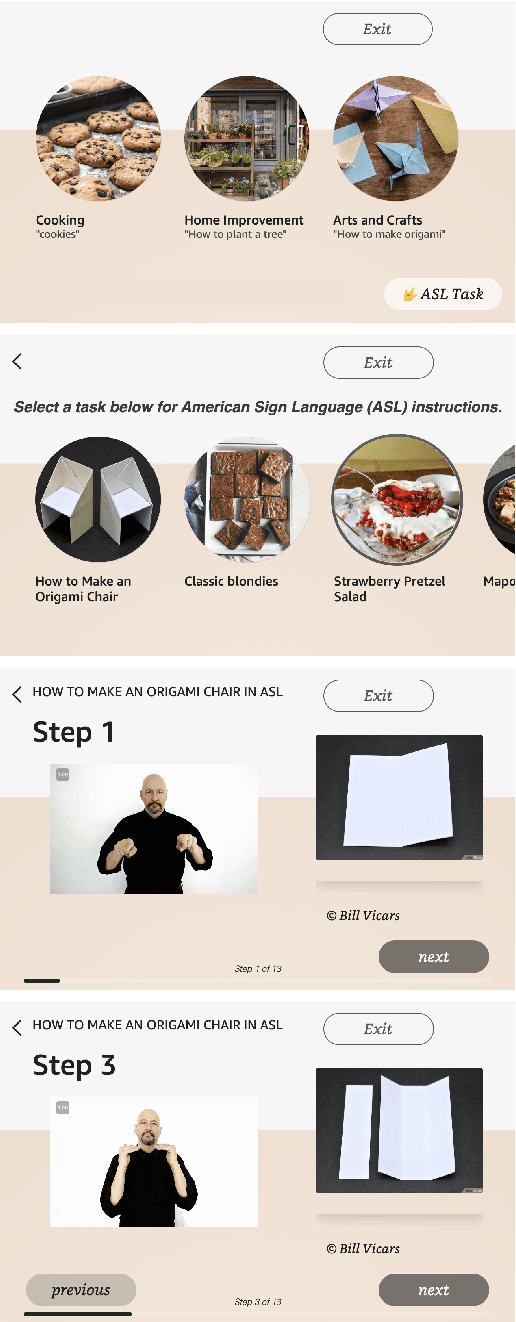
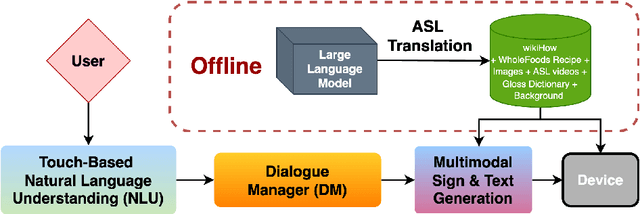
We introduce a goal-oriented conversational AI system enhanced with American Sign Language (ASL) instructions, presenting the first implementation of such a system on a worldwide multimodal conversational AI platform. Accessible through a touch-based interface, our system receives input from users and seamlessly generates ASL instructions by leveraging retrieval methods and cognitively based gloss translations. Central to our design is a sign translation module powered by Large Language Models, alongside a token-based video retrieval system for delivering instructional content from recipes and wikiHow guides. Our development process is deeply rooted in a commitment to community engagement, incorporating insights from the Deaf and Hard-of-Hearing community, as well as experts in cognitive and ASL learning sciences. The effectiveness of our signing instructions is validated by user feedback, achieving ratings on par with those of the system in its non-signing variant. Additionally, our system demonstrates exceptional performance in retrieval accuracy and text-generation quality, measured by metrics such as BERTScore. We have made our codebase and datasets publicly accessible at https://github.com/Merterm/signed-dialogue, and a demo of our signed instruction video retrieval system is available at https://huggingface.co/spaces/merterm/signed-instructions.
Eliciting Uncertainty in Chain-of-Thought to Mitigate Bias against Forecasting Harmful User Behaviors
Oct 17, 2024Conversation forecasting tasks a model with predicting the outcome of an unfolding conversation. For instance, it can be applied in social media moderation to predict harmful user behaviors before they occur, allowing for preventative interventions. While large language models (LLMs) have recently been proposed as an effective tool for conversation forecasting, it's unclear what biases they may have, especially against forecasting the (potentially harmful) outcomes we request them to predict during moderation. This paper explores to what extent model uncertainty can be used as a tool to mitigate potential biases. Specifically, we ask three primary research questions: 1) how does LLM forecasting accuracy change when we ask models to represent their uncertainty; 2) how does LLM bias change when we ask models to represent their uncertainty; 3) how can we use uncertainty representations to reduce or completely mitigate biases without many training data points. We address these questions for 5 open-source language models tested on 2 datasets designed to evaluate conversation forecasting for social media moderation.
Accounting for Sycophancy in Language Model Uncertainty Estimation
Oct 17, 2024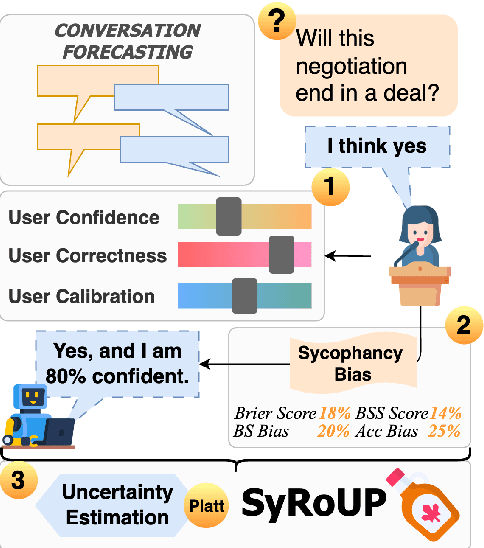



Effective human-machine collaboration requires machine learning models to externalize uncertainty, so users can reflect and intervene when necessary. For language models, these representations of uncertainty may be impacted by sycophancy bias: proclivity to agree with users, even if they are wrong. For instance, models may be over-confident in (incorrect) problem solutions suggested by a user. We study the relationship between sycophancy and uncertainty estimation for the first time. We propose a generalization of the definition of sycophancy bias to measure downstream impacts on uncertainty estimation, and also propose a new algorithm (SyRoUP) to account for sycophancy in the uncertainty estimation process. Unlike previous works on sycophancy, we study a broad array of user behaviors, varying both correctness and confidence of user suggestions to see how model answers (and their certainty) change. Our experiments across conversation forecasting and question-answering tasks show that user confidence plays a critical role in modulating the effects of sycophancy, and that SyRoUP can better predict these effects. From these results, we argue that externalizing both model and user uncertainty can help to mitigate the impacts of sycophancy bias.
An Active Learning Framework for Inclusive Generation by Large Language Models
Oct 17, 2024Ensuring that Large Language Models (LLMs) generate text representative of diverse sub-populations is essential, particularly when key concepts related to under-represented groups are scarce in the training data. We address this challenge with a novel clustering-based active learning framework, enhanced with knowledge distillation. The proposed framework transforms the intermediate outputs of the learner model, enabling effective active learning for generative tasks for the first time. Integration of clustering and knowledge distillation yields more representative models without prior knowledge of underlying data distribution and overbearing human efforts. We validate our approach in practice through case studies in counter-narration and style transfer. We construct two new datasets in tandem with model training, showing a performance improvement of 2%-10% over baseline models. Our results also show more consistent performance across various data subgroups and increased lexical diversity, underscoring our model's resilience to skewness in available data. Further, our results show that the data acquired via our approach improves the performance of secondary models not involved in the learning loop, showcasing practical utility of the framework.