 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeal, or no deal ? Forecasting Uncertainty in Conversations using Large Language Models
Paper and Code

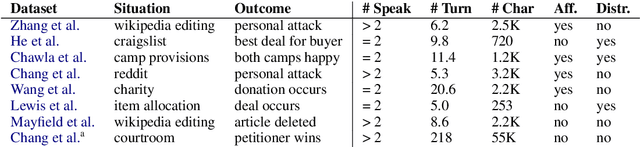

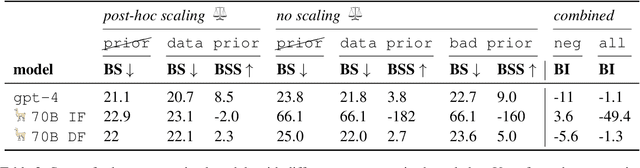
Effective interlocutors account for the uncertain goals, beliefs, and emotions of others. But even the best human conversationalist cannot perfectly anticipate the trajectory of a dialogue. How well can language models represent inherent uncertainty in conversations? We propose FortUne Dial, an expansion of the long-standing "conversation forecasting" task: instead of just accuracy, evaluation is conducted with uncertainty-aware metrics, effectively enabling abstention on individual instances. We study two ways in which language models potentially represent outcome uncertainty (internally, using scores and directly, using tokens) and propose fine-tuning strategies to improve calibration of both representations. Experiments on eight difficult negotiation corpora demonstrate that our proposed fine-tuning strategies (a traditional supervision strategy and an off-policy reinforcement learning strategy) can calibrate smaller open-source models to compete with pre-trained models 10x their size.