 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Old is GPT?: The HumBEL Framework for Evaluating Language Models using Human Demographic Data
May 24, 2023

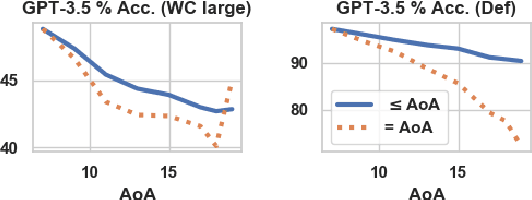

While large pre-trained language models (LMs) find greater use across NLP, existing evaluation protocols do not consider how LM language use aligns with particular human demographic groups, which can be an important consideration in conversational AI applications. To remedy this gap, we consider how LM language skills can be measured and compared to human sub-populations. We suggest clinical techniques from Speech Language Pathology, which has well-established norms for acquisition of language skills, organized by (human) age. We conduct evaluation with a domain expert (i.e., a clinically licensed speech language pathologist), and also propose automated techniques to substitute clinical evaluation at scale. We find LM capability varies widely depending on task with GPT-3.5 mimicking the ability of a typical 6-9 year old at tasks requiring inference about word meanings and simultaneously outperforming a typical 21 year old at memorization. GPT-3.5 (InstructGPT) also has trouble with social language use, exhibiting less than 50\% of the tested pragmatic skills. It shows errors in understanding particular word parts-of-speech and associative word relations, among other lexical features. Ultimately, findings reiterate the importance of considering demographic alignment and conversational goals when using these models as public-facing tools. Our framework will be publicly available via code, data, and a python package.