 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift No More? Context Equilibria in Multi-Turn LLM Interactions
Oct 09, 2025Large Language Models (LLMs) excel at single-turn tasks such as instruction following and summarization, yet real-world deployments require sustained multi-turn interactions where user goals and conversational context persist and evolve. A recurring challenge in this setting is context drift: the gradual divergence of a model's outputs from goal-consistent behavior across turns. Unlike single-turn errors, drift unfolds temporally and is poorly captured by static evaluation metrics. In this work, we present a study of context drift in multi-turn interactions and propose a simple dynamical framework to interpret its behavior. We formalize drift as the turn-wise KL divergence between the token-level predictive distributions of the test model and a goal-consistent reference model, and propose a recurrence model that interprets its evolution as a bounded stochastic process with restoring forces and controllable interventions. We instantiate this framework in both synthetic long-horizon rewriting tasks and realistic user-agent simulations such as in $\tau$-Bench, measuring drift for several open-weight LLMs that are used as user simulators. Our experiments consistently reveal stable, noise-limited equilibria rather than runaway degradation, and demonstrate that simple reminder interventions reliably reduce divergence in line with theoretical predictions. Together, these results suggest that multi-turn drift can be understood as a controllable equilibrium phenomenon rather than as inevitable decay, providing a foundation for studying and mitigating context drift in extended interactions.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
ReSpAct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents
Nov 01, 2024



Large language model (LLM)-based agents have been increasingly used to interact with external environments (e.g., games, APIs, etc.) and solve tasks. However, current frameworks do not enable these agents to work with users and interact with them to align on the details of their tasks and reach user-defined goals; instead, in ambiguous situations, these agents may make decisions based on assumptions. This work introduces ReSpAct (Reason, Speak, and Act), a novel framework that synergistically combines the essential skills for building task-oriented "conversational" agents. ReSpAct addresses this need for agents, expanding on the ReAct approach. The ReSpAct framework enables agents to interpret user instructions, reason about complex tasks, execute appropriate actions, and engage in dynamic dialogue to seek guidance, clarify ambiguities, understand user preferences, resolve problems, and use the intermediate feedback and responses of users to update their plans. We evaluated ReSpAct in environments supporting user interaction, such as task-oriented dialogue (MultiWOZ) and interactive decision-making (AlfWorld, WebShop). ReSpAct is flexible enough to incorporate dynamic user feedback and addresses prevalent issues like error propagation and agents getting stuck in reasoning loops. This results in more interpretable, human-like task-solving trajectories than relying solely on reasoning traces. In two interactive decision-making benchmarks, AlfWorld and WebShop, ReSpAct outperform the strong reasoning-only method ReAct by an absolute success rate of 6% and 4%, respectively. In the task-oriented dialogue benchmark MultiWOZ, ReSpAct improved Inform and Success scores by 5.5% and 3%, respectively.
Simulating User Agents for Embodied Conversational-AI
Oct 31, 2024



Embodied agents designed to assist users with tasks must engage in natural language interactions, interpret instructions, execute actions, and communicate effectively to resolve issues. However, collecting large-scale, diverse datasets of situated human-robot dialogues to train and evaluate such agents is expensive, labor-intensive, and time-consuming. To address this challenge, we propose building a large language model (LLM)-based user agent that can simulate user behavior during interactions with an embodied agent in a virtual environment. Given a user goal (e.g., make breakfast), at each time step, the user agent may observe" the robot actions or speak" to either intervene with the robot or answer questions. Such a user agent assists in improving the scalability and efficiency of embodied dialogues dataset generation and is critical for enhancing and evaluating the robot's interaction and task completion ability, as well as for research in reinforcement learning using AI feedback. We evaluate our user agent's ability to generate human-like behaviors by comparing its simulated dialogues with the TEACh dataset. We perform three experiments: zero-shot prompting to predict dialogue acts, few-shot prompting, and fine-tuning on the TEACh training subset. Results show the LLM-based user agent achieves an F-measure of 42% with zero-shot prompting and 43.4% with few-shot prompting in mimicking human speaking behavior. Through fine-tuning, performance in deciding when to speak remained stable, while deciding what to say improved from 51.1% to 62.5%. These findings showcase the feasibility of the proposed approach for assessing and enhancing the effectiveness of robot task completion through natural language communication.
* 8 pages, 5 figures, 4 tables
From Context to Action: Analysis of the Impact of State Representation and Context on the Generalization of Multi-Turn Web Navigation Agents
Oct 31, 2024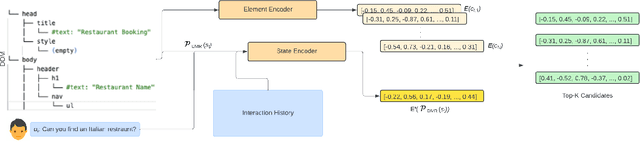
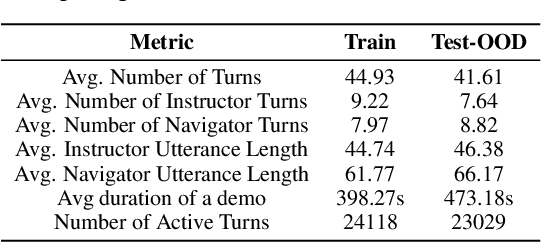
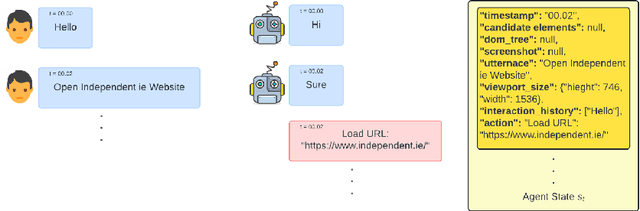
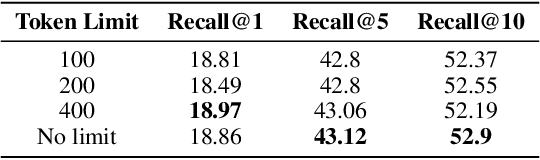
Recent advancements in Large Language Model (LLM)-based frameworks have extended their capabilities to complex real-world applications, such as interactive web navigation. These systems, driven by user commands, navigate web browsers to complete tasks through multi-turn dialogues, offering both innovative opportunities and significant challenges. Despite the introduction of benchmarks for conversational web navigation, a detailed understanding of the key contextual components that influence the performance of these agents remains elusive. This study aims to fill this gap by analyzing the various contextual elements crucial to the functioning of web navigation agents. We investigate the optimization of context management, focusing on the influence of interaction history and web page representation. Our work highlights improved agent performance across out-of-distribution scenarios, including unseen websites, categories, and geographic locations through effective context management. These findings provide insights into the design and optimization of LLM-based agents, enabling more accurate and effective web navigation in real-world applications.
Evaluating Uncertainty Quantification approaches for Neural PDEs in scientific applications
Nov 08, 2023The accessibility of spatially distributed data, enabled by affordable sensors, field, and numerical experiments, has facilitated the development of data-driven solutions for scientific problems, including climate change, weather prediction, and urban planning. Neural Partial Differential Equations (Neural PDEs), which combine deep learning (DL) techniques with domain expertise (e.g., governing equations) for parameterization, have proven to be effective in capturing valuable correlations within spatiotemporal datasets. However, sparse and noisy measurements coupled with modeling approximation introduce aleatoric and epistemic uncertainties. Therefore, quantifying uncertainties propagated from model inputs to outputs remains a challenge and an essential goal for establishing the trustworthiness of Neural PDEs. This work evaluates various Uncertainty Quantification (UQ) approaches for both Forward and Inverse Problems in scientific applications. Specifically, we investigate the effectiveness of Bayesian methods, such as Hamiltonian Monte Carlo (HMC) and Monte-Carlo Dropout (MCD), and a more conventional approach, Deep Ensembles (DE). To illustrate their performance, we take two canonical PDEs: Burger's equation and the Navier-Stokes equation. Our results indicate that Neural PDEs can effectively reconstruct flow systems and predict the associated unknown parameters. However, it is noteworthy that the results derived from Bayesian methods, based on our observations, tend to display a higher degree of certainty in their predictions as compared to those obtained using the DE. This elevated certainty in predictions suggests that Bayesian techniques might underestimate the true underlying uncertainty, thereby appearing more confident in their predictions than the DE approach.