 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould the Road to Grounded, Neuro-symbolic AI be Paved with Words-as-Classifiers?
Jul 08, 2025Formal, Distributional, and Grounded theories of computational semantics each have their uses and their drawbacks. There has been a shift to ground models of language by adding visual knowledge, and there has been a call to enrich models of language with symbolic methods to gain the benefits from formal, distributional, and grounded theories. In this paper, we attempt to make the case that one potential path forward in unifying all three semantic fields is paved with the words-as-classifier model, a model of word-level grounded semantics that has been incorporated into formalisms and distributional language models in the literature, and it has been well-tested within interactive dialogue settings. We review that literature, motivate the words-as-classifiers model with an appeal to recent work in cognitive science, and describe a small experiment. Finally, we sketch a model of semantics unified through words-as-classifiers.
Incremental Dialogue Management: Survey, Discussion, and Implications for HRI
Jan 01, 2025



Efforts towards endowing robots with the ability to speak have benefited from recent advancements in NLP, in particular large language models. However, as powerful as current models have become, they still operate on sentence or multi-sentence level input, not on the word-by-word input that humans operate on, affecting the degree of responsiveness that they offer, which is critical in situations where humans interact with robots using speech. In this paper, we review the literature on interactive systems that operate incrementally (i.e., at the word level or below it). We motivate the need for incremental systems, survey incremental modeling of important aspects of dialogue like speech recognition and language generation. Primary focus is on the part of the system that makes decisions, known as the dialogue manager. We find that there is very little research on incremental dialogue management, offer some requirements for practical incremental dialogue management, and the implications of incremental dialogue for embodied, robotic platforms.
Renaissance: Investigating the Pretraining of Vision-Language Encoders
Nov 11, 2024



In the past several years there has been an explosion of available models for vision-language tasks. Unfortunately, the literature still leaves open a number of questions related to best practices in designing and training such models. In this paper we seek to answer several questions related to the pretraining of vision-language encoders through meta-analysis. In our first set of experiments, we show that we can save significant compute at no cost to downstream performance, by freezing large parts of vision-language models during pretraining. In our second set of experiments we examine the effect of basing a VL transformer on a vision model versus a text model. Additionally, we introduce a VL modeling platform called Renaissance that we use to conduct all of the experiments. This program offers a great deal of flexibility in creating, training and evaluating transformer encoders for VL modeling. The source code for Renaissance can be found at https://github.com/bsu-slim/renaissance.
Unsupervised, Bottom-up Category Discovery for Symbol Grounding with a Curious Robot
Apr 03, 2024



Towards addressing the Symbol Grounding Problem and motivated by early childhood language development, we leverage a robot which has been equipped with an approximate model of curiosity with particular focus on bottom-up building of unsupervised categories grounded in the physical world. That is, rather than starting with a top-down symbol (e.g., a word referring to an object) and providing meaning through the application of predetermined samples, the robot autonomously and gradually breaks up its exploration space into a series of increasingly specific unlabeled categories at which point an external expert may optionally provide a symbol association. We extend prior work by using a robot that can observe the visual world, introducing a higher dimensional sensory space, and using a more generalizable method of category building. Our experiments show that the robot learns categories based on actions and what it visually observes, and that those categories can be symbolically grounded into.https://info.arxiv.org/help/prep#comments
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024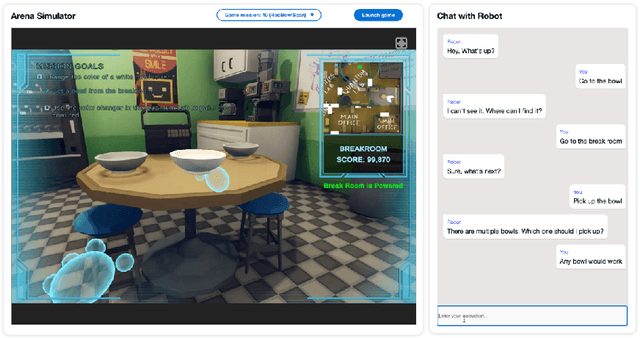
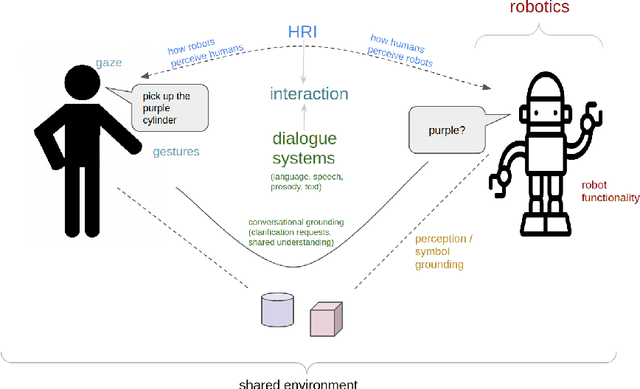
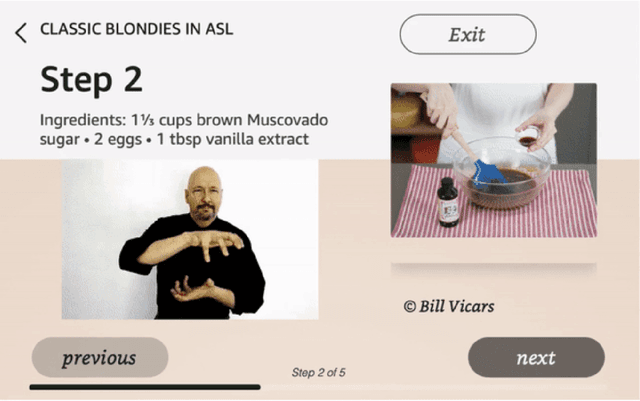
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Understanding Survey Paper Taxonomy about Large Language Models via Graph Representation Learning
Feb 16, 2024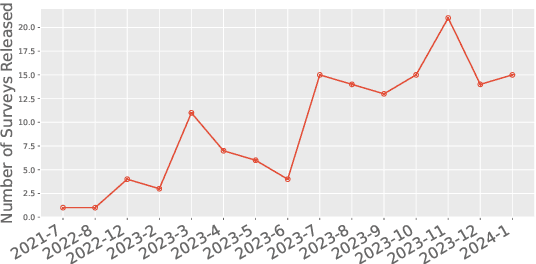

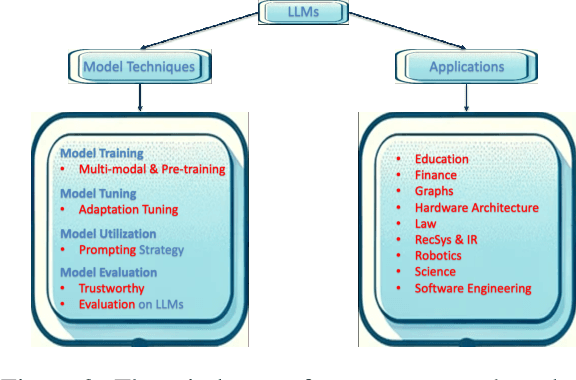
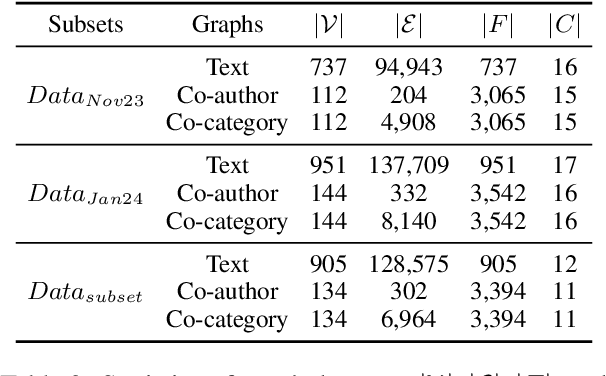
As new research on Large Language Models (LLMs) continues, it is difficult to keep up with new research and models. To help researchers synthesize the new research many have written survey papers, but even those have become numerous. In this paper, we develop a method to automatically assign survey papers to a taxonomy. We collect the metadata of 144 LLM survey papers and explore three paradigms to classify papers within the taxonomy. Our work indicates that leveraging graph structure information on co-category graphs can significantly outperform the language models in two paradigms; pre-trained language models' fine-tuning and zero-shot/few-shot classifications using LLMs. We find that our model surpasses an average human recognition level and that fine-tuning LLMs using weak labels generated by a smaller model, such as the GCN in this study, can be more effective than using ground-truth labels, revealing the potential of weak-to-strong generalization in the taxonomy classification task.
A Multi-Perspective Learning to Rank Approach to Support Children's Information Seeking in the Classroom
Aug 29, 2023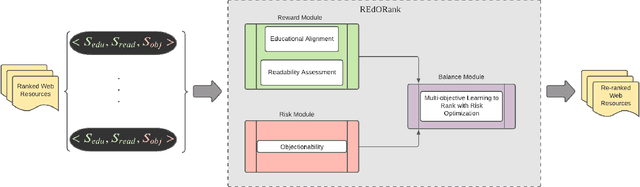
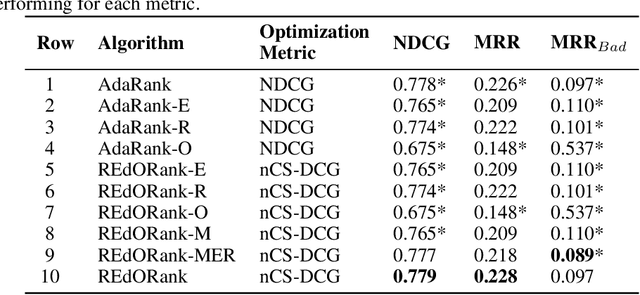
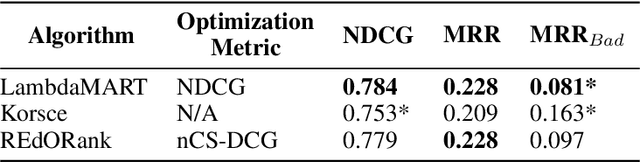
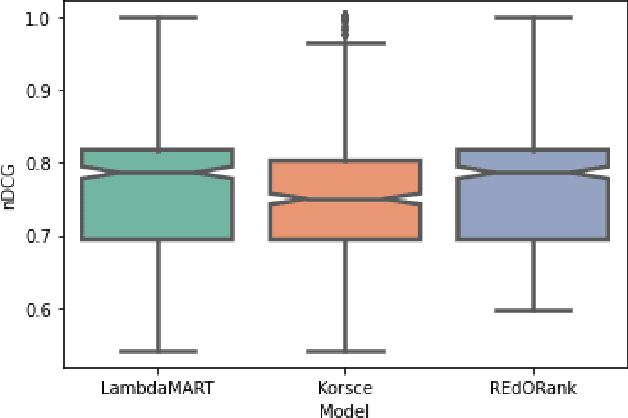
We introduce a novel re-ranking model that aims to augment the functionality of standard search engines to support classroom search activities for children (ages 6 to 11). This model extends the known listwise learning-to-rank framework by balancing risk and reward. Doing so enables the model to prioritize Web resources of high educational alignment, appropriateness, and adequate readability by analyzing the URLs, snippets, and page titles of Web resources retrieved by a given mainstream search engine. Experimental results, including an ablation study and comparisons with existing baselines, showcase the correctness of the proposed model. The outcomes of this work demonstrate the value of considering multiple perspectives inherent to the classroom setting, e.g., educational alignment, readability, and objectionability, when applied to the design of algorithms that can better support children's information discovery.
On the Computational Modeling of Meaning: Embodied Cognition Intertwined with Emotion
Jul 12, 2023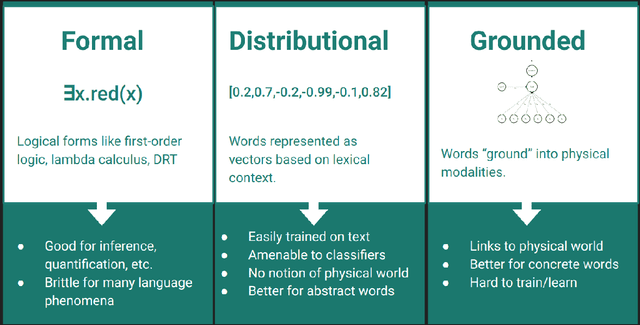
This document chronicles this author's attempt to explore how words come to mean what they do, with a particular focus on child language acquisition and what that means for models of language understanding.\footnote{I say \emph{historical} because I synthesize the ideas based on when I discovered them and how those ideas influenced my later thinking.} I explain the setting for child language learning, how embodiment -- being able to perceive and enact in the world, including knowledge of concrete and abstract concepts -- is crucial, and how emotion and cognition relate to each other and the language learning process. I end with what I think are some of the requirements for a language-learning agent that learns language in a setting similar to that of children. This paper can act as a potential guide for ongoing and future work in modeling language.
Vision Language Transformers: A Survey
Jul 06, 2023



Vision language tasks, such as answering questions about or generating captions that describe an image, are difficult tasks for computers to perform. A relatively recent body of research has adapted the pretrained transformer architecture introduced in \citet{vaswani2017attention} to vision language modeling. Transformer models have greatly improved performance and versatility over previous vision language models. They do so by pretraining models on a large generic datasets and transferring their learning to new tasks with minor changes in architecture and parameter values. This type of transfer learning has become the standard modeling practice in both natural language processing and computer vision. Vision language transformers offer the promise of producing similar advancements in tasks which require both vision and language. In this paper, we provide a broad synthesis of the currently available research on vision language transformer models and offer some analysis of their strengths, limitations and some open questions that remain.
Who's in Charge? Roles and Responsibilities of Decision-Making Components in Conversational Robots
Mar 15, 2023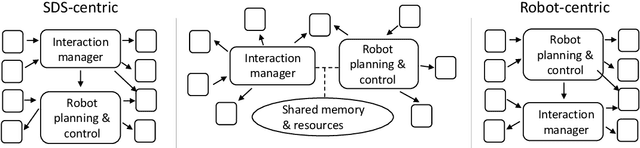
Software architectures for conversational robots typically consist of multiple modules, each designed for a particular processing task or functionality. Some of these modules are developed for the purpose of making decisions about the next action that the robot ought to perform in the current context. Those actions may relate to physical movements, such as driving forward or grasping an object, but may also correspond to communicative acts, such as asking a question to the human user. In this position paper, we reflect on the organization of those decision modules in human-robot interaction platforms. We discuss the relative benefits and limitations of modular vs. end-to-end architectures, and argue that, despite the increasing popularity of end-to-end approaches, modular architectures remain preferable when developing conversational robots designed to execute complex tasks in collaboration with human users. We also show that most practical HRI architectures tend to be either robot-centric or dialogue-centric, depending on where developers wish to place the ``command center'' of their system. While those design choices may be justified in some application domains, they also limit the robot's ability to flexibly interleave physical movements and conversational behaviours. We contend that architectures placing ``action managers'' and ``interaction managers'' on an equal footing may provide the best path forward for future human-robot interaction systems.