 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAra-Best-RQ: Multi Dialectal Arabic SSL
Mar 23, 2026We present Ara-BEST-RQ, a family of self-supervised learning (SSL) models specifically designed for multi-dialectal Arabic speech processing. Leveraging 5,640 hours of crawled Creative Commons speech and combining it with publicly available datasets, we pre-train conformer-based BEST-RQ models up to 600M parameters. Our models are evaluated on dialect identification (DID) and automatic speech recognition (ASR) tasks, achieving state-of-the-art performance on the former while using fewer parameters than competing models. We demonstrate that family-targeted pre-training on Arabic dialects significantly improves downstream performance compared to multilingual or monolingual models trained on non-Arabic data. All models, code, and pre-processed datasets will be publicly released to support reproducibility and further research in Arabic speech technologies.
Polynomial Mixing for Efficient Self-supervised Speech Encoders
Feb 28, 2026State-of-the-art speech-to-text models typically employ Transformer-based encoders that model token dependencies via self-attention mechanisms. However, the quadratic complexity of self-attention in both memory and computation imposes significant constraints on scalability. In this work, we propose a novel token-mixing mechanism, the Polynomial Mixer (PoM), as a drop-in replacement for multi-head self-attention. PoM computes a polynomial representation of the input with linear complexity with respect to the input sequence length. We integrate PoM into a self-supervised speech representation learning framework based on BEST-RQ and evaluate its performance on downstream speech recognition tasks. Experimental results demonstrate that PoM achieves a competitive word error rate compared to full self-attention and other linear-complexity alternatives, offering an improved trade-off between performance and efficiency in time and memory.
A Study of Data Selection Strategies for Pre-training Self-Supervised Speech Models
Jan 28, 2026Self-supervised learning (SSL) has transformed speech processing, yet its reliance on massive pre-training datasets remains a bottleneck. While robustness is often attributed to scale and diversity, the role of the data distribution is less understood. We systematically examine how curated subsets of pre-training data influence Automatic Speech Recognition (ASR) performance. Surprisingly, optimizing for acoustic, speaker, or linguistic diversity yields no clear improvements over random sampling. Instead, we find that prioritizing the longest utterances achieves superior ASR results while using only half the original dataset, reducing pre-training time by 24% on a large corpora. These findings suggest that for pre-training speech SSL models, data length is a more critical factor than either data diversity or overall data quantity for performance and efficiency, offering a new perspective for data selection strategies in SSL speech processing.
Towards Early Prediction of Self-Supervised Speech Model Performance
Jan 10, 2025


In Self-Supervised Learning (SSL), pre-training and evaluation are resource intensive. In the speech domain, current indicators of the quality of SSL models during pre-training, such as the loss, do not correlate well with downstream performance. Consequently, it is often difficult to gauge the final downstream performance in a cost efficient manner during pre-training. In this work, we propose unsupervised efficient methods that give insights into the quality of the pre-training of SSL speech models, namely, measuring the cluster quality and rank of the embeddings of the SSL model. Results show that measures of cluster quality and rank correlate better with downstream performance than the pre-training loss with only one hour of unlabeled audio, reducing the need for GPU hours and labeled data in SSL model evaluation.
An Analysis of Linear Complexity Attention Substitutes with BEST-RQ
Sep 04, 2024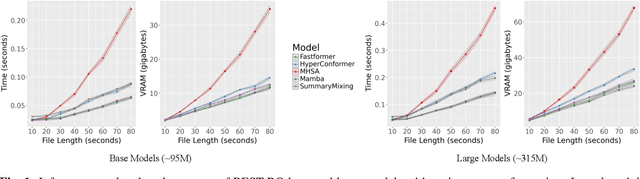
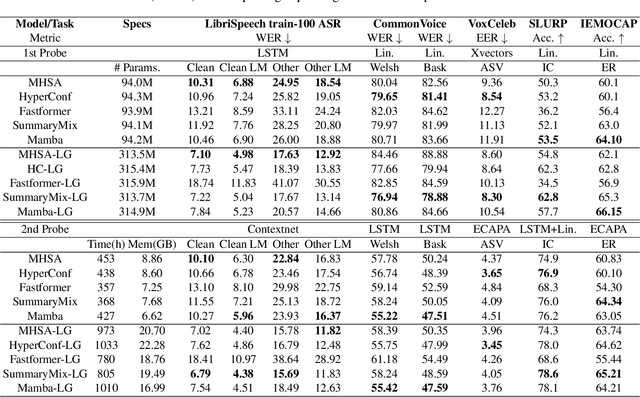
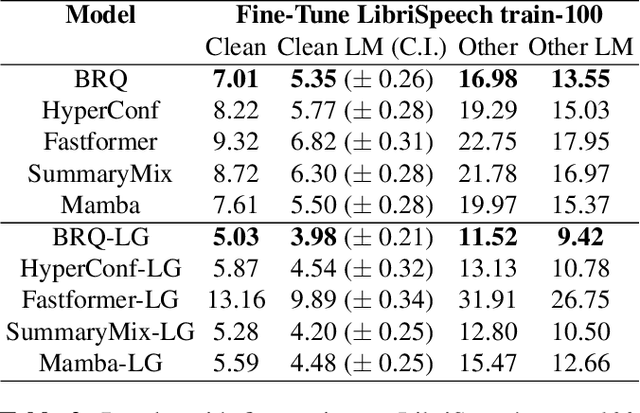
Self-Supervised Learning (SSL) has proven to be effective in various domains, including speech processing. However, SSL is computationally and memory expensive. This is in part due the quadratic complexity of multi-head self-attention (MHSA). Alternatives for MHSA have been proposed and used in the speech domain, but have yet to be investigated properly in an SSL setting. In this work, we study the effects of replacing MHSA with recent state-of-the-art alternatives that have linear complexity, namely, HyperMixing, Fastformer, SummaryMixing, and Mamba. We evaluate these methods by looking at the speed, the amount of VRAM consumed, and the performance on the SSL MP3S benchmark. Results show that these linear alternatives maintain competitive performance compared to MHSA while, on average, decreasing VRAM consumption by around 20% to 60% and increasing speed from 7% to 65% for input sequences ranging from 20 to 80 seconds.
Open Implementation and Study of BEST-RQ for Speech Processing
May 07, 2024Self-Supervised Learning (SSL) has proven to be useful in various speech tasks. However, these methods are generally very demanding in terms of data, memory, and computational resources. BERT-based Speech pre-Training with Random-projection Quantizer (BEST-RQ), is an SSL method that has shown great performance on Automatic Speech Recognition (ASR) while being simpler than other SSL methods, such as wav2vec 2.0. Despite BEST-RQ's great performance, details are lacking in the original paper, such as the amount of GPU/TPU hours used in pre-training, and there is no official easy-to-use open-source implementation. Furthermore, BEST-RQ has not been evaluated on other downstream tasks aside from ASR and speech translation. In this work, we describe a re-implementation of a Random-projection quantizer and perform a preliminary study with a comparison to wav2vec 2.0 on four downstream tasks. We discuss the details and differences of our implementation. We show that a random projection quantizer can achieve similar downstream performance as wav2vec 2.0 while decreasing training time by over a factor of two.
Evaluating Automatic Speech Recognition in an Incremental Setting
Feb 23, 2023The increasing reliability of automatic speech recognition has proliferated its everyday use. However, for research purposes, it is often unclear which model one should choose for a task, particularly if there is a requirement for speed as well as accuracy. In this paper, we systematically evaluate six speech recognizers using metrics including word error rate, latency, and the number of updates to already recognized words on English test data, as well as propose and compare two methods for streaming audio into recognizers for incremental recognition. We further propose Revokes per Second as a new metric for evaluating incremental recognition and demonstrate that it provides insights into overall model performance. We find that, generally, local recognizers are faster and require fewer updates than cloud-based recognizers. Finally, we find Meta's Wav2Vec model to be the fastest, and find Mozilla's DeepSpeech model to be the most stable in its predictions.